




当分析数据量很大的时候,有时候我们希望通过某些特点来查询用户或者号码,比如:广东省的所有用户号码可以分组在一起为一个文件,湖北省的所有用户可以分组在一起输出为一个文件,这样在后续分析或统计数据的时候可以方便的查找。之前实现的用户流量统计是逐条读取用户数据,然后全部输出到一个文件中。其实,反编译mapreduce的源码(如下所示),里面有个类HashPartitioner。

默认里面的numReduceTask任务为1的时候,传进来的K-V值,返回的组均为1,因此也就会把所有的结果生成到一个文件。所以,我们可以改写这个源码中的类,实现分组。
文件的分割与读取还是与之前的mapreduce的基本逻辑还是一致,只不过需要添加一个分组的类。将需要分组的类,先缓存在内存中HashMap中,这样从数据库中读取表的数据结果全部缓存在了HashMap里面。
private static HashMap<String,Integer> areaMap = new HashMap<>();
static{
loadTableToAreaMap(areamap);
};
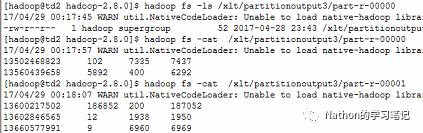
最后,我们将代码打成jar包上传至服务器运行。其结果如下,所示,可以看到,输出的文件结果不再是1个,变成我们改造后的6个组。

文章转载自Nathan的笔记,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
