





本文字数:13148;估计阅读时间:33 分钟
审校:庄晓东(魏庄)

Meetup活动
ClickHouse Hangzhou User Group第1届 Meetup 倒计时2天,火热报名中,详见文末海报!

新的一个月意味着新版本的发布!
发布概要
本次ClickHouse 24.4版本包含了13个新功能🎁、16个性能优化🛷、65个bug修复🐛

和往常一样,我们向 24.4 版本中的所有新贡献者表示热烈欢迎!ClickHouse 的受欢迎程度在很大程度上归功于社区的努力。看到社区不断壮大总是令人感到骄傲。
以下是新贡献者的姓名:
Alexey Katsman、Anita Hammer、Arnaud Rocher、Chandre Van Der Westhuizen、Eduard Karacharov、Eliot Hautefeuille、Igor Markelov、Ilya Andreev、Jhonso7393、Joseph Redfern、Josh Rodriguez、Kirill、KrJin、Maciej Bak、Murat Khairulin、Paweł Kudzia、Tristan、dilet6298、loselarry
如果你想知道我们是如何生成这个列表的…… 点这里【https://gist.github.com/gingerwizard/5a9a87a39ba93b422d8640d811e269e9】。
由 Maksim Kita 贡献
SQL:1999引入了递归公共表达式(CTE)用于层次查询,从而将SQL扩展为图灵完备的编程语言。
至今,ClickHouse一直通过利用层次字典来支持层次查询。有了我们新的默认启用的查询分析和优化基础设施,我们终于有了引入了期待已久的强大功能,例如递归CTE。
ClickHouse的递归CTE采用标准的SQL:1999语法,并通过了递归CTE的所有PostgreSQL测试。此外,ClickHouse现在对递归CTE的支持甚至超过了PostgreSQL。在CTE的UNION ALL子句的底部,可以指定多个(任意复杂的)查询,可以多次引用CTE的基表等。
递归CTE可以优雅而简单地解决层次问题。例如,它们可以轻松回答层次数据模型(例如树和图)的可达性问题。
具体来说,递归CTE可以计算关系的传递闭包,这意味着它可以找出所有可能的间接连接。以伦敦地铁的站点连接为例,您可以想象到所有直接相连的地铁站:从牛津街到邦德街,从邦德街到大理石拱门,从大理石拱门到兰开斯特门,等等。这些连接的传递闭包则包含了这些站点之间所有可能的连接,例如:从牛津街到兰开斯特门,从牛津街到大理石拱门,等等。
当从中央线的牛津街站出发时,我们最多可以在五次停靠内到达哪些站点?
我们用中央线站点地图的截图来进行可视化:
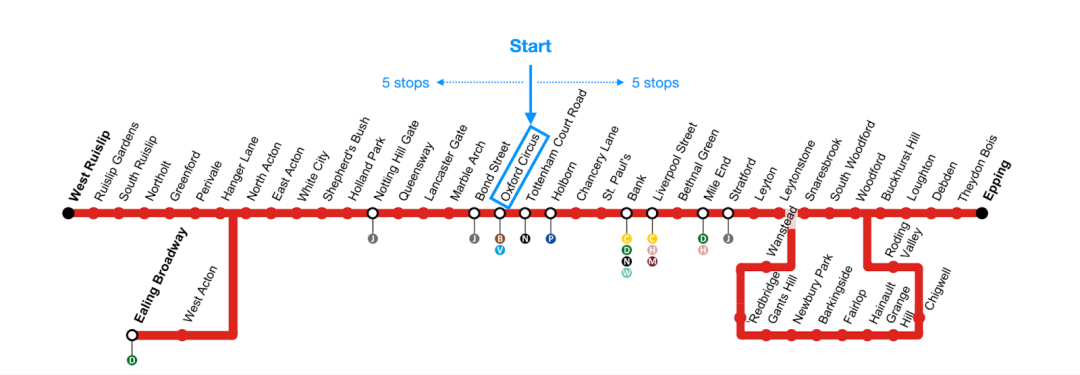
我们为存储伦敦地铁连接数据集创建了一个ClickHouse表:
CREATE OR REPLACE TABLE Connections (Station_1 String,Station_2 String,Line String,PRIMARY KEY(Line, Station_1, Station_2));
值得注意的是,我们在上面的DDL语句中没有指定表引擎(这是自从ClickHouse 24.3之后才可能的),并且在列定义中使用了PRIMARY KEY语法(自从ClickHouse 23.7以来就可行了)。通过这样的设置,不仅我们的递归CTEs,连同我们的ClickHouse表DDL语法也符合SQL的标准。
INSERT INTO ConnectionsSELECT * FROM url('https://datasets-documentation.s3.eu-west-3.amazonaws.com/london_underground/london_connections.csv')
加载后的数据如下所示:
SELECT*FROM ConnectionsWHERE Line = 'Central Line'ORDER BY Station_1, Station_2LIMIT 10;┌─Station_1──────┬─Station_2────────┬─Line─────────┐1. │ Bank │ Liverpool Street │ Central Line │2. │ Bank │ St. Paul's │ Central Line │3. │ Barkingside │ Fairlop │ Central Line │4. │ Barkingside │ Newbury Park │ Central Line │5. │ Bethnal Green │ Liverpool Street │ Central Line │6. │ Bethnal Green │ Mile End │ Central Line │7. │ Bond Street │ Marble Arch │ Central Line │8. │ Bond Street │ Oxford Circus │ Central Line │9. │ Buckhurst Hill │ Loughton │ Central Line │10. │ Buckhurst Hill │ Woodford │ Central Line │└────────────────┴──────────────────┴──────────────┘
接着,我们使用递归CTE来回答上述问题:
WITH RECURSIVE Reachable_Stations AS(SELECT Station_1, Station_2, Line, 1 AS stopsFROM ConnectionsWHERE Line = 'Central Line'AND Station_1 = 'Oxford Circus'UNION ALLSELECT rs.Station_1, c.Station_2, c.Line, rs.stops + 1 AS stopsFROM Reachable_Stations AS rs, Connections AS cWHERE rs.Line = c.LineAND rs.Station_2 = c.Station_1AND rs.stops < 5)SELECT DISTINCT (Station_1, Station_2, stops) AS connectionsFROM Reachable_StationsORDER BY stops ASC;
结果如下所示:
┌─connections────────────────────────────────┐1. │ ('Oxford Circus','Bond Street',1) │2. │ ('Oxford Circus','Tottenham Court Road',1) │3. │ ('Oxford Circus','Marble Arch',2) │4. │ ('Oxford Circus','Oxford Circus',2) │5. │ ('Oxford Circus','Holborn',2) │6. │ ('Oxford Circus','Bond Street',3) │7. │ ('Oxford Circus','Lancaster Gate',3) │8. │ ('Oxford Circus','Tottenham Court Road',3) │9. │ ('Oxford Circus','Chancery Lane',3) │10. │ ('Oxford Circus','Marble Arch',4) │11. │ ('Oxford Circus','Oxford Circus',4) │12. │ ('Oxford Circus','Queensway',4) │13. │ ('Oxford Circus','Holborn',4) │14. │ ('Oxford Circus','St. Paul\'s',4) │15. │ ('Oxford Circus','Bond Street',5) │16. │ ('Oxford Circus','Lancaster Gate',5) │17. │ ('Oxford Circus','Tottenham Court Road',5) │18. │ ('Oxford Circus','Notting Hill Gate',5) │19. │ ('Oxford Circus','Chancery Lane',5) │20. │ ('Oxford Circus','Bank',5) │└────────────────────────────────────────────┘
递归CTE具有简单的迭代执行逻辑,类似于递归的自我连接,一直连接下去,直到找不到新的连接伙伴或满足中止条件。因此,我们上面的CTE首先执行UNION ALL子句的顶部部分,查询我们的Connections表,找到所有直接连接到中央线上的牛津街站的站点。这将返回一个表,它绑定到Reachable_Stations标识符,并且看起来像这样:
Initial Reachable_Stations table content┌─Station_1─────┬─Station_2────────────┐│ Oxford Circus │ Bond Street ││ Oxford Circus │ Tottenham Court Road │└───────────────┴──────────────────────┘
从现在开始,只有CTE的UNION ALL子句的底部部分将被执行(递归执行):
将Reachable_Stations与Connections表连接,找到那些在Connections表中的Station_1值与Reachable_Stations的Station_2值匹配的连接伙伴。
Connections table join partners┌─Station_1────────────┬─Station_2─────┐│ Bond Street │ Marble Arch ││ Bond Street │ Oxford Circus ││ Tottenham Court Road │ Holborn ││ Tottenham Court Road │ Oxford Circus │└──────────────────────┴───────────────┘
通过UNION ALL子句,这些连接伙伴被添加到Reachable_Stations表中,标记了递归CTE的第一次迭代的完成。在接下来的迭代中,我们执行CTE的UNION ALL子句的底部部分,继续将Reachable_Stations与Connections表连接,以识别(并添加到Reachable_Stations中)所有在Connections表中的Station_1值与Reachable_Stations的Station_2值匹配的新连接伙伴。这些迭代将持续进行,直到找不到新的连接伙伴或满足停止条件。在我们的查询中,我们使用一个停靠计数器来在达到从起始站点允许的停靠数时中止CTE的迭代循环。
需要注意的是,结果中将牛津街站列为从牛津街站到达的站点,分别需要2和4次停靠。这在理论上是正确的,但并不是非常实际,这是因为我们的查询不考虑任何方向或循环。我们把这留给读者作为一个有趣的练习。
作为一个附加问题,我们感兴趣的是从中央线的牛津街站到达斯特拉特福站需要多少次停靠。我们再次用中央线地图来可视化这个问题:
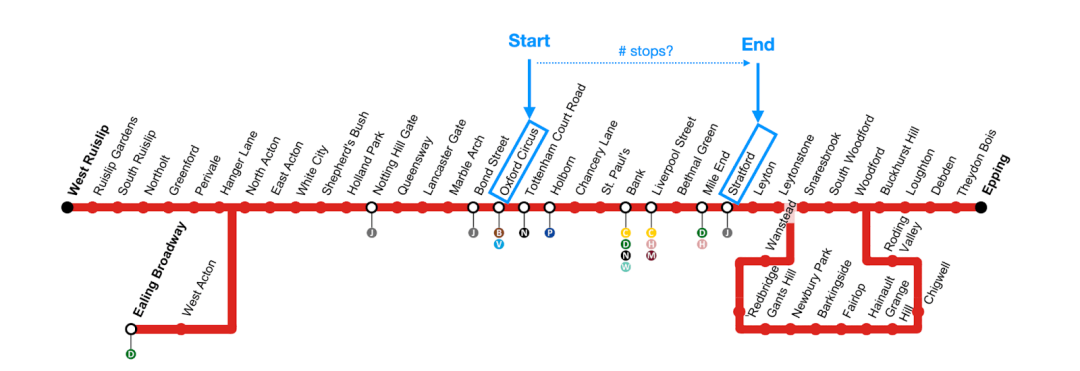
为此,我们只需修改递归CTE的中止条件(一旦添加了具有Stratford作为目标站点的连接伙伴到CTE表中,就停止CTE的连接迭代):
WITH RECURSIVE Reachable_Stations AS(SELECT Station_1, Station_2, Line, 1 AS stopsFROM ConnectionsWHERE Line = 'Central Line'AND Station_1 = 'Oxford Circus'UNION ALLSELECT rs.Station_1 c.Station_2, c.Line, rs.stops + 1 AS stopsFROM Reachable_Stations AS rs, Connections AS cWHERE rs.Line = c.LineAND rs.Station_2 = c.Station_1AND 'Stratford' NOT IN (SELECT Station_2 FROM Reachable_Stations))SELECT max(stops) as stopsFROM Reachable_Stations;
结果显示,从牛津街站到达斯特拉特福站需要9次停靠,与上述中央线地图计划相匹配。
┌─stops─┐1. │ 9 │└───────┘
递归CTE可以轻松回答关于这个数据集的更有趣的问题。例如,原始版本数据集中的相对连接时间可以用来找出从牛津街站到希思罗机场站的最快连接(跨越地铁线)。敬请期待在单独的后续文章中解决这个问题。
由 Maksim Kita 贡献
这个版本新增的另一个功能是QUALIFY子句,它允许我们根据窗口函数的值进行筛选。
我们将通过窗口函数 - 排名示例来演示如何使用它。数据集包含假设的足球运动员及其薪水。我们可以像这样将其导入到ClickHouse中:
CREATE TABLE salaries ORDER BY team ASFROM url('https://raw.githubusercontent.com/ClickHouse/examples/main/LearnClickHouseWithMark/WindowFunctions-Aggregation/data/salaries.csv')SELECT * EXCEPT (weeklySalary), weeklySalary AS salarySETTINGS schema_inference_make_columns_nullable=0;
让我们快速查看薪水表中的数据:
SELECT * FROM salaries LIMIT 5;
┌─team──────────────┬─player───────────┬─position─┬─salary─┐1. │ Aaronbury Seekers │ David Morton │ D │ 63014 │2. │ Aaronbury Seekers │ Edwin Houston │ D │ 51751 │3. │ Aaronbury Seekers │ Stephen Griffith │ M │ 181825 │4. │ Aaronbury Seekers │ Douglas Clay │ F │ 73436 │5. │ Aaronbury Seekers │ Joel Mendoza │ D │ 257848 │└───────────────────┴──────────────────┴──────────┴────────┘
接下来,让我们计算每个球员所在位置的薪水排名。即,他们相对于在同一位置上踢球的人来说薪水有多少?
SELECT player, team, position AS pos, salary,rank() OVER (PARTITION BY position ORDER BY salary DESC) AS posRankFROM salariesORDER BY salary DESCLIMIT 5
┌─player──────────┬─team────────────────────┬─pos─┬─salary─┬─posRank─┐1. │ Robert Griffin │ North Pamela Trojans │ GK │ 399999 │ 1 │2. │ Scott Chavez │ Maryhaven Generals │ M │ 399998 │ 1 │3. │ Dan Conner │ Michaelborough Rogues │ M │ 399998 │ 1 │4. │ Nathan Thompson │ Jimmyville Legionnaires │ D │ 399998 │ 1 │5. │ Benjamin Cline │ Stephaniemouth Trojans │ D │ 399998 │ 1 │└─────────────────┴─────────────────────────┴─────┴────────┴─────────┘
假设我们想要通过位置排名(posRank)来筛选出薪水最高的前3名球员。我们可能会尝试添加一个WHERE子句来实现这一目标:
SELECT player, team, position AS pos, salary,rank() OVER (PARTITION BY position ORDER BY salary DESC) AS posRankFROM salariesWHERE posRank <= 3ORDER BY salary DESCLIMIT 5
Received exception:Code: 184. DB::Exception: Window function rank() OVER (PARTITION BY position ORDER BY salary DESC) AS posRank is found in WHERE in query. (ILLEGAL_AGGREGATION)
但由于WHERE子句在窗口函数评估之前运行,这样是行不通的。在24.4版本发布之前,我们可以通过引入CTE来绕过这个问题:
WITH salaryRankings AS(SELECT player,if(length(team) <=25,team,concat(substring(team, 5), 1, '...')) AS team,position AS pos, salary,rank() OVER (PARTITION BY positionORDER BY salary DESC) AS posRankFROM salariesORDER BY salary DESC)SELECT *FROM salaryRankingsWHERE posRank <= 3
┌─player────────────┬─team────────────────────┬─pos─┬─salary─┬─posRank─┐1. │ Robert Griffin │ North Pamela Trojans │ GK │ 399999 │ 1 │2. │ Scott Chavez │ Maryhaven Generals │ M │ 399998 │ 1 │3. │ Dan Conner │ Michaelborough Rogue... │ M │ 399998 │ 1 │4. │ Benjamin Cline │ Stephaniemouth Troja... │ D │ 399998 │ 1 │5. │ Nathan Thompson │ Jimmyville Legionnai... │ D │ 399998 │ 1 │6. │ William Rubio │ Nobleview Sages │ M │ 399997 │ 3 │7. │ Juan Bird │ North Krystal Knight... │ GK │ 399986 │ 2 │8. │ John Lewis │ Andreaberg Necromanc... │ D │ 399985 │ 3 │9. │ Michael Holloway │ Alyssaborough Sages │ GK │ 399984 │ 3 │10. │ Larry Buchanan │ Eddieshire Discovere... │ F │ 399973 │ 1 │11. │ Alexis Valenzuela │ Aaronport Crusaders │ F │ 399972 │ 2 │12. │ Mark Villegas │ East Michaelborough ... │ F │ 399972 │ 2 │└───────────────────┴─────────────────────────┴─────┴────────┴─────────┘
尽管这个查询是有效的,但它相当繁琐。现在有了QUALIFY子句,我们可以在不需要引入CTE的情况下筛选数据,如下所示:
SELECT player, team, position AS pos, salary,rank() OVER (PARTITION BY position ORDER BY salary DESC) AS posRankFROM salariesQUALIFY posRank <= 3ORDER BY salary DESC;
接着,我们将得到和以前相同的结果。
由 Maksim Kita 贡献
此外,针对某些特定的JOIN使用情况,还进行了一些性能改进。
首先是谓词下推的改进,即分析器确定筛选条件可以应用于JOIN的两侧时的优化。
让我们通过一个示例来说明,我们使用The OpenSky数据集,该数据集包含2019年至2021年的航空数据。我们想要获取经过旧金山的十次航班的列表,可以使用以下查询来实现:
SELECTl.origin,r.destination AS dest,firstseen,lastseenFROM opensky AS lINNER JOIN opensky AS r ON l.destination = r.originWHERE notEmpty(l.origin) AND notEmpty(r.destination) AND (r.origin = 'KSFO')LIMIT 10SETTINGS optimize_move_to_prewhere = 0
为了避免ClickHouse执行另一项优化,我们禁用了optimize_move_to_prewhere,这样我们就能看到JOIN改进带来的好处。如果我们在24.3上运行此查询,结果将如下所示:
┌─origin─┬─dest─┬───────────firstseen─┬────────────lastseen─┐1. │ 00WA │ 00CL │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │2. │ 00WA │ ZGGG │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │3. │ 00WA │ ZGGG │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │4. │ 00WA │ ZGGG │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │5. │ 00WA │ ZGGG │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │6. │ 00WA │ ZGGG │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │7. │ 00WA │ ZGGG │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │8. │ 00WA │ YSSY │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │9. │ 00WA │ YSSY │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │10. │ 00WA │ YSSY │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │└────────┴──────┴─────────────────────┴─────────────────────┘10 rows in set. Elapsed: 0.656 sec. Processed 15.59 million rows, 451.90 MB (23.75 million rows/s., 688.34 MB/s.)Peak memory usage: 62.79 MiB.
让我们看看 24.4 的表现:
┌─origin─┬─dest─┬───────────firstseen─┬────────────lastseen─┐1. │ 00WA │ 00CL │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │2. │ 00WA │ ZGGG │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │3. │ 00WA │ ZGGG │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │4. │ 00WA │ ZGGG │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │5. │ 00WA │ ZGGG │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │6. │ 00WA │ ZGGG │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │7. │ 00WA │ ZGGG │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │8. │ 00WA │ YSSY │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │9. │ 00WA │ YSSY │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │10. │ 00WA │ YSSY │ 2019-10-14 21:03:19 │ 2019-10-14 22:42:01 │└────────┴──────┴─────────────────────┴─────────────────────┘10 rows in set. Elapsed: 0.079 sec.
查询速度提升了约8倍。如果我们通过SELECT *返回所有列,那么在24.3中,此查询所花费的时间会增加到超过4秒,在24.4中则为0.4秒,这是一个10倍的改进。
让我们来看看为什么查询更快。其中两行很关键:
INNER JOIN opensky AS r ON l.destination = r.originWHERE notEmpty(l.origin) AND notEmpty(r.destination) AND (r.origin = 'KSFO')
我们WHERE子句的最后一个条件是r.origin = 'KSFO'。在上一行中,我们指定只有当l.destination = r.origin时才进行连接,这意味着l.destination也必须是'KSFO'。24.4版本中的分析器知道这一点,因此可以更早地过滤掉很多行。
换句话说,在24.4中,我们的WHERE子句实际上是这样的
INNER JOIN opensky AS r ON l.destination = r.originWHERE notEmpty(l.origin) AND notEmpty(r.destination)AND (r.origin = 'KSFO') AND (l.destination = 'KSFO')
第二个改进是,如果JOIN后的谓词过滤掉任何未连接的行,分析器现在会自动将OUTER JOIN转换为INNER JOIN。
举个例子,假设我们最初编写了一个查询来查找旧金山和纽约之间的航班,捕捉直达航班和有中转的航班。
SELECTl.origin,l.destination,r.destination,registration,l.callsign,r.callsignFROM opensky AS lLEFT JOIN opensky AS r ON l.destination = r.originWHERE notEmpty(l.destination)AND (l.origin = 'KSFO')AND (r.destination = 'KJFK')LIMIT 10
后来我们添加了一个额外的过滤器,只返回r.callsign = 'AAL1424'的行。
SELECTl.origin,l.destination AS leftDest,r.destination AS rightDest,registration AS reg,l.callsign,r.callsignFROM opensky AS lLEFT JOIN opensky AS r ON l.destination = r.originWHERE notEmpty(l.destination)AND (l.origin = 'KSFO')AND (r.destination = 'KJFK')AND (r.callsign = 'AAL1424')LIMIT 10SETTINGS optimize_move_to_prewhere = 0
由于现在要求JOIN右侧的callsign列具有值,LEFT JOIN可以转换为INNER JOIN。让我们来看看在24.3和24.4中查询性能的变化。
24.3
┌─origin─┬─leftDest─┬─rightDest─┬─reg────┬─callsign─┬─r.callsign─┐1. │ KSFO │ 01FA │ KJFK │ N12221 │ UAL423 │ AAL1424 │2. │ KSFO │ 01FA │ KJFK │ N12221 │ UAL423 │ AAL1424 │3. │ KSFO │ 01FA │ KJFK │ N12221 │ UAL423 │ AAL1424 │4. │ KSFO │ 01FA │ KJFK │ N12221 │ UAL423 │ AAL1424 │5. │ KSFO │ 01FA │ KJFK │ N12221 │ UAL423 │ AAL1424 │6. │ KSFO │ 01FA │ KJFK │ N87527 │ UAL423 │ AAL1424 │7. │ KSFO │ 01FA │ KJFK │ N87527 │ UAL423 │ AAL1424 │8. │ KSFO │ 01FA │ KJFK │ N87527 │ UAL423 │ AAL1424 │9. │ KSFO │ 01FA │ KJFK │ N87527 │ UAL423 │ AAL1424 │10. │ KSFO │ 01FA │ KJFK │ N87527 │ UAL423 │ AAL1424 │└────────┴──────────┴───────────┴────────┴──────────┴────────────┘10 rows in set. Elapsed: 1.937 sec. Processed 63.98 million rows, 2.52 GB (33.03 million rows/s., 1.30 GB/s.)Peak memory usage: 2.84 GiB.
┌─origin─┬─leftDest─┬─rightDest─┬─reg────┬─callsign─┬─r.callsign─┐1. │ KSFO │ 01FA │ KJFK │ N12221 │ UAL423 │ AAL1424 │2. │ KSFO │ 01FA │ KJFK │ N12221 │ UAL423 │ AAL1424 │3. │ KSFO │ 01FA │ KJFK │ N12221 │ UAL423 │ AAL1424 │4. │ KSFO │ 01FA │ KJFK │ N12221 │ UAL423 │ AAL1424 │5. │ KSFO │ 01FA │ KJFK │ N12221 │ UAL423 │ AAL1424 │6. │ KSFO │ 01FA │ KJFK │ N87527 │ UAL423 │ AAL1424 │7. │ KSFO │ 01FA │ KJFK │ N87527 │ UAL423 │ AAL1424 │8. │ KSFO │ 01FA │ KJFK │ N87527 │ UAL423 │ AAL1424 │9. │ KSFO │ 01FA │ KJFK │ N87527 │ UAL423 │ AAL1424 │10. │ KSFO │ 01FA │ KJFK │ N87527 │ UAL423 │ AAL1424 │└────────┴──────────┴───────────┴────────┴──────────┴────────────┘10 rows in set. Elapsed: 0.762 sec. Processed 23.22 million rows, 939.75 MB (30.47 million rows/s., 1.23 GB/s.)Peak memory usage: 9.00 MiB.
在24.4中,查询速度快了将近三倍。
如果您想了解JOIN性能改进是如何实现的,请阅读Maksim Kita的博客文章,他详细解释了所有内容。
关于24.4版本的内容就介绍到这里。我们邀请您参加5月30日举行的24.5版本发布会。请确保注册,这样您就能收到Zoom网络研讨会的所有详情。【https://clickhouse.com/company/events/v24-5-community-release-call】

好消息:ClickHouse Hangzhou User Group第1届 Meetup ,将于本周六5月18日在杭州市余杭区阿里巴巴西溪园区A区举行,扫码免费报名

征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


