一、磐维数据库简介
中国移动磐维数据库(ChinaMobileDB),简称“磐维数据库”(PanWeiDB)。是中国移动信息技术中心首个基于中国本土开源数据库openGauss打造的面向ICT基础设施的自研数据库产品。具有高性能、高可靠、高安全、高兼容等特点。
目前磐维 2.0 提供两种部署方式:一种是集中式部署;另一种是分布式部署。两种部署安装方式,可参看以下两篇文字:
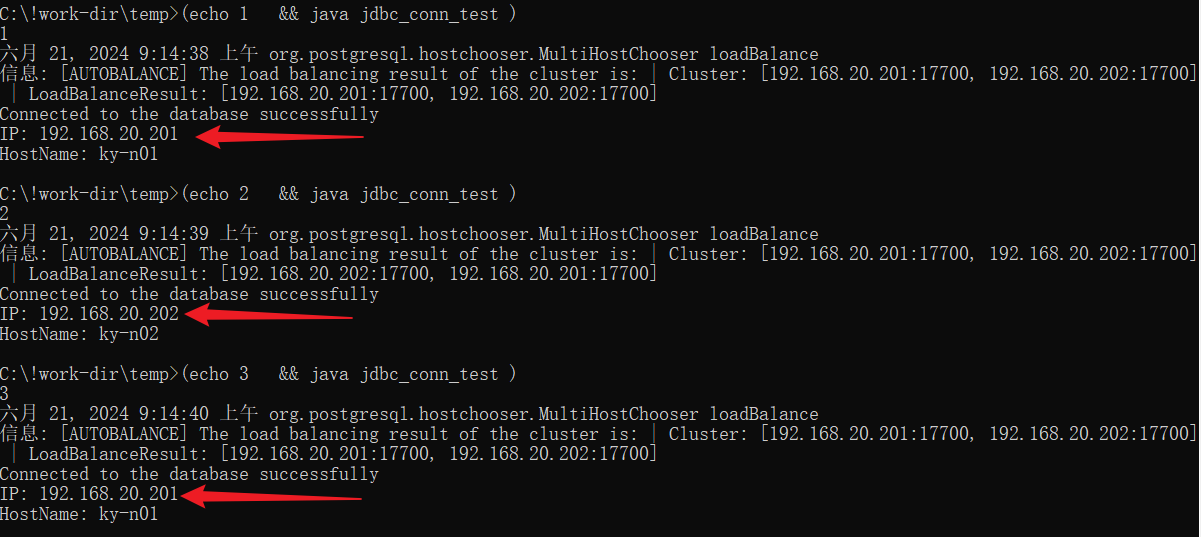
一般在OLTP应用场景中,采用集中式部署,多为一主两备架构的数据库集群。如下所示:
在本篇文字中,介绍通过JDBC访问集中式一主两备磐维数据库集群。
二、JDBC简介
JDBC(Java Database Connectivity,Java数据库连接)是Java语言中用来规范客户端程序如何访问数据库的应用程序接口(执行SQL语句的Java API),可以为多种关系型数据库提供统一访问接口,Java应用程序可通过JDBC访问和操作数据库中的数据。
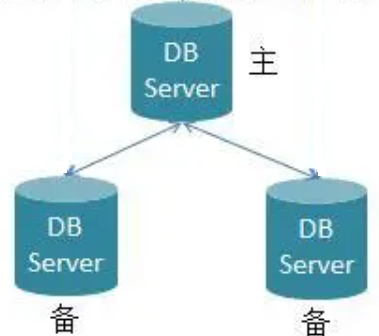
JDBC为访问不同类型的数据库提供了统一的公共接口(一组API),这使得Java程序员不需要针对不同类型的数据库分别开发数据库连接代码,从而大幅简化和加快了开发过程。而且对于Java应用程序,也可以方便的替换底层数据库。JDBC体系架构示意如下:
三、通过VIP访问磐维数据库集群
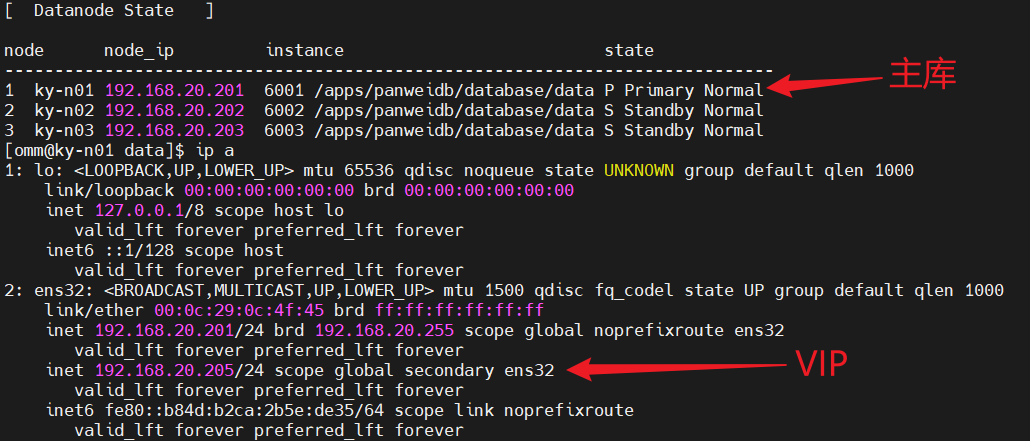
对于一主两备的磐维数据库集群,可以配置VIP(virtual IP address)指向主库,当发生主备库切换时,VIP将自动指向新的主库。这个VIP的功能是通过keepalived实现。大致过程如下:
当主库主机发生故障时,集群会启动故障转移机制,自动完成主备切换,将备库切换为新的主库,保证数据库服务的连续性,从而实现数据库的高可用。
在主备库切换后,keepalived会检测到主备库角色的变化,并将VIP漂动到新的主库所在主机上,使得通过VIP就可以一直访问主库(无论是原主库,还是切换后的新主库)。
通过JDBC连接VIP的url格式如下:
jdbc:postgresql://VIP:port/database_name以下是在主/备库切换情况下,VIP自动漂移的情况:
1、原始情况是VIP在主库所在主机上
如下所示:
2、切换主库后,VIP自动漂移到新的主库上
如下所示:
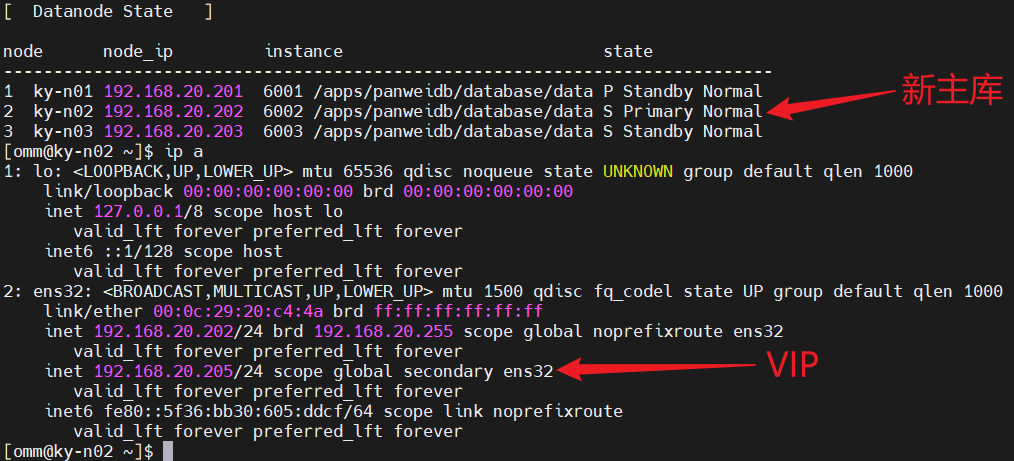
在数据库集群中,VIP会飘浮在主库所在的主机。当主库发生变化时,这个VIP也会随之飘移到新主库上。
客户端通过这个VIP,就可以始终连接到主库,即使是发生主库切换,也无需客户端做配置修改,这是VIP的一个好处。
但是通过这个VIP只能访问主库,却不能访问备库,这样就无法实现对数据库集群的读写分离(即:将写任务分配给主库,将读任务分配给备库,从而实现负载均衡)因此,如果想要实现读写分离的功能,可以通过JDBC多IP连接的方式。(详见下一小节)
四、通过JDBC多IP访问磐维数据库集群
1、JDBC连接多IP的url格式及说明
JDBC连接串参考(推荐使用panweidb驱动):
jdbc:panweidb://host1:port1,host2:port2,host3:port3/database_name?targetServerType=master¤tSchema=schema_name&useUnicode=true&characterEncoding=utf-8也可以使用postgresql驱动:
jdbc:postgresql://host1:port1,host2:port2,host3:port3/database_name?targetServerType=master¤tSchema=schema_name&useUnicode=true&characterEncoding=utf-8说明:
(1)host1:port1,host2:port2,host3:port3分别是数据库集群三节点主机的IP和数据库服务端口号;
(2)targetServerType=master 用于指定连接主库,此参数共有四种值:
- any(此为默认值),表示尝试连接URL连接串中的任何一个数据节点。
- master 尝试连接到URL连接串中的主库节点,如果找不到就抛出异常。
- slave 尝试连接到URL连接串中的备库节点,如果找不到就抛出异常。
- preferSlave 尝试连接到URL连接串中的备库节点(如果有可用的话),否则连接到主库节点。
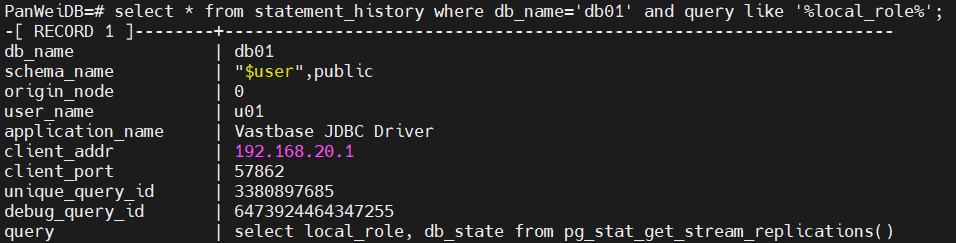
判断主/备库是通过执行以下SQL实现的:select local_role, db_state from pg_stat_get_stream_replications();
这个可以通过开启参数"track_stmt_stat_level='L0,L0'",并查看statement_history来获取。
(3)currentSchema=schema_name 设置当前连接的schema(一般为业务数据所在的schema),如果未设置,则默认schema为连接使用的用户名。这个schema_name是在“search-path”中指定要设置的schema。
(4)useUnicode=true&characterEncoding=utf-8 用于指定字符的编码方式和解码方式,防止因字符集不同而产生乱码。
2、Java程序代码及执行结果验证
(1)主要的Java程序代码
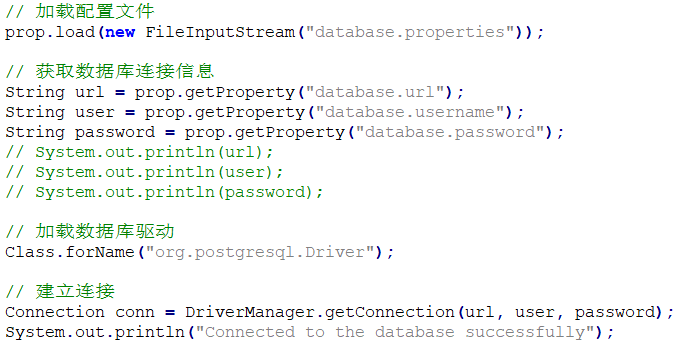
编制Java测试验证程序,思路是从配置文件中读取要连接数据库的相关参数,然后根据这些连接参数,按多IP的方式去连接数据库,并查看和验证在不同的“targetServerType”设置下,Java程序连接的是哪个节点。
主要Java代码如下:
配置文件内容如下:

(2)执行结果验证
查看数据库集群中,哪个是主库:

测试targetServerType=master的连接情况,结果如下:
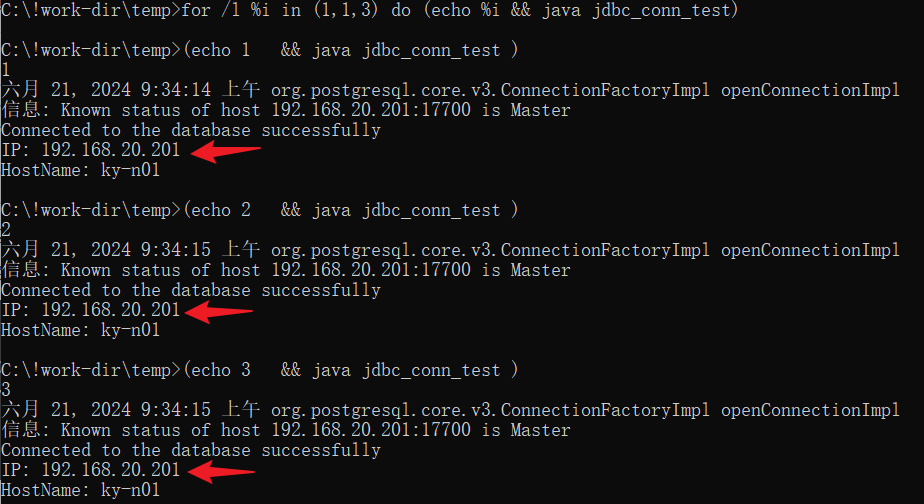
测试targetServerType=slave的连接情况,结果如下:
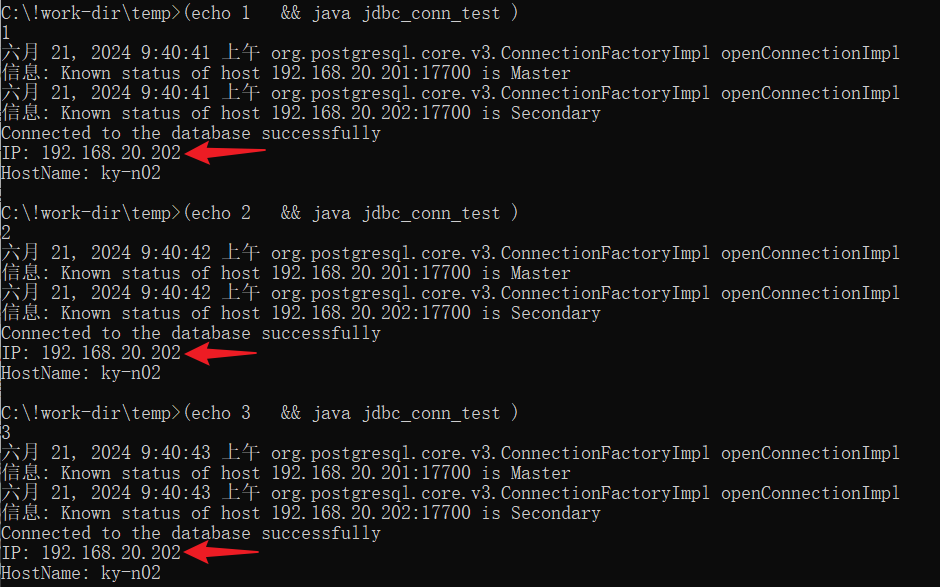
将主库由1节点切换到2节点后,再测试targetServerType=master的连接情况,结果如下:


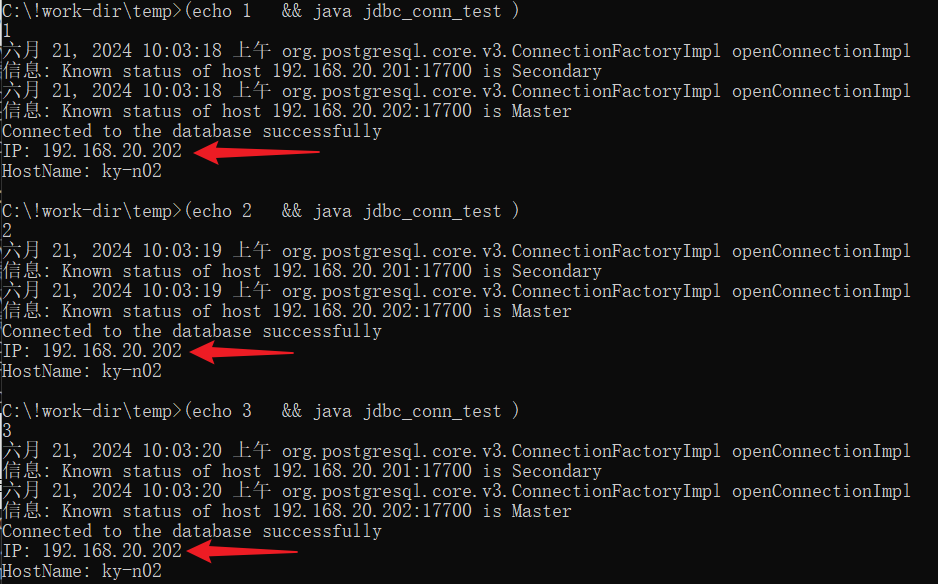
五、读写分离与负载均衡
1、读写分离
思路:通过设置JDBC的url中的targetServerType参数值为master或slave,来控制连接的是主库还是备库,对于写操作就指向主库,对于读操作就指向备库,从而实现读写分离的目的。
2、负载均衡
对于一套集中式数据库集群(包含1主2备三个节点:node1,node2,node3),其中node1为主节点,node2、node3为备节点。
如果希望同一应用程序上建立的连接,较为均匀的分布在三个节点上,则JDBC的url可参考如下配置:
jdbc:postgresql://node1,node2,node3/database?loadBalanceHosts=true注意: 使用loadBalanceHosts时,若连接建立在备库上,将无法执行写操作。如果业务需要执行读写操作,请勿配置该参数。
通过JDBC连接数据库,负载均衡的测试: