





新钛云服已累计为您分享767篇技术干货
上期回顾:

上期内容:
一、 运维目标
二、 基本规定
2.1 适用范围
2.2 基本定义
三、 职责
四、 云运维管理规范
4.1 运维人员基本准则
4.1.1 必须遵守的运维准则
4.1.2 运维铁律
4.2 云资源使用规范
4.2.1 VPC使用规范
4.2.2 弹性公网IP使用规范
4.2.3 NAT网关使用规范
4.2.4 资源组/标签使用规范
4.3 权限管理
4.3.1 用户岗位职责描述
4.3.2 用户权限原则
4.3.3 权限分配流程
4.4 安全管理
4.4.1 网络安全
4.4.2 运维安全加固
4.4.3 云服务器安全组访问策略
4.4.4 操作审计
下期内容:
4.5 云平台监控体系
4.5.1 监控对象
4.5.2 监控工具
4.5.3 监控内容
4.6 备份与恢复
4.6.1 数据文件备份
4.6.2 数据库备份
4.6.3 HBR备份
4.6.4 备份管理
4.7 漏洞与补丁管理
4.8 系统巡检
4.9 费用管理
4.9.1 费用预算管理
4.9.2 费用核对和审计
4.9.3 费用分配和归集
4.9.4 费用监控和预警
4.9.5 费用节约和优化
4.10 运维服务流程
4.10.1 监控事件响应流程
4.10.2 变更流程
4.5.1 监控对象
4.5.2 监控工具
4.5.3 监控内容
监控内容 | 监控工具 | 监控内容解释 | 触发器 |
磁盘利用率>95% | 云监控 | 磁盘利用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
CPU利用率>95% | 云监控 | CPU利用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
内存利用率>95% | 云监控 | 内存利用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
外网出带宽使用率>95% | 云监控 | 外网出带宽使用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
CPU一分钟平均负载>5 | 云监控 | CPU一分钟平均负载 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
zabbix_agent 持续5分钟未采集到数据 | Zabbix | Zabbix agent连通性 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
服务器发生重启 | Zabbix | 服务器发生重启 | 统计粒度1分钟,system.uptime.change值<0即告警 |
云数据库:
监控内容 | 监控工具 | 监控内容解释 | 触发器 |
磁盘利用率>85% | 云监控 | 磁盘利用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
CPU利用率>85% | 云监控 | CPU利用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
内存利用率>85% | 云监控 | 内存利用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
主从延迟时间>5S | 云监控 | 主从延迟时间 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
对象存储:
监控内容 | 监控工具 | 监控内容解释 | 触发器 |
4xx状态码>50次 | 云监控 | 4xx状态码 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
5xx状态码>50次 | 云监控 | 5xx状态码 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
容器服务:
监控内容 | 监控工具 | 监控内容解释 | 触发器 |
容器服务Pod数量环比波动20% | 云监控 | 容器服务Pod数量环比波动 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
容器服务集群PVC云盘使用率大于90% | 云监控 | 容器服务集群PVC云盘使用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
容器服务集群中容器内存使用率大于90% | 云监控 | 容器服务集群中容器内存使用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
容器服务集群中容器CPU使用率大于90% | 云监控 | 容器服务集群中容器CPU使用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
容器服务集群发现状态异常Pod | 云监控 | 容器服务集群发现状态异常Pod | 状态异常的Pod数 > 1个,连续5次满足条件则2小时告警一次 |
容器服务集群节点Pod重启次数大于3次 | 云监控 | 容器服务集群节点Pod重启次数 | Pod重启次数 > 3次,连续5次满足条件则2小时告警一次 |
容器服务集群节点内存使用率大于90% | 云监控 | 容器服务集群节点内存使用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
容器服务集群节点CPU使用率大于90% | 云监控 | 容器服务集群节点CPU使用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
容器服务集群内存使用率大于90% | 云监控 | 容器服务集群内存使用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
容器服务集群CPU使用率大于90% | 云监控 | 容器服务集群CPU使用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
容器服务集群Node状态异常 | 云监控 | 容器服务集群Node状态 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
消息服务Kafka:
监控内容 | 监控工具 | 监控内容解释 | 触发器 |
磁盘使用百分比>90% | 云监控 | 磁盘使用百分比 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
实例连接数百分比>90% | 云监控 | 实例连接数百分比 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
实例生产带宽百分比>90% | 云监控 | 实例生产带宽百分比 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
实例消费带宽百分比>90% | 云监控 | 实例消费带宽百分比 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
云数据库MongoDB:
监控内容 | 监控工具 | 监控内容解释 | 触发器 |
磁盘利用率>90% | 云监控 | 磁盘利用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
CPU利用率>90% | 云监控 | CPU利用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
连接使用率>90% | 云监控 | 连接使用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
内存使用率>90% | 云监控 | 内存使用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
云数据库Redis:
监控内容 | 监控工具 | 监控内容解释 | 触发器 |
CPU利用率>90% | 云监控 | CPU利用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
内存利用率>90% | 云监控 | 内存利用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
出流量使用率>90% | 云监控 | 出流量使用率使用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
连接使用率>90% | 云监控 | 连接使用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
节点CPU利用率>90% | 云监控 | 节点CPU利用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
节点内存利用率>90% | 云监控 | 节点内存利用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
云数据库PostgreSQL:
监控内容 | 监控工具 | 监控内容解释 | 触发器 |
存储空间使用率>90% | 云监控 | 存储空间使用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
CPU利用率>90% | 云监控 | CPU利用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
内存利用率>90% | 云监控 | 内存利用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
Elasticsearch集群:
监控内容 | 监控工具 | 监控内容解释 | 触发器 |
最大磁盘使用率>90% | 云监控 | 最大磁盘使用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
最大CPU利用率>90% | 云监控 | 最大CPU利用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
最大内存利用率>90% | 云监控 | 最大内存利用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
平均JVM内存使用率>95% | 云监控 | 平均JVM内存使用率 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
负载均衡:
监控内容 | 监控工具 | 监控内容解释 | 触发器 |
服务器端口状态异常 | 云监控 | 服务器端口状态异常 | 统计粒度1分钟,连续5次满足条件则2小时告警一次 |
4.6 备份与恢复
4.6.1 数据文件备份
适用范围 | 所有数据盘上存放有应用数据的云服务器 |
备份方式 | 设置自动快照策略,对数据盘进行快照 |
频率 | 每1天1次 |
开始时间 | 01:00 |
保存时长 | 2周 |
适用范围 | 所有数据盘上存放有应用数据的云服务器 |
备份方式 | 设置自动快照策略,对数据盘进行快照 |
频率 | 每1天1次 |
开始时间 | 01:00 |
保存时长 | 1周 |
4.6.2 数据库备份
备份类型 | 开始时间 | 备份频率 | 保存时长 |
快照备份 | 01:00 | 每天 | 14天 |
日志备份 | 01:00 | 每天 | 14天 |
测试环境:
备份类型 | 开始时间 | 备份频率 | 保存时长 |
快照备份 | 01:00 | 每天 | 7天 |
日志备份 | 01:00 | 每天 | 7天 |
4.6.3 HBR备份
阿里云上有统一灾备平台:混合云备份HBR(Hybrid Backup Recovery) 。HBR集成了阿里云ECS整机、ECS数据库、文件系统、NAS、OSS以及自建机房内的文件、数据库、虚拟机、大规模NAS等提供备份、容灾保护以及策略化归档管理功能,是一个简单易用、敏捷高效、安全可靠的公共云数据管理服务,云平台备份策略多是在HBR上进行统一管理的。
SQL Server数据库备份:
备份类型 | 开始时间 | 备份频率 | 保存时长 |
全量备份 | 22:00 | 每周六 | 3个月 |
增量备份 | 00:00 | 每天 | 3个月 |
ECS文件备份:
备份类型 | 开始时间 | 备份频率 | 保存时长 |
指定目录备份 | / | 每周一次 | 1个月 |
ECS整机备份:
备份类型 | 开始时间 | 备份频率 | 保存时长 |
策略1 | 00:00 | 每周 | 30天 |
策略2 | 00:00 | 每天 | 7天 |
OSS备份:
备份类型 | 开始时间 | 备份频率 | 保存时长 |
整个Bucket | 00:00 | 每天 | 7天 |
NAS备份:
备份类型 | 开始时间 | 备份频率 | 保存时长 |
策略1 | 00:00 | 每周 | 30天 |
策略2 | 00:00 | 每天 | 7天 |
4.6.4 备份管理
4.6.4.1 确认备份策略
产品 | 环境 | 备份策略 | 备注 |
CVM | 容器集群 | 不备份 | |
vpn-ldap-keyclock | 每周六、周一,23:00创建,保留15天 | ||
Mysql | prd | 每天1备,保留30天 | |
dev | 每天1备,保留7天 | ||
PostgreSQL | prd | 每天1备,保留30天 | |
dev | 每天1备,保留7天 | ||
Redis | prd | 每天1备,保留7天 | |
dev | 每天1备,保留7天 | ||
MongoDB | prd | 每天1备,保留7天 | |
dev | 每天1备,保留7天 | ||
ES | prd | 每天1备,保留7天 | |
Clickhouse | prd | 每天1备,保留7天 | |
COS | prd | 暂时只开启版本控制,不开启存储桶复制 |
4.6.4.2 备份回顾
4.6.4.3 备份恢复演练
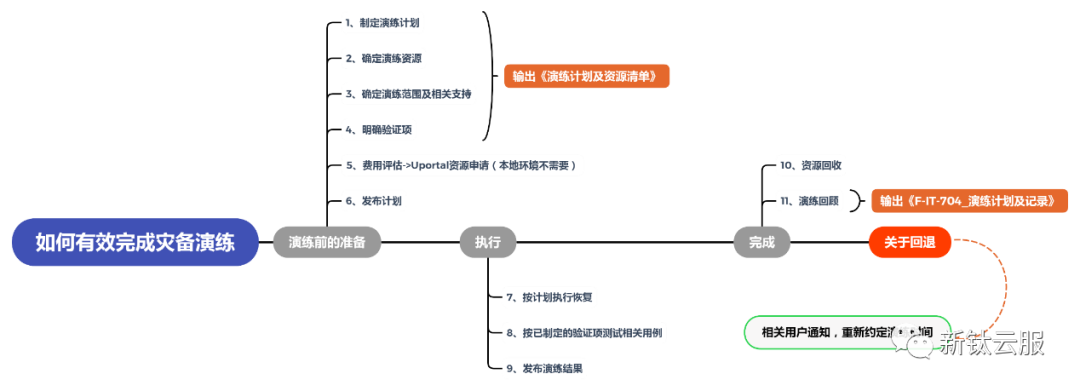
备份恢复是备份的最终目标,为了检查备份成功率可以测试备份恢复过程的可行性和可靠性,以确保在恢复过程中没有遗漏,需要进定期的备份恢复演练,并通过备份恢复演练达到以下目的:
· 验证备份方案:备份恢复演习是验证备份方案是否正确和有效的最佳方式。通过实际演练,可以发现潜在的问题和漏洞,并及时修复。
· 备份恢复效率:实际演练可以帮助企业测试备份和恢复流程的效率,并及时发现和解决流程中的瓶颈和短板,提高备份恢复的效率。
· 避免数据丢失:实际演习有助于验证数据恢复的完整性,以及数据丢失的可能性,从而帮助企业采取必要的措施防止数据丢失。
· 降低业务风险:恢复演习可以帮助企业更好地了解备份运作流程以及在实际灾难发生时该如何恢复数据。这将有助于企业在发生意外情况时,快速、正确地响应并保持业务连续性,降低业务风险。
· 提高员工技能:经过实际演习的员工,可以更加熟练的操作备份和恢复流程,提高员工的技能水平和工作效率。
备份恢复演练过程如下图,需提前准备“演练计划与资源清单”与“演练计划与记录”。
阿里云漏洞和补丁管理规范遵循以下步骤:
4.9 费用管理
4.9.1 费用预算管理
在使用云平台服务之前,需要确定一个费用预算,以避免出现超出预算的情况。并以此为基础,综合评估此业务系统的计算、存储、网络、数据库等云资源配置是否合理,确保费用的合理性和可控性。
4.9.2 费用核对和审计
定期对阿里云的费用订单进行核对和审计,以确保费用的正确性和合规性。如果发现异常的费用,需要及时进行调查和处理。
4.9.3 费用分配和归集
根据业务需求和费用结构,对云平台的费用进行分配和归集,以便更好地管理和控制费用。
4.9.4 费用监控和预警
4.9.5 费用节约与优化
4.10.1 监控事件响应流程
4.10.2 变更流程
4.10.2.1 变更纪律
4.10.2.2 新增资源
申请人 | 部门 | 日期 | |||
申请项目与原因 | |||||
申请的资源 | XXX资源 | 详细信息及配置参数 | |||
网络安全白名单相关需求 | |||||
说明 | |||||
应用负责人签字 | 条线部门经理签字 | ||||
经理签字 | |||||
部门经理签字 |
4.10.2.3 配置变更

推荐阅读


推荐视频
