




引言
在数据驱动的世界中,企业正在寻求可靠且高性能的解决方案来管理其不断增长的数据需求。本系列博客从一个重视数据安全和合规性的B2C金融科技客户的角度来讨论云上云下面部署的情况下如何利用亚马逊混合科技云原生服务、开源社区产品以及第三方工具构建无服务器数据仓库的解耦方法。

Apache DolphinScheduler 是一种与 EMR Serverless 解耦部署的高效多功能工作流调度程序,可确保可靠的数据编排和处理。对于金融科技客户,EMR Serverless 提供业务线(LOB)级别的精细资源消耗分析,从而实现精确的监控和优化成本。这一功能在金融领域尤其有价值。因为在该领域,运营敏捷性和效率成本至关重要。
本文博客探讨 Apache DolphinScheduler 与 EMR Serverless 的集成 LOB 粒度的资源以及消耗分析方案。
上篇文章传送门:利用Amazon EMR Serverless、Athena与Dolphinscheduler构建云上云下数据同步方案
架构设计图
Apache DolphinScheduler 通常采用和 Hadoop 集群部署混合的方式部署。根据不同的调度工作负载的情况可以选择在 Hadoop 集群中 HDFS 的多台节点上进行部署。
本数据博客探讨数仓计算引擎 EMR Serverless 和 DolphinScheduler 是在3个EC2实例上以集群模式部署Apache DolphinScheduler对EMR Serverless的Job进行编排。
DolphinScheduler 集群另外编排的 EMR 作业解耦配置,实现了整个系统的高可靠性:一个(EMR 作业或调度器)发生故障不会影响另一个(调度器或 EMR 作业)。
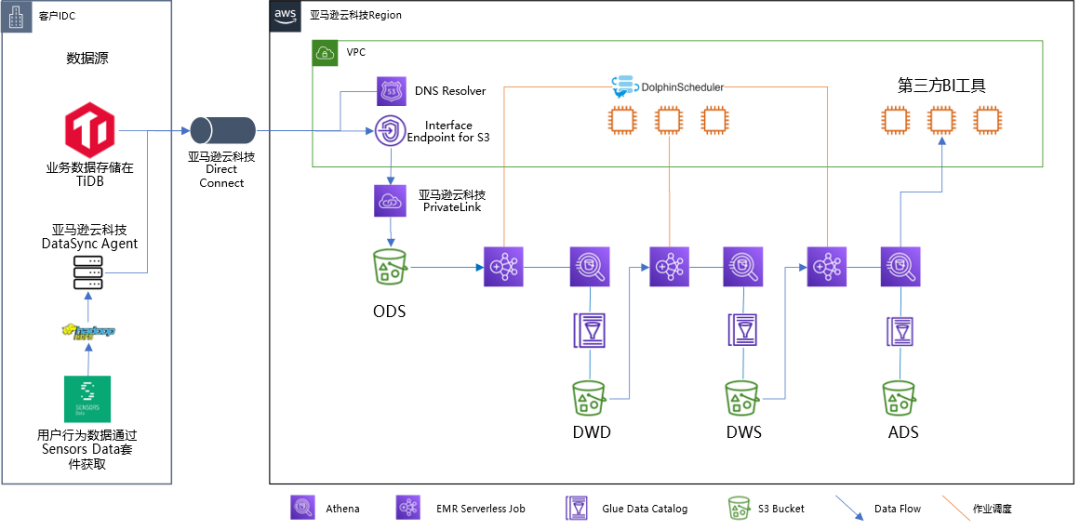
DS集成和作业编排
Apache DolphinScheduler 是现代数据编排平台。以低代码创建快速高性能工作流程。它还提供了强大的用户界面,致力于解决数据管道中复杂的任务依赖,并提供开箱即用的各种类型的关系Apache DolphinScheduler 由 WhaleOps 开发和,并以 WhaleStudio 的产品名称上架亚马逊维护云科技市场。
Apache DolphinScheduler 集群集成 Hadoop。从两点可以具体看出:第一,DolphinScheduler 集群模式默认建议部署在 Hadoop 集群上(通常在数据节点上);第二,上传到 DolphinScheduler 资源管理器的 HQL 脚本默认存储在HDFS上,并且可以通过本机的hive shell命令直接编译,如下图:
Hive -f example.sql
另外,对于这个具体案例,编排 DAG 相当复杂,每个 DAG 包含 300 个多个作业。几乎所有作业都是存储在资源管理器中的 HQL 脚本。
因此,只有成功完成下面队列的任务,才能实现 DolphinScheduler 和 EMR Serverless 之间的无缝集成。
步骤1:将DolphinScheduler资源中心的存储层从HDFS切换到S3
分别编辑文件夹/home/dolphinscheduler/dolphinscheduler/api-server/conf
和文件夹/home/dolphinscheduler/dolphinscheduler/worker-server/conf
下的common.propertie
文件。文件中需要修改的部分如下所示:
#resource storage type: HDFS, S3, OSS, NONE
#resource.storage.type=NONE
resource.storage.type=S3
# resource store on HDFS/S3 path, resource file will store to this base path, self configuration, please make sure the directory exists on hdfs and have read write permissions. "/dolphinscheduler" is recommended
resource.storage.upload.base.path=/dolphinscheduler
# The AWS access key. if resource.storage.type=S3 or use EMR-Task, This configuration is required
resource.aws.access.key.id=AKIA************
# The AWS secret access key. if resource.storage.type=S3 or use EMR-Task, This configuration is required
resource.aws.secret.access.key=lAm8R2TQzt*************
# The AWS Region to use. if resource.storage.type=S3 or use EMR-Task, This configuration is required
resource.aws.region=us-east-1
# The name of the bucket. You need to create them by yourself. Otherwise, the system cannot start. All buckets in Amazon S3 share a single namespace; ensure the bucket is given a unique name.
resource.aws.s3.bucket.name=<target bucket name>
# You need to set this parameter when private cloud s3. If S3 uses public cloud, you only need to set resource.aws.region or set to the endpoint of a public cloud such as S3.cn-north-1.amazonaws.com.cn
resource.aws.s3.endpoint=s3.us-east-1.amazonaws.com
编辑并保存这两个文件后,通过在文件夹路径/home/dolphinscheduler/dolphinscheduler/bin/
下执行以下命令重新启动api-server
和worker-server
。
bash ./binstart-all.sh
bash ./bin/stop-all.sh
bash ./bin/status-all.sh
存储层切换到S3是否成功可以通过DolphinScheduler资源中心加载脚本来检查,检查是否可以在相关的S3文件夹中找到该文件然后。
步骤2:确保通过S3直接上传的作业脚本可以通过DolphinScheduler资源中心控制台找到并操作
完成第一步,可以实现从 DolphinScheduler 资源中心脚本,以及这些脚本在 S3 中。但是,在实战中,客户需要将所有脚本直接迁移到 S3。在 S3 中的脚本脚本应通过 DolphinScheduler 资源中心控制台创建和操作。为了实现这一点,需要通过插入所有脚本的元数据来进一步修改资源中心名为“t_ds_resources”的元数据表。插入命令如下:
insert into t_ds_resources values(4, '<target_script_name>', 'wordcount.java','',1,0,2100,'2023-11-13 10:46:44', '2023-10-31 10:46:44', 2, '<target_script_name>',0);
步骤3:让DolphinScheduler DAG编排器了解作业的状态(FAILED/SUCCESS/SCHEDULED/PENDING),方便DAG能够根据作业的具体状态前进或采取相关操作
如上所述,DolphinScheduler 已与 Hadoop 生态系统直接集成,HQL 脚本可以由 DolphinScheduler DAG 编排器通过 Hive -f xxx.sql 命令编排。因此,当脚本改为 shell 脚本或 python 脚本时(EM 无服务器作业需要通过) ) shell 脚本或 python 脚本编排,不是简单的 Hive 命令),DAG 编排器可以启动作业,但无法获取实时数据作业的状态,因此无法进一步执行工作流程。由于实例中的 DAG 本非常复杂,修改 DAG是不支持的,但是遵循直接迁移策略。
活动推荐
近期,Apache DolphinScheduler联合亚马逊云科技准备举办一场联合Meetup,本活动旨在基于推广大数据调度技术在AWS的构建,结合云原生服务与开源组件的架构设计更灵活的实现数据业务价值,欢迎感兴趣的同学提前预约!
因此,编写了以下脚本来实现作业状态捕获和处理。
应用程序ID列表持久化
var=$(cat applicationlist.txt|grep appid1)
applicationId=${var#* }
echo $applicationId
通过 linux shell 启用 ds 步骤状态自动检查
app_state
{
response2=$(aws emr-serverless get-application --application-id $applicationId)
application=$(echo $response1 | jq -r '.application')
state=$(echo $application | jq -r '.state')
echo $state
}
job_state
{
response4=$(aws emr-serverless get-job-run --application-id $applicationId --job-run-id $JOB_RUN_ID)
jobRun=$(echo $response4 | jq -r '.jobRun')
JOB_RUN_ID=$(echo $jobRun | jq -r '.jobRunId')
JOB_STATE=$(echo $jobRun | jq -r '.state')
echo $JOB_STATE
}
state=$(job_state)
while [ $state != "SUCCESS" ]; do
case $state in
RUNNING)
state=$(job_state)
;;
SCHEDULED)
state=$(job_state)
;;
PENDING)
state=$(job_state)
;;
FAILED)
break
;;
esac
done
if [ $state == "FAILED" ]
then
false
else
true
fi
DolphinScheduler版本推荐
实战发现不是最高版本的DolphinScheduler是最好的,截止作者写这篇文章,最高的版本是3.2.1,使用后面几个版本会比较安全。
本案例分别测试了3.1.4、3.1.5 、3.1.8,其中3.1.4最稳定,仅供参考。
DolphinScheduler 安装指南
针对DolphinScheduler的配置安装已经有博客做了不错的总结,。这里不再赘述。
LOB粒度资源消费分析
如前所述,企业客户,尤其是金融科技客户,已经建立了内部人民币机制的需求。亚马逊云科技成本分配标记机制完美满足了这一要求。所有实例,无论是配置的还是无服务器的,都可以作为标签附加。可以通过Web控制台或亚马逊云科技的CLI将标签附加到实例。
标记后,您可以在亚马逊云科技发票/成本分配标签控制台中激活标签,如下图所示。
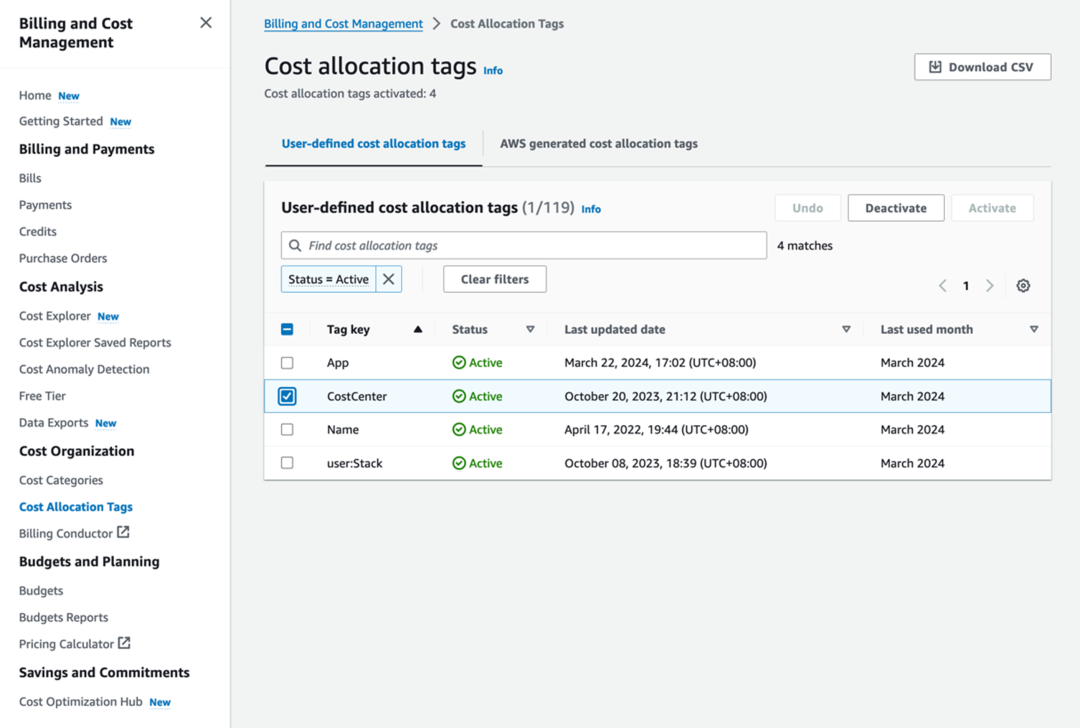
激活标签后,标签的状态立即更改为“活动”。需要注意的是,通过发票和成本管理/成本浏览器控制台可视化标签的财务数据几乎需要一天的时间。
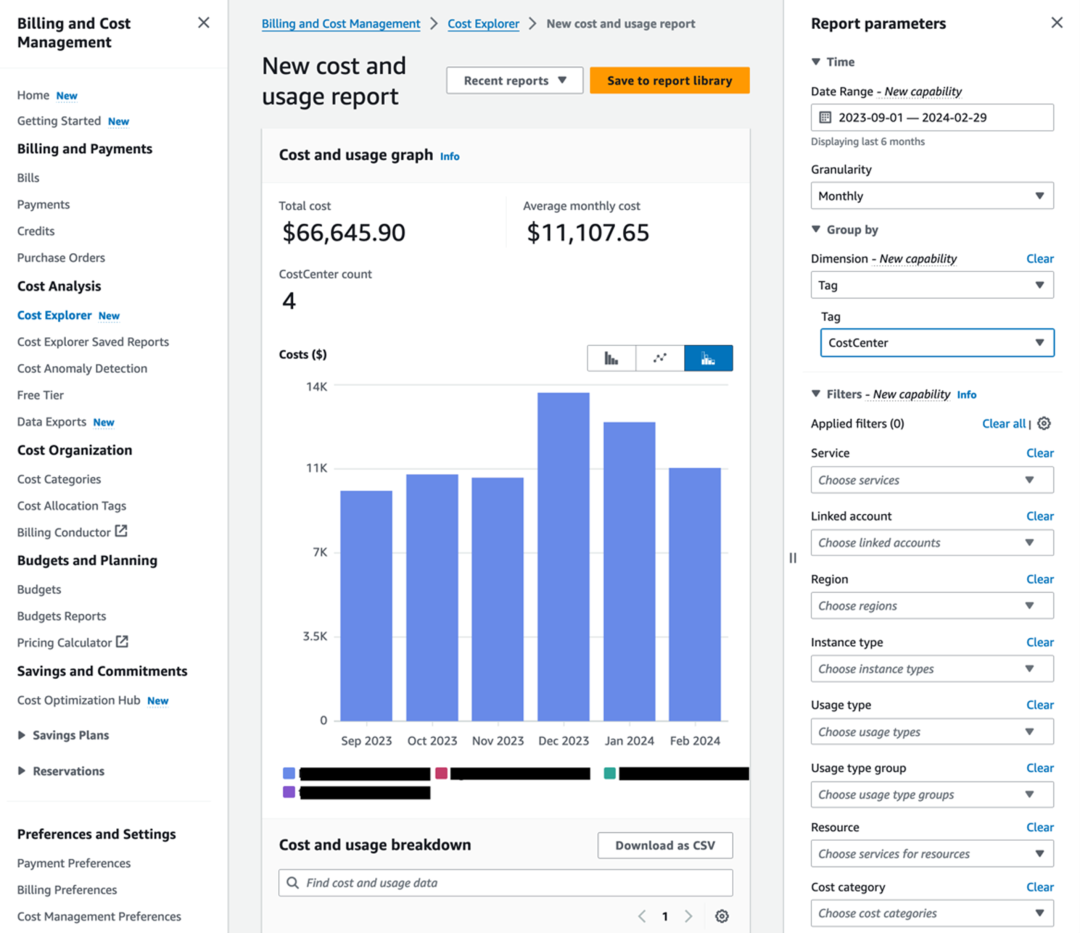
如图3所示,在右侧的标签下拉框CostCenter之后,中间的柱状图显示了打了CostCenter这个标签的不同价值值的服务消费情况。这里,价值的价值设计成需要了解资源消费的情况LOB的名称可以在LOB粒度上实现对资源消费情况进行统计以及可视化测量。
总结
Apache DolphinScheduler作为大数据作业调度工具在华人开发者中非常流行。然而,其原有的部署环境在hadoop上的现状与亚马逊云科技持续创新的新一代无服务器架构的产品服务之间存在一些差距。
论文结合实战总结了弥补这些差距的方法,并探讨了通过打标签的方式实现LOB粒度资源消耗数据及可视化的方法。
此前,白鲸开源已将旗下产品WhaleStudio(基于Apahce DolphinScheduler及SeaTunnel开发的商业版本)上线亚马逊云科技平台,感兴趣的朋友可访问订阅:https://aws.amazon.com/marketplace/pp/prodview-563cegc47oxwm?sr=0-1&ref_=beagle&applicationId=AWSMPContessa
亚马逊云科技为客户提供的云平台及服务在安全和合规方面积累了非常丰富的认证,包括平台整体认证、适配所在国家/地区监管法规的认证、行业认证等等;同时亚马逊云科技也开发了非常丰富的产品服务帮助客户应对数据安全合规角度的各种需求。
参与Apache DolphinScheduler 社区有非常多的参与贡献的方式,包括:

