




执行计划可以说是排查SQL执行慢的必备手段,迁移或者业务中遇到慢SQL时使用执行计划可以更好地帮助排查问题根因。
梧桐数据库主要执行算子包括全表扫描、索引扫描、Nestloop Join、HashJoin、Group、Order等等,本文将结合实际对执行计划中主要算子和对应的信息进行说明。
1. 几种EXPLAIN方式
通过EXPLAIN语句可以查看语句的执行计划,主要语法如下:
postgres=# \h EXPLAIN
Command: EXPLAIN
Description: show the execution plan of a statement
Syntax:
EXPLAIN [ ( option [, ...] ) ] statement
EXPLAIN [ ANALYZE ] [ VERBOSE ] statement
where option can be one of:
ANALYZE [ boolean ]
VERBOSE [ boolean ]
COSTS [ boolean ]
SETTINGS [ boolean ]
BUFFERS [ boolean ]
TIMING [ boolean ]
SUMMARY [ boolean ]
FORMAT { TEXT | XML | JSON | YAML }
URL: https://www.postgresql.org/docs/12/sql-explain.html
其中analyze、verbose选项比较重要,analyze可以帮助查看语句实际执行时间和行数,而verbose则可以提供更详细的计划(算子的投影信息和聚集信息等等)。
2. EXPLAIN ANALYZE
2.1 简单查询执行计划说明
一个简单查询的执行计划如下:
-- prepare
-- CREATE TABLE t1(a INT, b INT);
-- INSERT INTO t1 SELECT x,x FROM generate_series(1,10) x; -- 插入10条数据
-- ANALYZE t1;
postgres=# EXPLAIN ANALYZE SELECT * FROM t1 WHERE a=1;
QUERY PLAN
--------------------------------------------------------------------------------------------
Seq Scan on t1 (cost=0.00..1.03 rows=1 width=8) (actual time=5.277..5.403 rows=1 loops=1)
Filter: (a = 1)
1 TupleBatch of 1 Tuple, (1/1/1)(avg/min/max) Tuple/TupleBatch, 68 B
SkipCtid: on
PPD leftover: 0
Predicate Info: Expect to scan 0 stripe(s). Filter out 0 stripe(s).
PPD Stat: (2/3)(FilterOutCount/EvaluateCount)
Optimizer: Postgres query optimizer
Execution: Sequential
NewExecutor: ON
Locality ratio: 0.00
Direct dispatch bucket: 2
Planning Time: 21.221 ms
(slice0) Executor memory: 12K bytes.
Memory used: 262144kB
Execution Time: 8.585 ms
(17 rows)
Seq Scan对应的是全表扫描算子,说明t1表是通过全表扫描的方式获取每条数据。后面括号中说明了算子的估算信息,cost代表算子的代价,其中0.00为启动代价(返回第一条数据的代价,limit场景会更看重这个代价),1.03为算子全部代价(选择计划时一般都是选择total cost更小的计划),rows则是算子的估算行数。
后面括号提供了实际执行过程中统计到的数据,actual time是算子的实际执行时间,5.277是返回第一条记录的时间,5.403是整个算子的执行时间,rows是实际行数,loops则是重复了多少次(多数在Nestloop Join中会出现loops大于1的情况)。
2.2 汇总信息说明
计划的最后提供了汇总的信息,主要字段有以下几个:
Optimizer:取值为Postgres query optimizer/Orca query optimizer,说明采用的优化器模型,通过optimizer参数选取不同的优化器模型。
Execution:说明计划是否是并行计划,如果非并行计划则显示为Sequential,通过force_parallel_mode参数可以开启并行计划。
NewExecutor:说明是否采用了新执行器,梧桐数据库支持列执行器,ON则说明使用了新的列执行器,new_executor参数可以选择是否使用新执行器。
Planning Time:优化器生成计划耗时。
slice:分布式计划的切片,slice是计划中可以独立进行处理的部分。查询计划会为motion生成slice,motion的每一侧都有一个slice。
Memory used:整个语句消耗的内存。
Execution Time:语句完整执行的总耗时。
2.3 分布式执行计划说明
通过下面这个语句的计划和上面对比,可以更好地理解slice和motion的关系以及概念。
postgres=# EXPLAIN ANALYZE SELECT * FROM t1 WHERE b=1;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------
Gather Motion 1:1 (slice1; segments: 1) (cost=0.00..1.05 rows=1 width=8) (actual time=41.000..41.141 rows=1 loops=1)
1 TupleBatch of 1 Tuple, (1/1/1)(avg/min/max) Tuple/TupleBatch, 68 B
InputStream Info: 93 byte(s) (715.121 KB/s) in 0.127 ms with 1 read call(s).
-> Seq Scan on t1 (cost=0.00..1.03 rows=1 width=8) (actual time=3.693..19.675 rows=1 loops=1)
Filter: (b = 1)
2 workers: 0.50/0/1(avg/min/max) tuples
1 TupleBatch of 1 Tuple, (1/1/1)(avg/min/max) Tuple/TupleBatch, 68 B
SkipCtid: on
PPD leftover: 0
Predicate Info: Expect to scan 0 stripe(s). Filter out 0 stripe(s).
PPD Stat: (5/6)(FilterOutCount/EvaluateCount)
Optimizer: Postgres query optimizer
NewExecutor: ON
Locality ratio: 1.00
Planning Time: 10.434 ms
(slice0) Executor memory: 23K bytes.
(slice1) Executor memory: 23K bytes (seg0).
Memory used: 262144kB
Execution Time: 44.848 ms
(20 rows)
首先计划上最明显的差异是新增的Motion算子,原因是表t1默认是按照a列进行hash分布,当过滤条件为a=1时可以准确找到对应的segment节点,从而避免了这一次的motion。但是b列并不是分布列,此时无法确定满足b=1条件的数据所在的segment节点,所以只能通过将t1表的扫描和过滤条件切分为一个slice并发送到各个segment上执行,最后通过gather motion汇聚结果。
3. 相关知识介绍
3.1 Motion简介
Gather Motion:从各个segment节点获取数据并汇聚到dispatcher。

Broadcast Motion:将单个segment节点的表数据广播到其他segment节点。
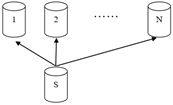
Redistribute Motion:将表数据根据新的分布方式重新分布到其他segment节点。
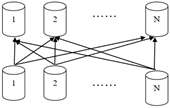
Redistibute Motion和Broadcast Motion的作用和目标基本一致,都是为了实现数据的shuffle,使得segment节点可以进行join/group/order等运算。一般来说Motion的方式是根据代价选择的,表数据量大时倾向于redistribute,broadcast更适用于数据量小的场景。
