





本文字数:5923;估计阅读时间:15 分钟
审校:庄晓东(魏庄)

这原本是转发的ensemble analytics的文章。 【https://ensembleanalytics.io/blog/linear-regression-using-clickhouse】

本文是Ensemble的系列文章的一部分,本文将研究在ClickHouse中进行数据科学工作。这个系列文章包括:预测、异常检测、线性回归和时间序列分类等内容。
尽管这种类型的分析通常会在ClickHouse之外的编程语言(如Python或R)中进行,但我们更愿意尽可能地仅使用数据库来直接实现某些功能。
通过这样做,我们可以发挥 ClickHouse处理大规模数据集的高性能,并减少,甚至完全避免额外编写的代码的需要。这还意味着:我们可以在客户端使用较小的内存数据集,潜在地避免使用诸如Spark等框架进行分布式计算的需要。
可以在这里找到完整示例的notebook示例代码【https://app.hex.tech/d83ae9cc-7cbe-40f3-9899-0c348f283047/hex/9206f58c-0bde-4dae-94d7-aa9379773d84/draft/logic】。
在本文中,我们将进行简单的线性回归分析,用于两个变量 (交付距离和包裹交付时间)来预测包裹交付的时间。
我们将在分析的过程中,使用和展示地理数据,例如利用Clickhouse的geoDistance函数按地理坐标计算距离。
我们的数据集是Hugging Face的这个最后一英里交付数据集【https://huggingface.co/datasets/Cainiao-AI/LaDe】的一小部分。
尽管整个数据集的庞大而详细,但我们将查看由单一快递员(编号75号)在中国吉林市第53区交付的2,293个订单作为子集,以便更容易地学习本示例。
下面显示了数据的预览。我们只使用包含快递员取件和交付时间和位置的列,以及订单ID。
SELECT *FROM deliveriesLIMIT 5┌─order_id─┬─────accept_gps_time─┬─accept_gps_lat─┬─accept_gps_lng─┬───delivery_gps_time─┬─delivery_gps_lat─┬─delivery_gps_lng─┐│ 7350 │ 2022-07-15 08:45:00 │ 43.81204 │ 126.5669 │ 2022-07-15 13:38:00 │ 43.83002 │ 126.5517 ││ 7540 │ 2022-07-21 08:27:00 │ 43.81219 │ 126.56692 │ 2022-07-21 14:27:00 │ 43.82541 │ 126.55379 ││ 7660 │ 2022-08-30 08:30:00 │ 43.81199 │ 126.56993 │ 2022-08-30 13:52:00 │ 43.82757 │ 126.55321 ││ 8542 │ 2022-08-19 09:09:00 │ 43.81219 │ 126.56689 │ 2022-08-19 15:59:00 │ 43.83033 │ 126.55078 ││ 12350 │ 2022-08-05 08:52:00 │ 43.81215 │ 126.56693 │ 2022-08-05 09:10:00 │ 43.81307 │ 126.56889 │└──────────┴─────────────────────┴────────────────┴────────────────┴─────────────────────┴──────────────────┴──────────────────┘5 rows in set. Elapsed: 0.030 sec. Processed 2.29 thousand rows, 64.18 KB (75.64 thousand rows/s., 2.12 MB/s.)Peak memory usage: 723.95 KiB.
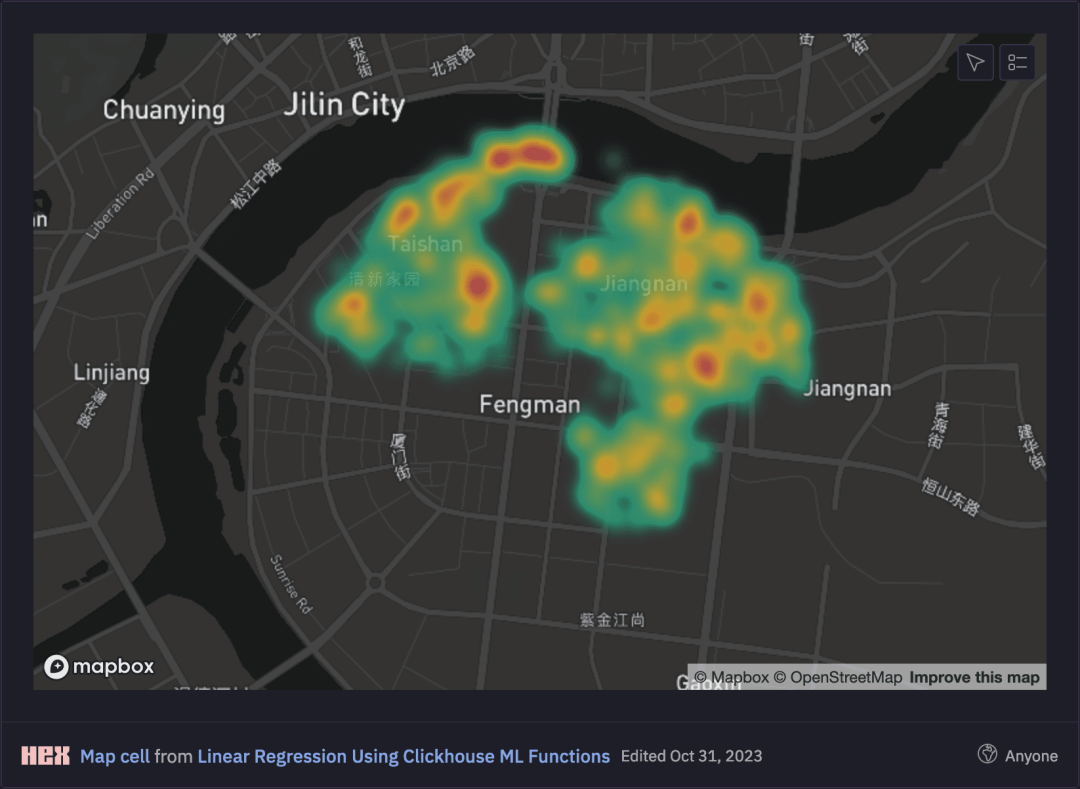
利用我们的Hex Notebook【https://app.hex.tech/d83ae9cc-7cbe-40f3-9899-0c348f283047/hex/9206f58c-0bde-4dae-94d7-aa9379773d84/draft/logic】,我们可以轻松地绘制吉林周围交付位置的热力图,观察到交付集中发生在市中心地区:
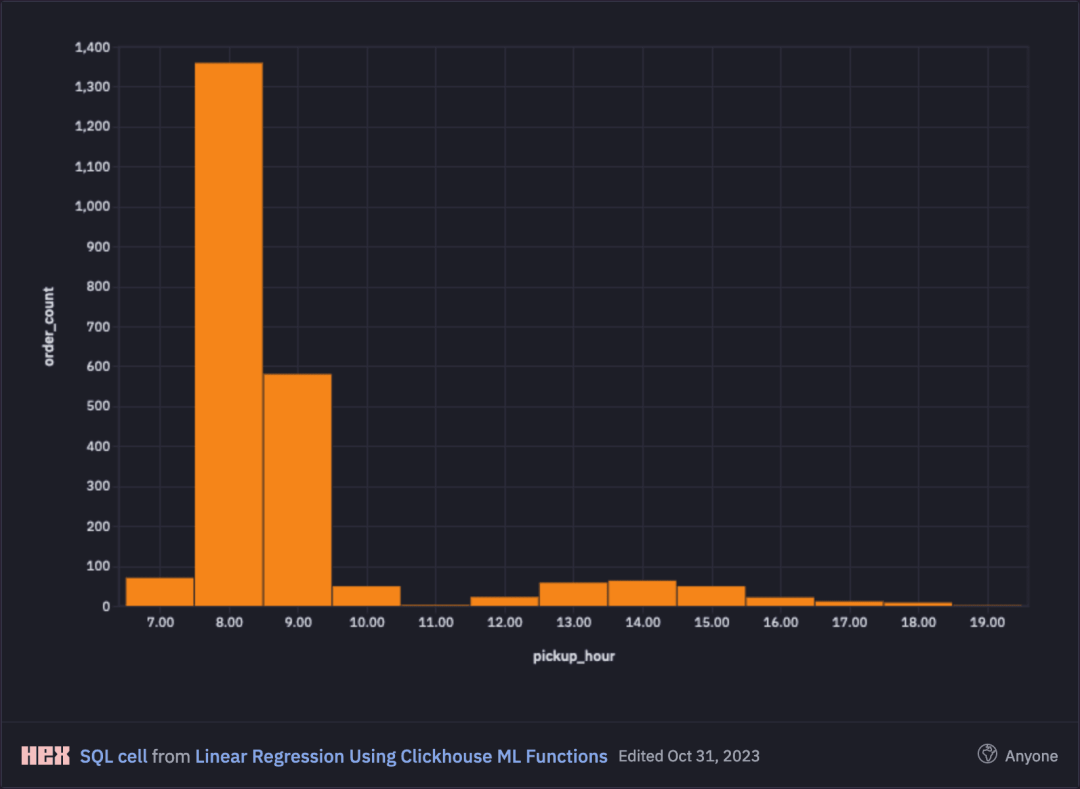
我们的模型还将考虑把取件时间作为第二个变量。因此,我们还将可视化按取件小时计算数的按订单数量的分布,并观察到大多数包裹在早上8点取件。
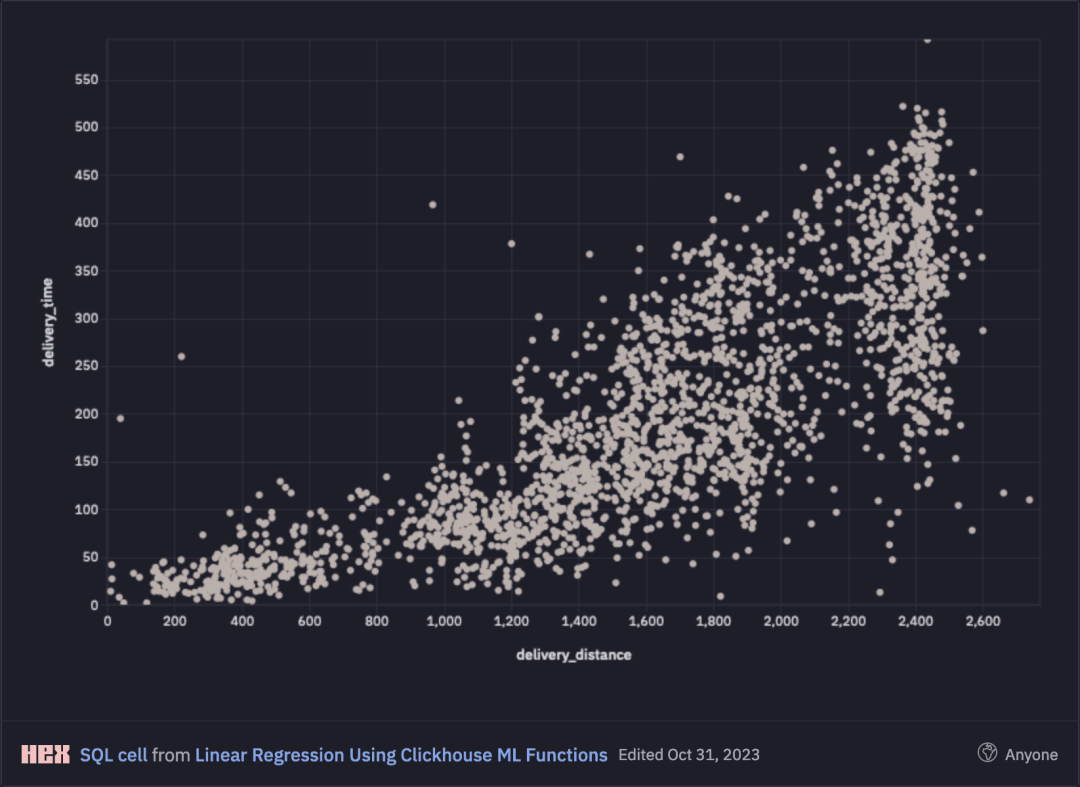
我们的模型将预测取件和交付之间所经过的时间(以分钟为单位),作为取件和交付位置之间距离(以米为单位)和取件小时的函数。
我们使用Clickhouse的geoDistance函数来计算给定它们的坐标(纬度和经度)的取件和交付位置之间的距离,同时我们使用Clickhouse的date_diff函数来计算取件和交付之间所经过的时间。
我们还使用randUniform函数向数据集添加一个随机生成的训练索引,该索引对于80%的数据设置为1,将用于训练,对于剩余的20%的数据设置为0,将用于测试模型的性能。
CREATE TABLE deliveries_dataset (order_id UInt32,delivery_time Float64,delivery_distance Float64,Hour7 Float64,Hour8 Float64,Hour9 Float64,Hour10 Float64,Hour11 Float64,Hour12 Float64,Hour13 Float64,Hour14 Float64,Hour15 Float64,Hour16 Float64,training Float64)ENGINE = MERGETREEORDER BY order_id
INSERT INTO deliveries_datasetSELECTorder_id,date_diff('minute', accept_gps_time, delivery_gps_time) as delivery_time,geoDistance(accept_gps_lng, accept_gps_lat, delivery_gps_lng, delivery_gps_lat) as delivery_distance,if(toHour(accept_gps_time) = 7, 1, 0) as Hour7,if(toHour(accept_gps_time) = 8, 1, 0) as Hour8,if(toHour(accept_gps_time) = 9, 1, 0) as Hour9,if(toHour(accept_gps_time) = 10, 1, 0) as Hour10,if(toHour(accept_gps_time) = 11, 1, 0) as Hour11,if(toHour(accept_gps_time) = 12, 1, 0) as Hour12,if(toHour(accept_gps_time) = 13, 1, 0) as Hour13,if(toHour(accept_gps_time) = 14, 1, 0) as Hour14,if(toHour(accept_gps_time) = 15, 1, 0) as Hour15,if(toHour(accept_gps_time) = 16, 1, 0) as Hour16,if(randUniform(0, 1) <= 0.8, 1, 0) as trainingFROMdeliveries
当可视化时,交付距离和交付时间呈正相关,随着行程变得更长,方差增大。这在直觉上是符合我们的期望的,因为更长的行程变得更难预测。
我们使用Clickhouse的stochasticLinearRegression函数来拟合线性回归模型,基于包含训练数据的数据集的80%。
考虑到该函数使用梯度下降,我们通过减去训练集均值并除以训练集标准差来缩放交付距离(这是唯一的连续特征)。我们取目标的对数,以确保模型预测的交付时间永远不会为负数。
CREATE VIEW deliveries_model AS WITH(SELECT avg(delivery_distance) FROM deliveries_dataset WHERE training = 1) AS loc,(SELECT stddevSamp(delivery_distance) FROM deliveries_dataset WHERE training = 1) AS scaleSELECTstochasticLinearRegressionState(0.1, 0.0001, 15, 'SGD')(log(delivery_time),assumeNotNull((delivery_distance - loc) scale),Hour7,Hour8,Hour9,Hour10,Hour11,Hour12,Hour13,Hour14,Hour15,Hour16) AS STATEFROM deliveries_dataset WHERE training = 1
现在,我们可以使用拟合的模型对我们数据集的剩余20%进行预测。我们将通过比较预测的交付时间与实际值来计算模型的准确性。
CREATE VIEW deliveries_results AS WITH(SELECT avg(delivery_distance) FROM deliveries_dataset WHERE training = 1) AS loc,(SELECT stddevSamp(delivery_distance) FROM deliveries_dataset WHERE training = 1) AS scale,(SELECT state from deliveries_model) AS modelSELECTtoInt32(delivery_time) as ACTUAL,toInt32(exp(evalMLMethod(model,assumeNotNull((delivery_distance - loc) scale),Hour7,Hour8,Hour9,Hour10,Hour11,Hour12,Hour13,Hour14,Hour15,Hour16))) AS PREDICTEDFROM deliveries_dataset WHERE training = 0
我们现在有一个包含20%数据集测试部分的实际交付时间和预测交付时间的表格。
SELECT * FROM deliveries_results LIMIT 10┌─ACTUAL─┬─PREDICTED─┐│ 410 │ 370 ││ 101 │ 122 ││ 361 │ 214 ││ 189 │ 69 ││ 122 │ 92 ││ 454 │ 365 ││ 155 │ 354 ││ 323 │ 334 ││ 145 │ 153 ││ 17 │ 20 │└────────┴───────────┘10 rows in set. Elapsed: 0.015 sec. Processed 9.17 thousand rows, 267.76 KB (619.10 thousand rows/s., 18.07 MB/s.)Peak memory usage: 2.28 MiB.
我们还可以在我们的notebook中按下面的方式可视化这些数据:
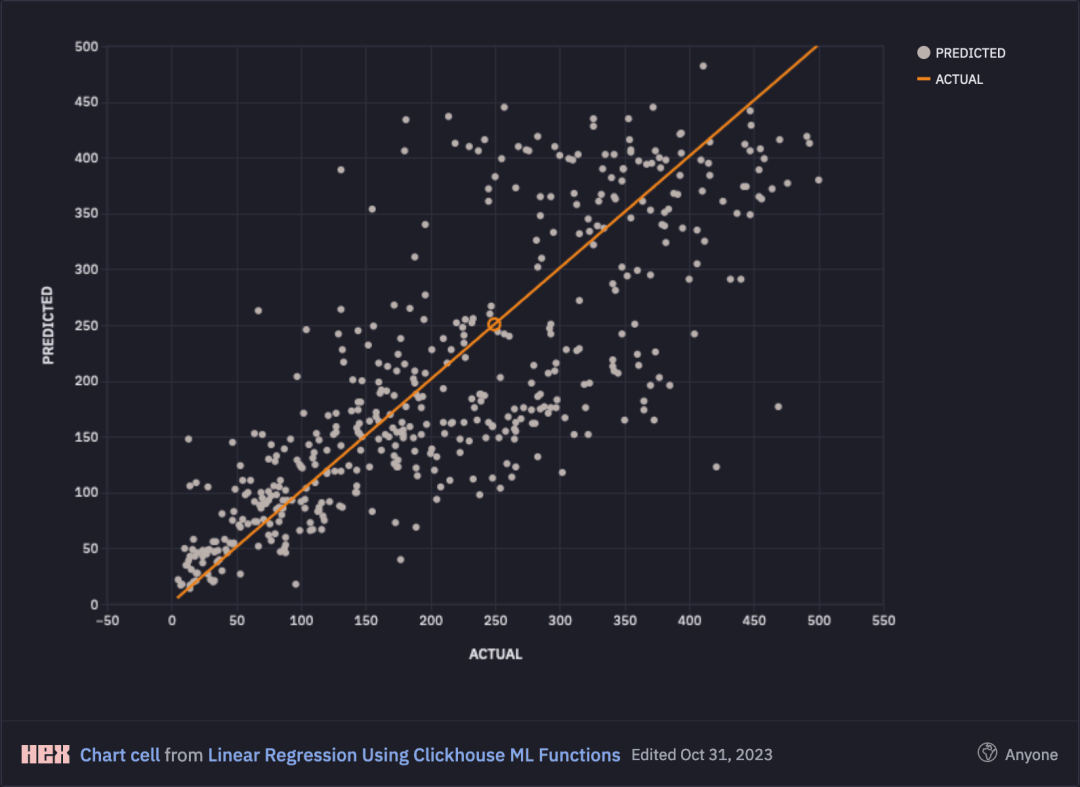
为了解释以上图表,如果模型表现完美,我们预期的预测和实际值在每种情况下都匹配,这意味着所有点都将排列在橙色曲线上。实际上,我们的模型确实存在误差,我们将对其进行分析。
从上面的可视化中,我们可以看到我们的模型对于较短的行程(少于120分钟)表现相当好,但随着距离变得更长,预测精度开始下降,因为它们变得更复杂且难以预测。
这符合我们在现实世界中的经验,即行程越长送达越困难,预测也就越困难。
更科学地说,我们可以通过查看模型的平均绝对误差(MAE)和均方根误差(RMSE)来评估模型的性能。这给我们在整个数据集上大约1小时的值:
SELECTavg(abs(ACTUAL - PREDICTED)) AS MAE,sqrt(avg(pow(ACTUAL - PREDICTED, 2))) AS RMSEFROM deliveries_results┌───────────────MAE─┬──────────────RMSE─┐│ 58.18494623655914 │ 78.10208373578114 │└───────────────────┴───────────────────┘1 row in set. Elapsed: 0.022 sec. Processed 9.17 thousand rows, 267.76 KB (407.90 thousand rows/s., 11.91 MB/s.)Peak memory usage: 2.28 MiB.
如果我们将这限制在实际值小于2小时(120分钟)的较短行程中,我们可以看到我们的模型在MAE和RMSE方面表现更好,更接近30分钟:
SELECTavg(abs(ACTUAL - PREDICTED)) AS MAE,sqrt(avg(pow(ACTUAL - PREDICTED, 2))) AS RMSEFROM deliveries_resultsWHERE ACTUAL < 120┌────────────────MAE─┬──────────────RMSE─┐│ 29.681159420289855 │ 41.68671981213744 │└────────────────────┴───────────────────┘1 row in set. Elapsed: 0.014 sec. Processed 9.17 thousand rows, 267.76 KB (654.46 thousand rows/s., 19.11 MB/s.)Peak memory usage: 2.35 MiB.
在本文中,我们演示了如何使用简单的线性回归函数基于2个输入变量来预测输出值。
模型在较短距离时的性能还可以,但随着输出变量变得更难预测,性能开始下降。尽管如此,我们还是可以看出,在ClickHouse内完全进行的简单线性回归,并且仅使用2个变量,确实具有一定的预测能力,并且在其他数据集和领域中可能表现的更好。
完整的示例说明可以在此处找到【https://app.hex.tech/d83ae9cc-7cbe-40f3-9899-0c348f283047/hex/9206f58c-0bde-4dae-94d7-aa9379773d84/draft/logic】。


