




在处理大规模数据时,PostgreSQL的性能优化是一个非常重要的话题,其中分区表(Partitioned Tables)是提高查询和数据管理效率的重要手段。本文将详细介绍PostgreSQL分区表的概念、优势、创建与管理方法以及一些常见的优化策略。

#PG培训#PG考试#postgresql培训#postgresql考试#postgresql认证
一、分区表的概念
分区表是一种将大表分割成更小、更容易管理的部分(分区)的方法。这些分区可以根据某些规则(如范围、列表、哈希等)进行组织,从而提高查询效率和数据管理的灵活性。每个分区本质上是一个独立的表,但从逻辑上来看,它们是一个整体。
二、分区表的优势
- 提高查询性能:对于大数据集,通过将数据划分到多个分区中,查询可以在较小的分区范围内执行,从而减少I/O操作和提高查询速度。
- 管理便利:可以对不同的分区进行独立的维护和管理操作,如备份、恢复和清理过期数据等。
- 提高写入性能:在并发写入的情况下,不同分区的数据可以并行写入,减少写入冲突。
- 存储优化:不同的分区可以存储在不同的存储介质上,优化存储资源的使用。
三、创建和管理分区表
1. 创建分区表
首先,创建一个分区表,然后根据分区键创建具体的分区。例如,按照日期范围进行分区:
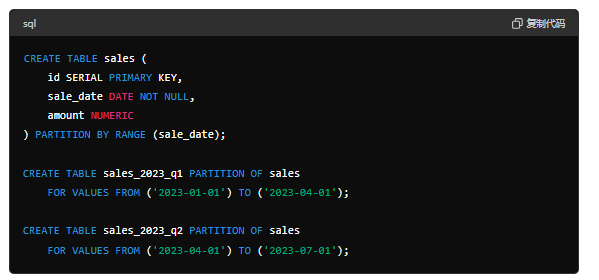
2. 插入数据
数据插入到分区表时,PostgreSQL会根据分区键自动将数据插入到对应的分区中:

3. 查询数据
查询操作与普通表无异,PostgreSQL会自动优化查询以仅访问相关的分区:


四、分区表的优化策略
- 适当的分区策略:根据数据的特点选择适当的分区策略(范围、列表、哈希等)。例如,对于时间序列数据,范围分区是常见选择。
- 维护分区:定期维护分区,如删除或归档过期数据,防止分区数量过多影响性能。
- 索引优化:在分区表和分区上创建适当的索引,提升查询性能。
- 监控和调整:持续监控分区表的性能,并根据实际情况调整分区策略和管理操作。
五、结论
分区表是PostgreSQL中处理大规模数据的有效工具,通过合理的分区策略和优化,可以显著提高数据库的性能和管理效率。掌握分区表的创建与管理方法,并结合实际业务需求进行优化,是每个数据库管理员和开发人员应具备的技能。
通过上述内容,希望能帮助你更好地理解和应用PostgreSQL分区表,实现更高效的数据管理和查询性能。
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
