





在当今数据密集型应用的背景下,存储引擎扮演着关键的角色。它们是数据库系统的核心组件,负责管理数据的存储和检索。本文摘自近期机械工业出版社出版的《深入浅出存储引擎》一书,探讨主流数据库存储引擎的前世今生。同时欢迎读者积极留言,号主将选择三位读者赠与此书。
01 存储引擎现状
存储引擎作为数据库系统的核心组件,扮演着至关重要的角色,直接影响着数据库的性能和功能。当前,主流的关系型数据库管理系统(RDBMS)如MySQL、Oracle和SQL Server都提供了多种存储引擎选择,以满足不同的需求和应用场景。此外,随着大数据和分布式计算的崛起,NoSQL数据库系统如MongoDB和Cassandra也提供了各种不同类型的存储引擎,使得用户能够根据具体的业务需求选择适合的存储引擎。
在关系型数据库中,常见的存储引擎包括InnoDB、MyISAM、Oracle的ACID存储引擎等。每个存储引擎都有其独特的设计原理和适用场景。例如,InnoDB是MySQL的默认存储引擎,它采用了B+树索引结构,支持事务和行级锁定,适用于高并发和写入密集的应用。MyISAM则适用于读取操作较多的场景,它采用了B树索引结构,不支持事务和行级锁定,但具有较高的查询性能。Oracle的ACID存储引擎则提供了强大的事务支持和高级的数据管理功能,适用于大规模企业级应用。
与传统的关系型数据库不同,NoSQL数据库系统提供了更灵活的存储引擎选择。例如,MongoDB提供了WiredTiger和MMAPv1等存储引擎。WiredTiger存储引擎采用了LSM树结构,支持高并发写入和复杂查询,适用于大规模数据处理和分布式环境。MMAPv1存储引擎则适用于内存限制较小的场景,通过内存映射文件实现数据的存储和检索。
除了上述存储引擎外,还有许多其他类型的存储引擎不断涌现。例如,图数据库中常用的存储引擎包括Neo4j的图存储引擎和JanusGraph的分布式图存储引擎。这些存储引擎专门针对图数据结构进行优化,提供了高效的图遍历和图算法支持。时序数据库中的存储引擎如InfluxDB的TSI引擎和OpenTSDB的HBase引擎,提供了针对时间序列数据的高性能存储和查询能力。列存储数据库中的存储引擎如Apache Cassandra的LSM树引擎和HBase的HFile引擎,适用于大规模列式数据的存储和分析。下图是B+树存储引擎和LSM树存储引擎的典型实现组件。

02 B+树存储引擎
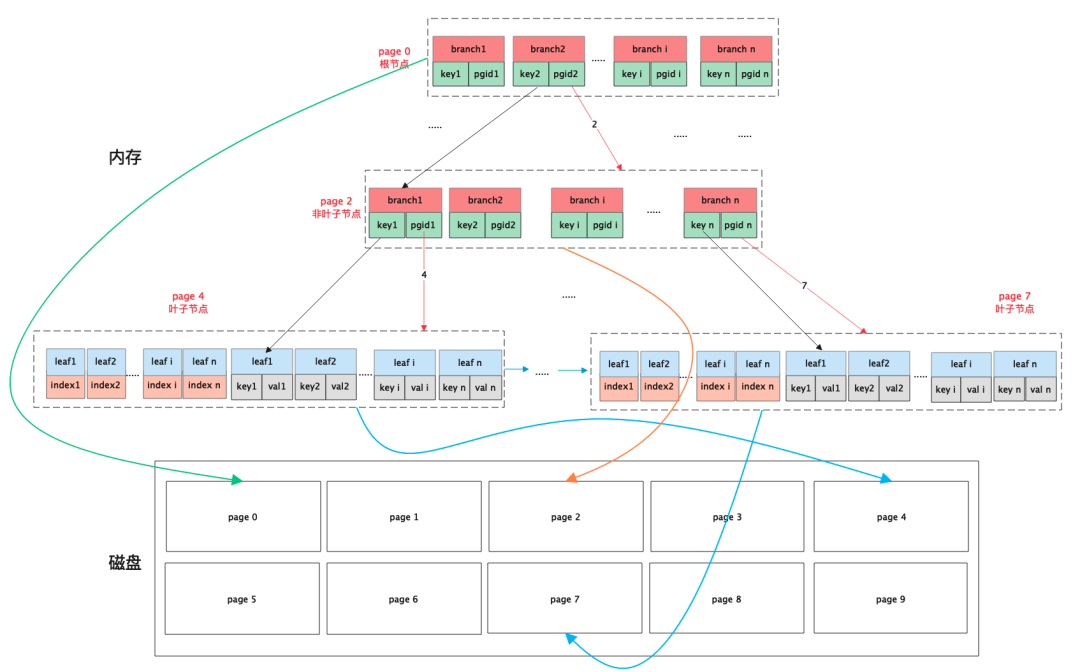
B+树存储引擎,顾名思义它内部采用B+树这种数据结构来存储数据。B+树它的特点主要有三个:一是属于多叉树,一个节点内部可以存储多个孩子节点;二是内部存储的数据是有序的,可以支持顺序遍历维护的数据;三是根据不同类型的节点,内部保存的数据有所不同,根节点、分支节点保存的是数据的索引信息,而叶子节点则保存的是原始数据。第三个特性是其他一般的数据结构所不具备的。因此得益于B+树的上述特点,使得它具有平衡性、有序性和高效性能等优势,适用于支持范围查询和高效的数据插入、删除、查找操作。
数据组织:B+树存储引擎将数据按照键的顺序组织在树的叶子节点上。每个叶子节点包含一个键和对应的数据记录,叶子节点之间通过指针连接形成链表。非叶子节点存储了一组键和对应的子节点指针,用于导航到下一级的节点。
数据查找:通过B+树的根节点开始,根据查询条件比较键的大小,逐级向下搜索,直到找到匹配的键或者到达叶子节点。叶子节点上存储了完整的键和数据记录,可以直接返回查询结果。
范围查询:由于B+树的有序性和共享性,范围查询可以通过顺序遍历叶子节点链表来实现。通过找到范围的起始和结束位置,沿着链表遍历并返回满足条件的数据记录。
数据插入和删除:数据的插入操作通过搜索找到合适的叶子节点,然后在该节点中插入新的键和数据记录。数据的删除操作先定位到要删除的键所在的叶子节点,然后删除对应的键和数据记录。为了保持B+树的平衡性,插入和删除操作可能需要进行节点的分裂和合并。
一个简单的B+树存储引擎示意图如下图所示。
03 LSM树存储引擎
经典的LSM树存储引擎如下图所示。内存层中LSM树主要由MemTable、ImmuMemTable构成。二者的区别在于,当MemTable中数据写满(达到设定的最大阈值)后,它就会将当前的MemTable设置成只读,该MemTable就变成了ImmuMemTable。之后重新创建一个新的MemTable来继续处理新的写请求,MemTable一般是内存中实现的一个有序的数据结构,通常会采用红黑树、B树、跳表等数据结构实现。
磁盘层由多层SSTable(Sorted String Table)文件构成,这些SSTable文件有些是由内存中的ImmuMemTable定期落盘形成,有些则是在后续过程中压缩数据后生成。存储在磁盘上的SSTable会定期进行数据的合并,以减少SSTable数目,提升空间利用率和读性能。有些系统也会把数据的合并称为数据压缩,本质上是通过合并相同k的数据以减少重复的数据条目。最主要的压缩策略有分层压缩和分级压缩。以分层压缩为例,随着层数越大,存储的数据越多,数据越旧,层数小的层数合并后的数据会迁移到下一层级。下面简单介绍下LSM树存储引擎的读写过程。
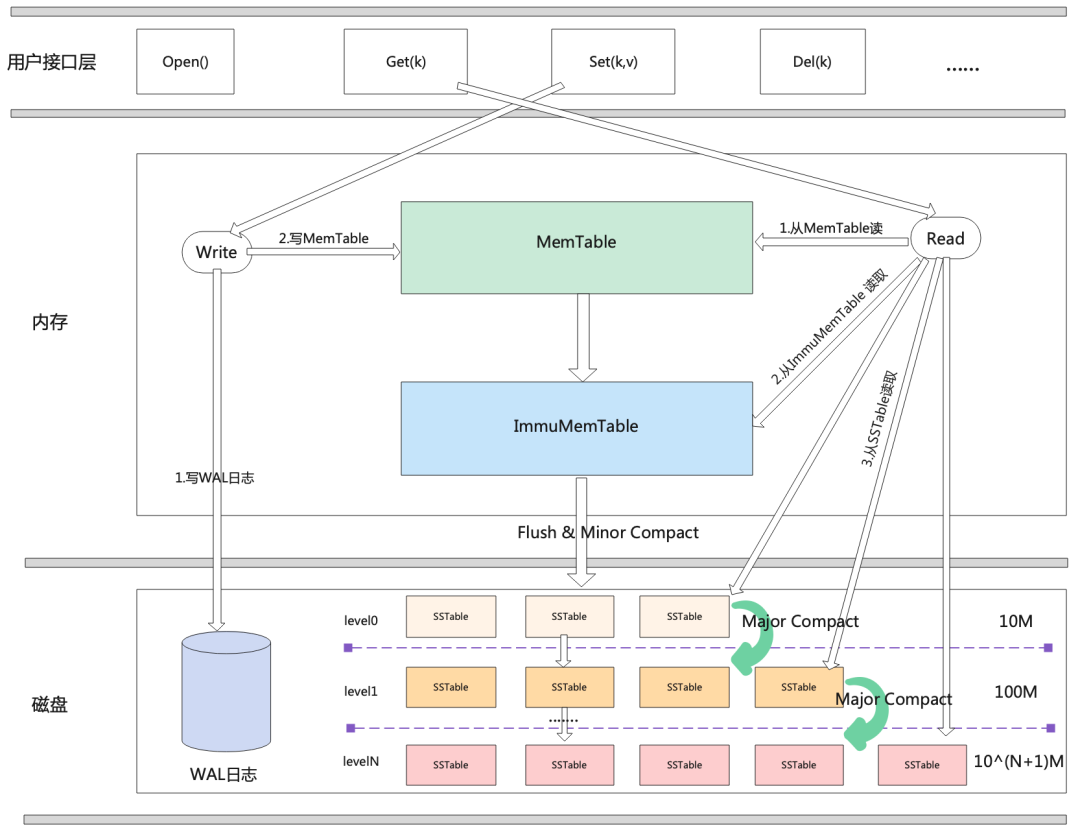
对于LSM树而言,它处理写操作的主要过程如下:当存储引擎接收到写请求时,首先会将数据记录一份到WAL日志文件中以保证数据的持久性,写完WAL日志后紧接着它会将该条数据写入到内存中的MemTable模块中,当数据写入MemTable完成后这一次写操作就完成了,可以响应给客户端了。
对于读请求而言,LSM树在处理时的流程如下:首先接收到一个读请求后,LSM树会首先从内存中的MemTable中读取数据,如果没读到再从ImmuMemTable中读取数据,如果还没读取到数据则会从磁盘上的SSTable依次从低层级往高层级读取。一旦读取到数据则就停止读取过程,然后返回给客户端数据。从本质上来说LSM树由于是追加写数据的,因此读取时只需要逆序读取最新的数据即可。 此外LSM树系统后台有专门的线程完成一些异步任务,例如内存中只读的ImmuMemTable中维护的数据会定期被后台线程写入到磁盘中形成SSTable文件。有些组件称这个过程为Minor Compact,再比如每一层的SSTable数目一般都是有限制的,当超过限制后异步线程会进行层与层之间的数据压缩,有些组件则称为Major Compact。
04 未来发展趋势
随着计算机技术的发展和硬件资源的提升,存储引擎也得到了进一步的改进和优化。现代存储引擎不仅使用了更复杂的索引结构和数据管理算法,还利用了磁盘阵列、高速缓存和数据压缩等技术来提高数据的存储和访问性能。
未来存储引擎的发展将继续面临挑战和机遇。随着大数据和人工智能的发展,对存储引擎的性能和扩展性提出了更高的要求。存储引擎需要适应分布式计算、高并发和大规模数据处理的需求。同时,非关系型数据库系统的兴起也推动了存储引擎的发展,新型存储引擎如列存储、图数据库和时序数据库等不断涌现,以满足特定领域的需求。
关于作者:文小飞 (网名:jaydenwen/jaydenwen123),大厂资深研发工程师、公司级讲师。曾就职于腾讯等互联网公司,从事基础架构、后端开发、推荐系统架构等工作,具有丰富的基础架构经验。对技术充满热情,尤其对存储引擎、分布式共识算法等技术有较为深入的理解,曾编写开源书籍“自底向上分析 BoltDB 源码”,并发布“数据存储与检索”等网络课程。业余时间喜欢阅读开源项目源码,学习新技术。
- END -
本文摘编自《深入浅出存储引擎》,经出版方授权发布。

长按下方二维码,发现更多科技好书
▼

本文来源:原创,图片来源:原创、pexels
责任编辑:王莹,部门领导:宁姗
发布人:白钰
