





摘要
我们非常兴奋地分享23.5版本中一系列令人惊叹的功能,其中包括22项性能优化和85个错误修复。以下是一小部分突出功能的简介。需要注意的是,其中几个功能已准备就绪或默认启用。您可以在本文末尾找到相关信息。


经验丰富的ClickHouse用户对于s3和gcs函数应该非常熟悉。从实现角度来看,这两个函数几乎相同,后者是最近为了让用户更直观地查询Google GCS而添加的。这两个函数都允许用户查询存储在基于s3的blob存储中的文件,并且可以原地查询或将其作为数据源插入到ClickHouse MergeTree表中。
尽管GCS几乎与S3完全互操作,但Azure的等效blob存储提供的规范与S3有些不同,并且需要更多的工作。
在23.5版本中,我们很高兴地宣布可用于查询Azure Blob存储的azureBlobStorage表函数。现在用户可以查询Azure Blob存储中支持的任何文件格式。这个函数在参数上与S3和GCS函数有一些不同,但提供了类似的功能。请注意,在下面的示例中,我们需要指定连接字符串、容器和blob路径,以与Azure Blob存储的概念对齐。在下面的示例中,我们查询了英国的成交价格数据集。
SELECTtoYear(toDate(date)) AS year,round(avg(price)) AS price,bar(price, 0, 1000000, 80)FROM azureBlobStorage('https://clickhousepublicdatasets.blob.core.windows.net/', 'ukpricepaid', 'uk_price_paid_*.parquet', 'clickhousepublicdatasets', '<key>')GROUP BY yearORDER BY year ASC┌─year─┬──price─┬─bar(round(avg(price)), 0, 1000000, 80)─┐│ 1995 │ 67938 │ █████▍ ││ 1996 │ 71513 │ █████▋ ││ 1997 │ 78543 │ ██████▎ ││ 1998 │ 85443 │ ██████▊ ││ 1999 │ 96041 │ ███████▋ ││ 2000 │ 107493 │ ████████▌ ││ 2001 │ 118893 │ █████████▌ ││ 2002 │ 137958 │ ███████████ ││ 2003 │ 155894 │ ████████████▍ ││ 2004 │ 178891 │ ██████████████▎ ││ 2005 │ 189362 │ ███████████████▏ ││ 2006 │ 203535 │ ████████████████▎ ││ 2007 │ 219376 │ █████████████████▌ ││ 2008 │ 217044 │ █████████████████▎ ││ 2009 │ 213424 │ █████████████████ ││ 2010 │ 236115 │ ██████████████████▉ ││ 2011 │ 232807 │ ██████████████████▌ ││ 2012 │ 238384 │ ███████████████████ ││ 2013 │ 256926 │ ████████████████████▌ ││ 2014 │ 280027 │ ██████████████████████▍ ││ 2015 │ 297287 │ ███████████████████████▊ ││ 2016 │ 313551 │ █████████████████████████ ││ 2017 │ 346516 │ ███████████████████████████▋ ││ 2018 │ 351101 │ ████████████████████████████ ││ 2019 │ 352923 │ ████████████████████████████▏ ││ 2020 │ 377673 │ ██████████████████████████████▏ ││ 2021 │ 383795 │ ██████████████████████████████▋ ││ 2022 │ 397233 │ ███████████████████████████████▊ ││ 2023 │ 358654 │ ████████████████████████████▋ │└──────┴────────┴────────────────────────────────────────┘29 rows in set. Elapsed: 9.710 sec. Processed 28.28 million rows, 226.21 MB (2.91 million rows/s., 23.30 MB/s.)
对于任何表函数,通常有必要提供一个等效的表引擎,以便用户可以像查询其他表一样查询数据源。如下所示,这简化了后续的查询过程:
CREATE TABLE uk_price_paid_azureENGINE = AzureBlobStorage('https://clickhousepublicdatasets.blob.core.windows.net/', 'ukpricepaid', 'uk_price_paid_*.parquet', 'clickhousepublicdatasets', '<key>')SELECTtoYear(toDate(date)) AS year,round(avg(price)) AS price,bar(price, 0, 1000000, 80)FROM uk_price_paid_azureGROUP BY yearORDER BY year ASC┌─year─┬──price─┬─bar(round(avg(price)), 0, 1000000, 80)─┐│ 1995 │ 67938 │ █████▍ ││ 1996 │ 71513 │ █████▋ ││ 1997 │ 78543 │ ██████▎ │29 rows in set. Elapsed: 4.007 sec. Processed 28.28 million rows, 226.21 MB (7.06 million rows/s., 56.46 MB/s.)
类似于S3和GCS函数,我们也可以使用这些函数将ClickHouse数据写入Azure Blob存储容器,从而帮助解决导出和反向ETL等使用案例。
INSERT INTO FUNCTION azureBlobStorage('https://clickhousepublicdatasets.blob.core.windows.net/', 'ukpricepaid', 'uk_price_paid_{_partition_id}.parquet', 'clickhousepublicdatasets', '<key>') PARTITION BY toYear(date) SELECT * FROM uk_price_paid;
在上面的示例中,我们使用 PARTITION BY 子句和 toYear 函数,每年创建一个Parquet文件。
希望这个函数能够为我们的用户开启新的项目。上述函数在执行时仅在接收节点上执行,限制了可以分配给查询的计算级别。为了解决这个问题,我们正在积极开发一个azureBlobStorageCluster函数。这个函数在概念上与s3Cluster相当,通过利用通配符模式将对S3存储桶中文件的处理分布到集群中。
去年,我们发布了ClickHouse Keeper,为与ClickHouse的集群协调系统相关的数据提供了强一致性存储,这是ClickHouse作为分布式系统运行的基础。它支持数据复制、分布式DDL查询执行、领导选举和服务发现等功能。ClickHouse Keeper与ZooKeeper兼容,ZooKeeper是ClickHouse中传统组件用于实现这些功能。
ClickHouse Keeper已经准备就绪,并在ClickHouse Cloud中广泛运行,支持多租户环境中的数千个ClickHouse部署。
目前,用户可以通过使用诸如 nc 或 zkCli.sh 之类的工具,直接通过TCP与ClickHouse Keeper进行通信。虽然这足以进行基本调试,但这种管理方式并不理想,也不够便捷。为了解决这个问题,在23.5版本中,我们引入了 keeper-client ——一个内置于ClickHouse中的简单工具,用于自省您的ClickHouse Keeper。
为了使用这个客户端进行实验,您可以使用我们最近发布的Docker Compose文件,借助我们的支持团队,快速启动一个多节点的ClickHouse集群。在下面的示例中,我们启动了一个包含一个复制分片和三个keeper实例的双节点部署:
git@github.com:ClickHouse/examples.gitexport CHKVER=23.5export CHVER=23.5cd examples/docker-compose-recipes/recipes/cluster_1S_2R/docker-compose up
上述示例将我们的keeper实例暴露在端口9181、9182和9183上。连接到客户端就像这样简单:
./clickhouse keeper-client -h 127.0.0.1 -p 9181/ :) ruokimok/ :) lsclickhouse keeper/ :)
用户还可以利用--query 参数(类似于ClickHouse客户端)进行bash脚本编写。
./clickhouse keeper-client -h 127.0.0.1 -p 9181 --query "ls/"clickhouse keeper
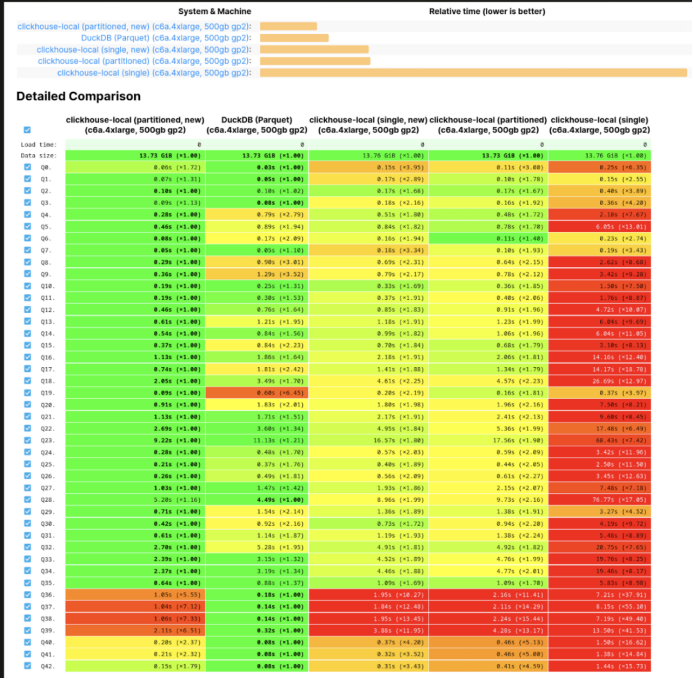
最近,我们在博客中介绍了我们在查询Parquet文件方面所做的改进。这些改进是我们认为使ClickHouse成为全球最快的工具来查询Parquet文件,无论是通过ClickHouse Local还是ClickHouse Server。在对利用行组并行读取Parquet的最近努力不满意之后,23.5版本增加了更多的改进。
这些改进主要集中在低级别上,旨在提高并行读取的效率,并避免使用互斥锁。正如我们在博客中所提到的,过去我们按顺序读取Parquet行,这在本质上限制了读取速度。现在,这个限制已经被消除,无序读取成为默认选项。虽然这对大多数用户可能没有太大影响(除了查询速度更快之外!),因为分析查询通常不依赖于读取顺序,但如果有需要,用户可以通过设置input_format_parquet_preserve_order = true 来恢复到旧的行为。
让我们来看一个改进的例子,考虑执行前面查询的情况,使用包含早期英国成交价格数据集中所有行的单个Parquet文件 - 这个文件可以从这里下载。
--23.4SELECTtoYear(toDate(date)) AS year,round(avg(price)) AS price,bar(price, 0, 1000000, 80)FROM file('house_prices.parquet')GROUP BY yearORDER BY year ASC29 rows in set. Elapsed: 0.367 sec.--23.5SELECTtoYear(toDate(date)) AS year,round(avg(price)) AS price,bar(price, 0, 1000000, 80)FROM file('house_prices.parquet')GROUP BY yearORDER BY year ASC29 rows in set. Elapsed: 0.240 sec.
对于在ClickHouse中基于数据编写Parquet文件的用户,有三种主要方法:使用 INTO OUTFILE 、 INSERT INTO FUNCTION ,或简单地将 SELECT FORMAT Parquet 重定向到文件。从历史上看,我们推荐用户使用后两种方法,主要是因为 INTO OUTFILE 可能会导致行组大小非常大,从而影响后续的读取性能。这可能是一个复杂的调试问题,需要对Parquet有深入的了解。幸运的是,现在这个问题已经解决了,您可以像对待其他格式一样自由地使用 INTO OUTFILE !
虽然上述内容都代表了重大的改进,但这个旅程还没有结束。我们仍然需要进一步改进一些查询,特别是针对单个大型Parquet文件的查询。对于那些感兴趣的人,请关注我们在ClickBench上的Parquet开放基准测试。
如前文所述,目前有几个功能已默认启用,不再是实验性的状态。尤其是在23.5版本中,地理数据类型(如Point、Ring、Polygon、MultiPolygon)和函数(如distance、area、perimeter、union、intersection、convex hull等)已准备就绪!
此外,在22.9版本中首次推出的磁盘上的压缩标记和索引现在也默认可用。启动服务器后,首个查询从未如此迅速。
最后但同样重要的是,查询结果缓存现已被视为“准备就绪”。我们在一篇名为《介绍ClickHouse查询缓存》的文章中对此功能进行了详细介绍。查询缓存的基本思想是:有时可以将昂贵的 SELECT 查询结果缓存起来,以便后续执行相同查询时可以直接从缓存中获取。


