






客户推荐语录
阿里云瑶池旗下的云原生数据库PolarDB PostgreSQL版的存储具备弹性扩容能力,最大可支持100TB存储空间。它的大表优化和弹性跨机并行查询(ePQ),成功解决了社区PostgreSQL针对大表的查询和并发更新慢的问题。在小鹏汽车的智能辅助驾驶业务上,实现了每日TB级大数据表的7000万行更新和大数据表秒级分析查询。
——小鹏汽车智能辅助驾驶SRE负责人

1.1 关于小鹏汽车
小鹏汽车是中国领先的智能电动汽车公司,致力于为对技术充满热情的消费者设计、开发、制造和营销智能电动汽车。公司的核心使命是通过科技驱动智能电动汽车的变革,引领未来的出行方式。为了提升客户的驾驶体验,小鹏汽车投入了大量资源自主研发全栈式智能辅助驾驶技术、车载智能操作系统,以及涵盖动力总成和电子电气架构的车辆核心系统。

1.2 业务场景
智能辅助驾驶是小鹏汽车的重点技术方向,每天有海量的图片、视频数据采集上传。有海量的数据存储在对象存储中,同时还需要在关系数据库中针对每个文件生成一条“目录”,以便批量地查找和管理文件,记录文件的位置、属性、指标等。这就导致了这个“目录”要覆盖到全量的数据文件,即数据库的超大单表,并且随着指标的变化要经常进行表的全量数据更新。
2、遭遇瓶颈——海量数据的考验
2.1 大表查询慢
面对海量数据,单机并行处理能力已经达到极限,无法应对TB级大表的查询,小鹏汽车的智能辅助驾驶分析业务承受前所未有的压力。小鹏汽车数据中心最庞大的数据表体量已攀升至7 TB,而超过TB级别的数据表数量更是多达四张。当大表的分析查询时间达到数十分钟甚至数小时时,这一数据处理瓶颈已成为制约智能辅助驾驶业务的关键难题,迫切需要一种新的技术解决方案来破解。
2.2 大表频繁更新
在小鹏汽车的标注业务中,面临着一个日益严峻的问题:TB级大数据表每天的更新量高达7000万行。这一庞大的数据流量引发了一系列的问题,尤其是在TB级大表更新过程中,过多的文件校验作业导致了文件系统的IOPS达到极限,进而导致了系统性能的急剧下降。最终,这种过载使得单行数据更新耗时达到分钟级,进而触发数据库雪崩,对公司的业务运营构成了直接的威胁。
2.3 存储空间快速增长
数据库总容量飙升至30 TB并且以每月2 TB的惊人速度持续增长。社区版的PostgreSQL数据库面临着一个严峻挑战:它无法实现自动化的扩容。这样迅猛增加的存储需求正急剧逼近系统的极限,成为了一个亟待解决的难题。
3、突破僵局——PolarDB的方案
随着数据量越来越大,社区版PostgreSQL遇到性能瓶颈,数据处理链路产生堆积,尤其是数据批量更新更是成为卡点,影响智能辅助驾驶研发效率。针对现状和PostgreSQL生态兼容性考虑推荐客户测试云原生数据库PolarDB PostgreSQL版(PolarDB PostgreSQL版,简称为 PolarDB-PG),在兼容现有业务代码的同时,解决单机数据库的性能瓶颈,提高研发效率:
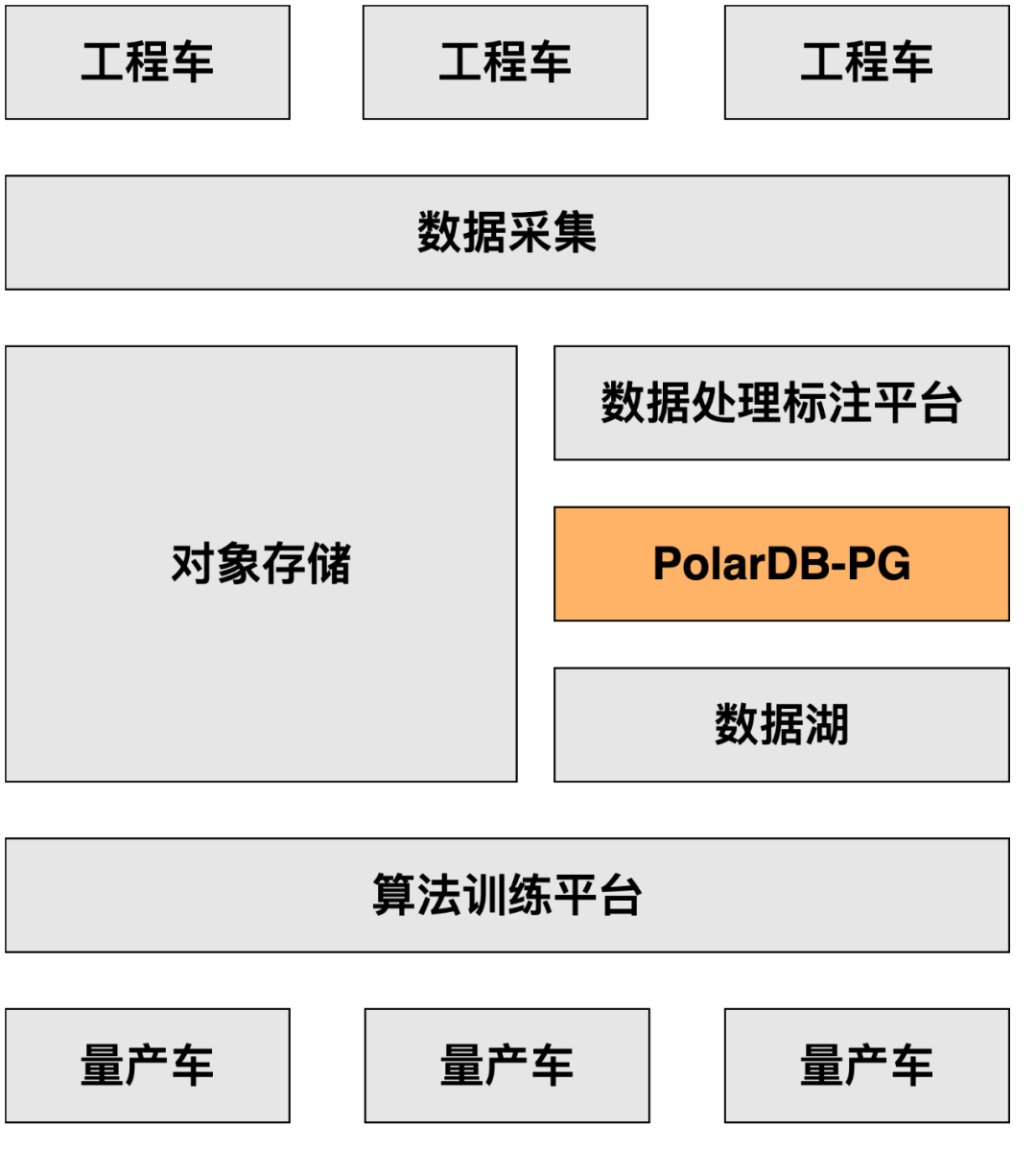
3.1 ePQ加速TB级大表分析查询
ePQ是Elastic Parallel Query(弹性并行查询)的缩写。PolarDB-PG通过ePQ优化器,生成能够被多个计算节点并行执行的执行计划。ePQ的执行引擎将在多个计算节点上协调执行该计划,同时利用多个节点的CPU、内存、I/O带宽来扫描和计算数据。PolarDB-PG ePQ的架构示意图如下所示:
● 极致的分析查询性能:1TB TPC-H测试平均提升23倍性能,性能可随并行度、节点数线性提升。
● 业务完全透明:无须修改任何业务代码,仅需在控制台打开polar_enable_px开关即可使用ePQ。
3.2 大表优化解决大表频繁更新问题
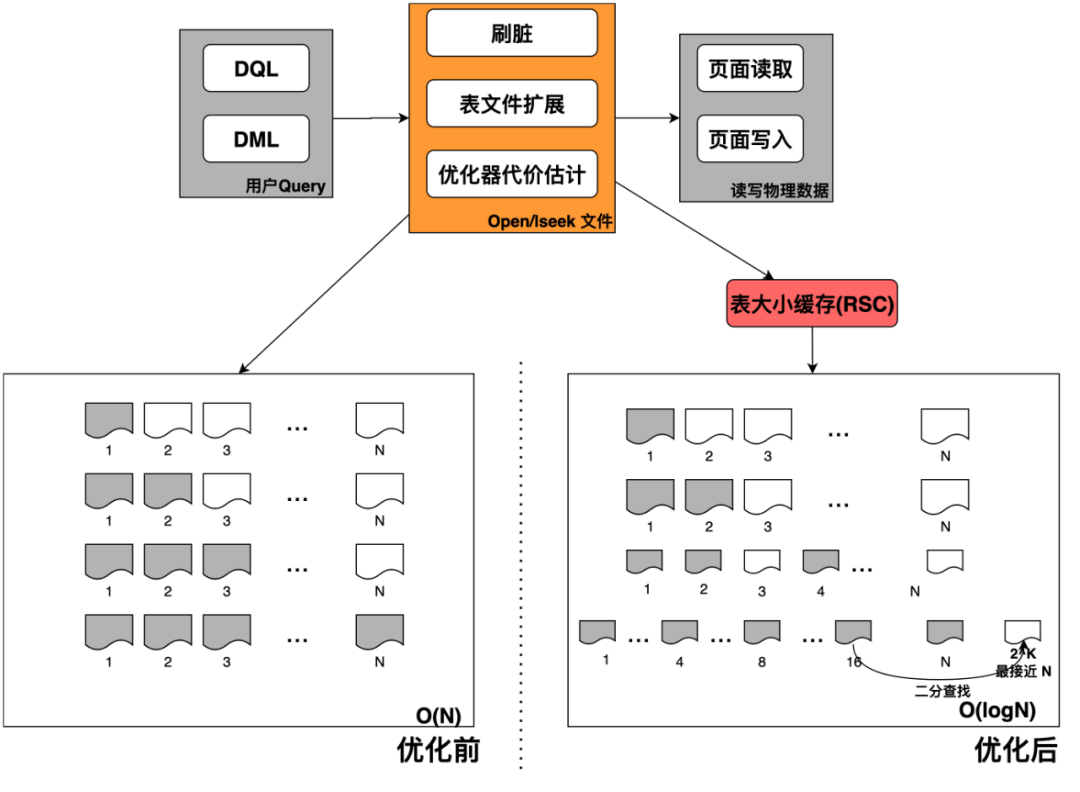
在小鹏汽车的场景下,单表的大小达到TB级别,最大可达到7 TB。业务侧采用短连接 + 高并发(> 400)更新的方式来访问TB级大表。在这种情况下,大表的文件访问操作(例如 open/lseek)会将整个数据库的IOPS打满,IO时延飙升,触发数据库雪崩。
在社区PostgreSQL中,每张表的文件都是以Segment为单位来进行存储,每个Segment大小为1GB。在如下三个场景需要使用open/lseek文件访问操作来获取文件大小:
3. 优化器进行代价估计:优化器在对普通表进行代价估计的时候,需要获取表大小用来判断采用seqscan还是indexscan。获取当前表大小需要逐个open/lseek segment文件。
小鹏汽车智能辅助驾驶场景下, 7 TB的大表意味着7000个Segment文件,每次对大表进行刷脏或者表扩展的时候,单次文件写入操作会被放大成7000个Segment文件长度校验。同时业务侧还是采用短连接 + 高并发的方式访问大表,意味着文件句柄无法缓存,只能采用文件操作(open/lseek)来访问Segment文件长度,最终大表的海量文件访问将整个数据库的IOPS打满,IO时延飙升,触发数据库雪崩。
PolarDB-PG用如下三个方法解决了大表写入问题:
2. 减少冗余文件校验:社区PostgreSQL在刷脏写入一个页面的时候,需要逐个打开之前所有Segment文件计算页面写入位置信息,检查页面写入位置信息正确。PolarDB-PG优化过后,在保证数据正确性的基础上,减少冗余的文件校验,仅获取 SegN-1和SegN两个文件大小。
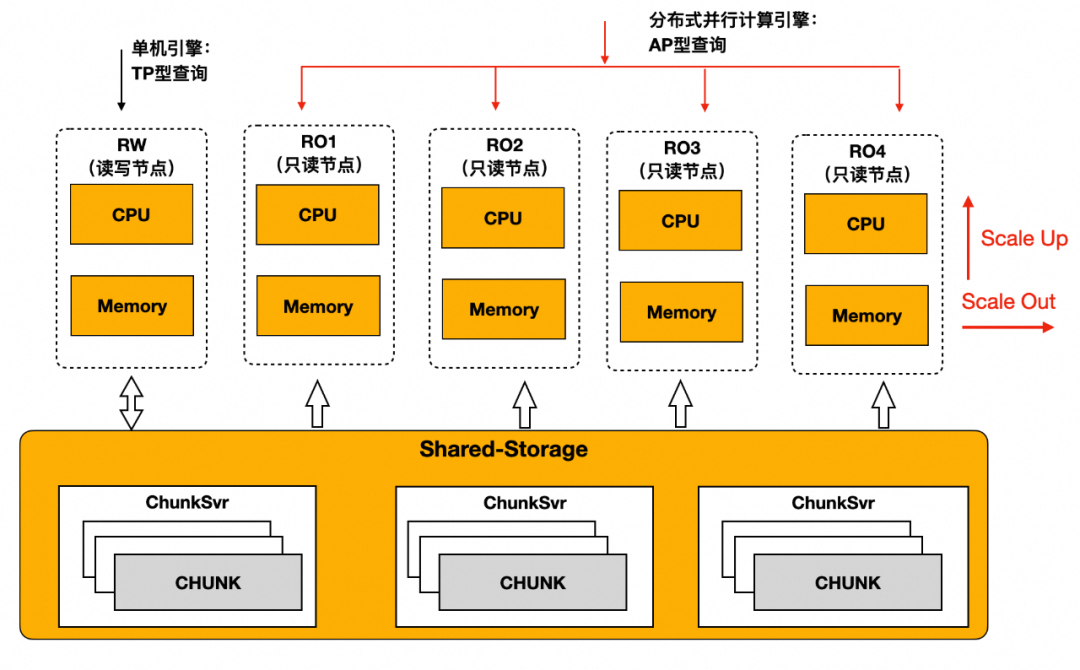
3.3 存算分离实现弹性扩容
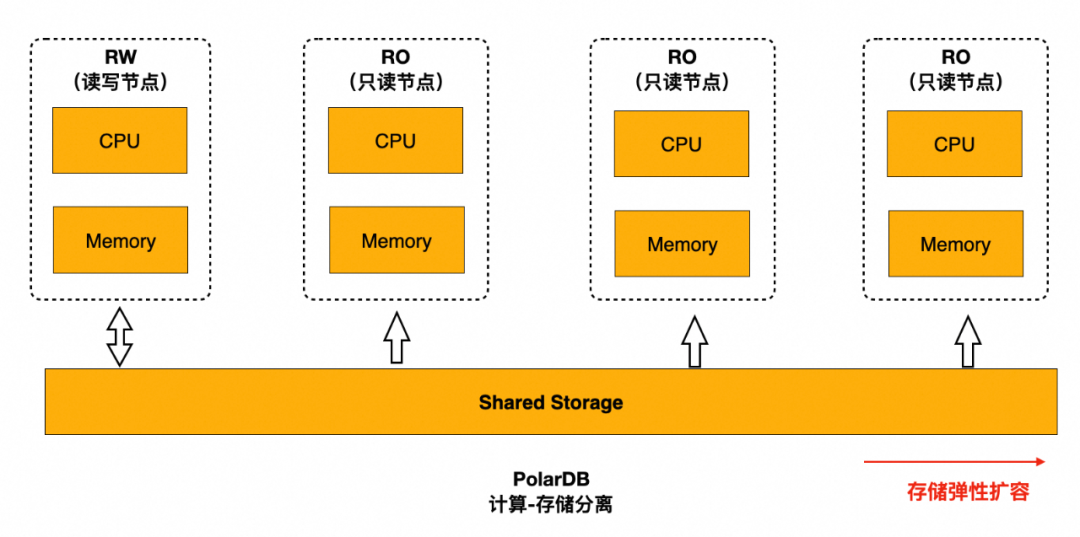
小鹏汽车的PolarDB-PG实例数据量达到30 TB,并且以平均每月2 TB的速度在增长。基于ECS自建的PostgreSQL数据库已无法应对数据增长的需要。
PolarDB-PG基于存储计算分离的架构,PolarStore存储集群可独立扩展,支持弹性扩容,存储按量进行计费,最大支持100 TB存储,PolarStore存储集群的读写带宽稳定在1.6 GB/s以上。大容量 + 高带宽确保PolarDB-PG的 IO 和存储空间不成为瓶颈。
4、迎接转机——系统性能的蝶变
4.1 大表分析查询速度提升3.6倍
以数据统计业务为例,大表(这里简称为 xxx)的表大小为7.6TB,通过如下语句查询:
select count(1) as cnt from xxx where create_time>='2024-03-19 01:00:00' andcreate_time<'2024-03-19 02:00:00';

采用ePQ 2个RO节点,24并发查询,执行时间可降低至18秒。

采用ePQ跨机并行查询相较于单机并行查询速度可提升3.6倍,能达到查询性能随并行度线性提升。再增加只读节点,查询速度仍可继续提升。
4.2 数据等待事件降低至几乎为0
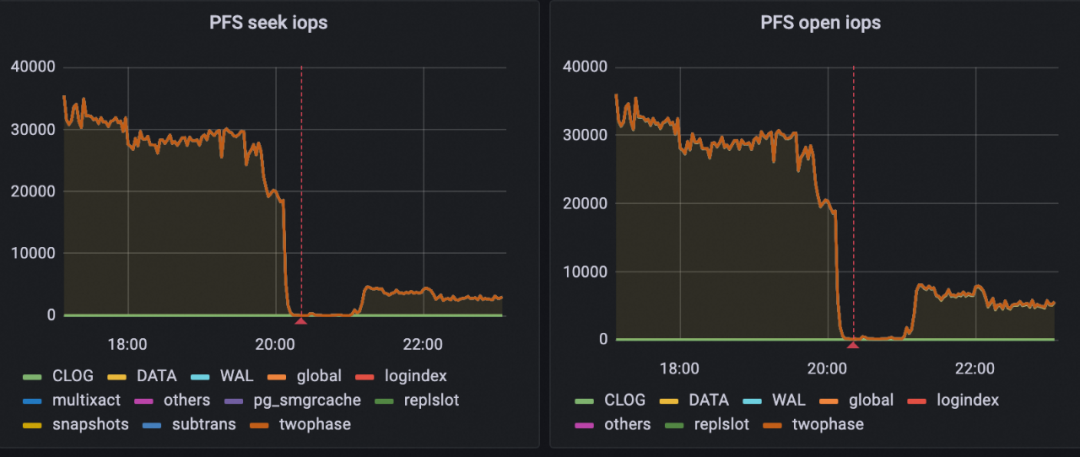
下图展示了文件系统seek和open iops的变化,红线左侧是优化前的表现,红线右侧是优化后的表现。
优化前:整体的open/seek iops达到30000 ~ 40000。
优化后:整体的open/seek iops达到5000 左右,减少80%的iops数量。
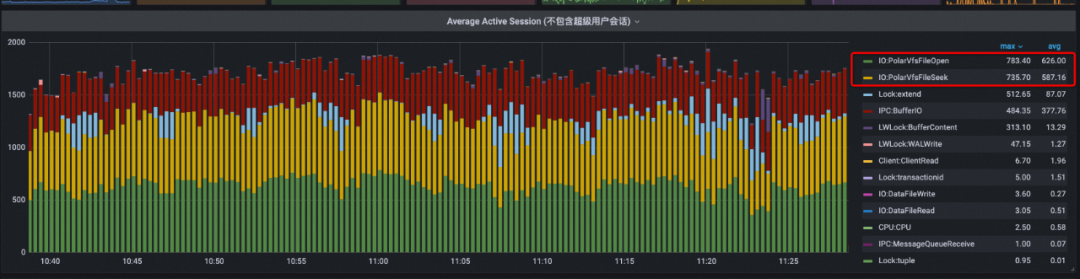
如下图所示,图中的每一项表示数据库在运行过程中的等待事件总量。由原来平均 600+的FileOpen/FileSeek等待事件,优化到后面几乎没有FileOpen/FileSeek等待事件( < 1)。
优化后:

4.3 存算分离实现弹性扩容
下图展示了小鹏客户的总数据量和7天内数据增长量。总数据量达到37 TB级别,数据增长量峰值达到每7天1.5 TB,平均以每月2 TB的速度增长。但PolarDB-PG的存储空间不成为瓶颈。

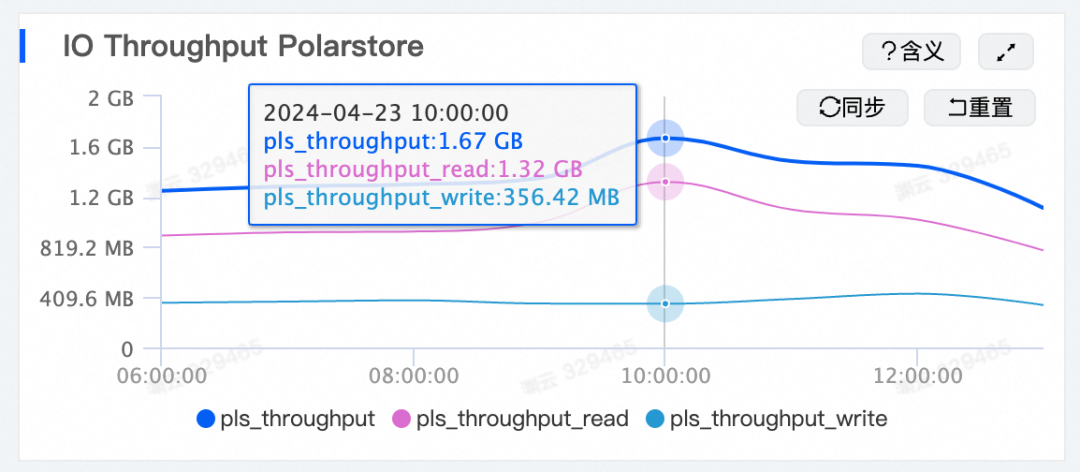
下图展示了小鹏汽车智能辅助驾驶业务在业务高峰期的IO读写带宽,稳定在1.6 GB/s 以上。PolarDB-PG的高读写带宽确保智能辅助驾驶业务在高峰期正常运行。
5. 总结
1. 支持TB级别大表的秒级分析查询;
2. 支持TB级别大表每日7千万的频繁标注更新;
3. 提供100 TB的存储空间、存储弹性自动扩容、按量付费方式;
4. 所有大表优化对业务完全透明,无需业务修改,省去开发和运维负担。




 点击了解 云原生数据库PolarDB PostgreSQL版
点击了解 云原生数据库PolarDB PostgreSQL版