





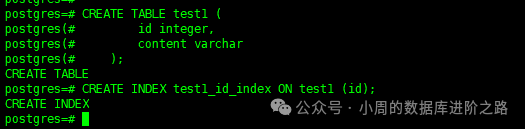
1.创建索引
CREATE TABLE test1 (id integer, content varchar);
CREATE INDEX test1_id_index ON test1 (id);
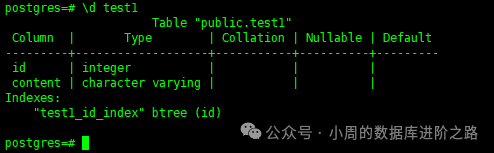
2. 查看某表的索引
\d test1
3.查看表索引的数量
test1指需要查看的表名
SELECT CONCAT(n.nspname,'.', c.relname) AS table,
i.relname AS index_name FROM pg_class c
JOIN pg_index x ON c.oid = x.indrelid
JOIN pg_class i ON i.oid = x.indexrelid LEFT JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE c.relkind = ANY (ARRAY['r', 't']) AND c.relname like 'test1';

4.查看索引统计信息
通过 pg_stat_user_indexes 视图可以查看索引的使用情况和性能统计信息
SELECT * FROM pg_stat_user_indexes WHERE relname = 'test1';

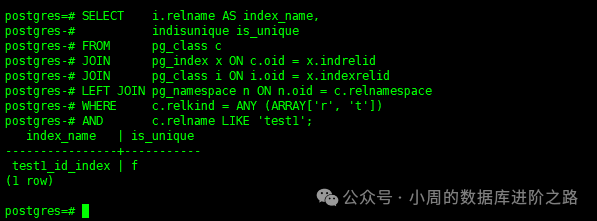
5.检查索引唯一性
索引是一项解决数据库性能功能,但与此同时,它也可用于确保唯一性。但是,为了确保唯一性,我们需要一种称为唯一索引的单独索引类型。为了检查索引是否唯一,pg_index有一个名为indisunique的列来标识索引的唯一性。
SELECT i.relname AS index_name,
indisunique is_unique
FROM pg_class c
JOIN pg_index x ON c.oid = x.indrelid
JOIN pg_class i ON i.oid = x.indexrelid
LEFT JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE c.relkind = ANY (ARRAY['r', 't'])
AND c.relname LIKE 'test1';
6.查看索引的大小
这是一种非常简单的方法来获取PostgreSQL索引的大小,test1_id_index指建的索引名。
SELECT pg_size_pretty(pg_relation_size('test1_id_index'));

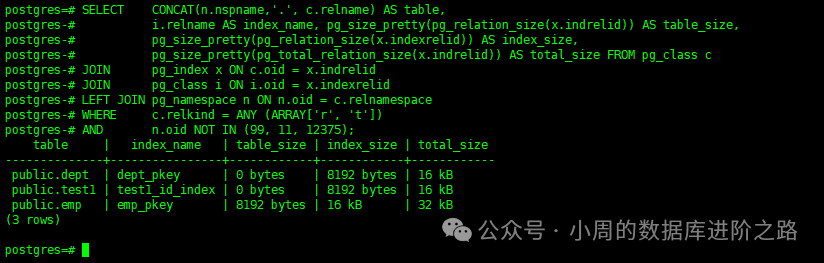
7.查看索引、表、两者总大小
SELECT CONCAT(n.nspname,'.', c.relname) AS table,
i.relname AS index_name, pg_size_pretty(pg_relation_size(x.indrelid)) AS table_size,
pg_size_pretty(pg_relation_size(x.indexrelid)) AS index_size,
pg_size_pretty(pg_total_relation_size(x.indrelid)) AS total_size FROM pg_class c
JOIN pg_index x ON c.oid = x.indrelid
JOIN pg_class i ON i.oid = x.indexrelid
LEFT JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE c.relkind = ANY (ARRAY['r', 't'])
AND n.oid NOT IN (99, 11, 12375);
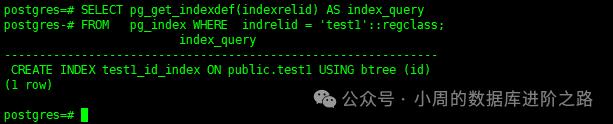
8.获取索引创建语句
该查询将显示索引创建语句
SELECT pg_get_indexdef(indexrelid) AS index_query
FROM pg_index WHERE indrelid = 'test1'::regclass;
9.重新构建索引
如果索引损坏或过大,则需要再次构建该索引。同时,不想阻塞表上的操作,可以选择使用REINDEX CONCURRENTLY命令。
REINDEX INDEX CONCURRENTLY test1_id_index;

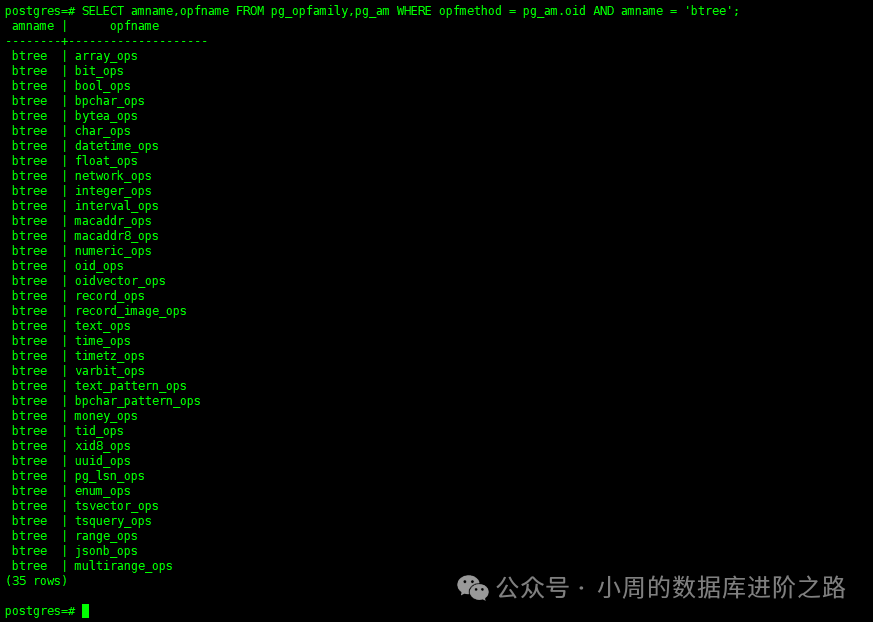
10.索引支持的数据类型
SELECT amname,opfname FROM pg_opfamily,pg_am WHERE opfmethod = pg_am.oid AND amname = 'btree';
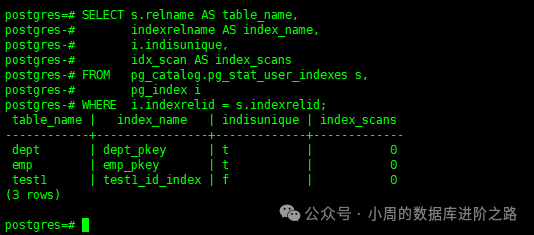
11.查找从未使用过的索引
如果index_scans为0或接近0,则可以删除这些索引。
SELECT s.relname AS table_name,
indexrelname AS index_name,
i.indisunique,
idx_scan AS index_scans
FROM pg_catalog.pg_stat_user_indexes s,
pg_index i
WHERE i.indexrelid = s.indexrelid;
12.查找重复索引
SELECT indrelid::regclass table_name,
att.attname column_name,
amname index_method
FROM pg_index i,
pg_class c,
pg_opclass o,
pg_am a,
pg_attribute att
WHERE o.oid = ALL (indclass)
AND att.attnum = ANY(i.indkey)
AND a.oid = o.opcmethod
AND att.attrelid = c.oid
AND c.oid = i.indrelid
GROUP BY table_name,
att.attname,
indclass,
amname, indkey
HAVING count(*) > 1;
文中的概念来源于网络,如有侵权,请联系我删除。
欢迎关注公众号:小周的数据库进阶之路,一起交流数据库、中间件和云计算等技术。欢迎觉得读完本文有收获,可以转发给其他朋友,大家一起学习进步!感兴趣的朋友可以加我微信,拉您进群与业界的大佬们一起交流学习。
