





安装 TuGraph
docker pull tugraph/tugraph-runtime-centos7:latestmkdir -p tmp/tugraph/data && mkdir -p tmp/tugraph/log && \docker run -it -d -p 7001:7001 -p 7070:7070 -p 7687:7687 -p 8000:8000 -p 8888:8888 -p 8889:8889 -p 9090:9090 \-v tmp/tugraph/data:/var/lib/lgraph/data -v tmp/tugraph/log:/var/log/lgraph_log \--name tugraph_demo tugraph/tugraph-runtime-centos7:latest bin/bash && \docker exec -d tugraph_demo bash setup.shpip install "neo4j>=5.20.0"
.env设置
TuGraph配置
GRAPH_STORE_TYPE=TuGraphTUGRAPH_HOST=127.0.0.1TUGRAPH_PORT=7687TUGRAPH_USERNAME=adminTUGRAPH_PASSWORD=xxx
使用知识图谱创建知识空间
构建成功后显示知识图谱关系
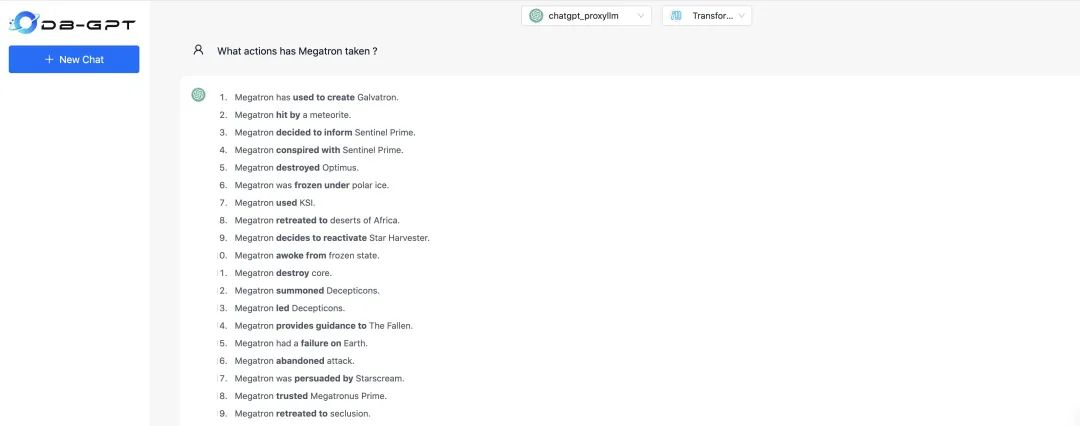
使用知识图谱进行问答
ollama pull qwen:0.5b
ollama pull nomic-embed-text
pip install ollama
.env 配置环境
LLM_MODEL=ollama_proxyllmPROXY_SERVER_URL=http://127.0.0.1:11434PROXYLLM_BACKEND="qwen:0.5b"PROXY_API_KEY=not_usedEMBEDDING_MODEL=proxy_ollamaproxy_ollama_proxy_server_url=http://127.0.0.1:11434proxy_ollama_proxy_backend="nomic-embed-text:latest"
python dbgpt/app/dbgpt_server.py
Agent 核心模块重构 根据论文 《A survey on large language model based autonomous agents》 [1] 将 Agent 模块代码重构为四个核心模块
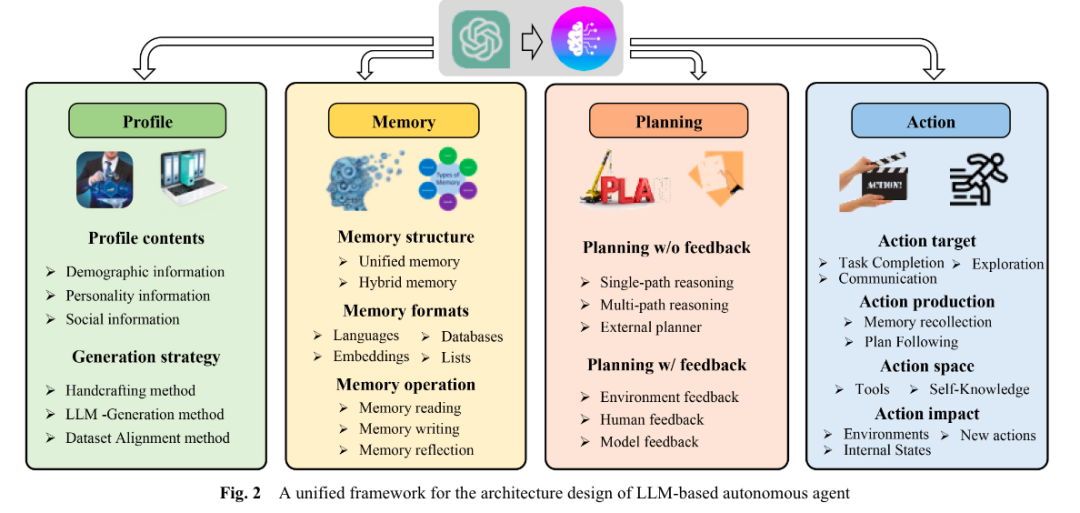
更灵活的 Profile
模块实现,支持从环境变量、数据库和其他实现创建 agent profiles支持多种 memory 模式, sensory memory
,short-term memory
,long-term memory
andhybrid memory
Agent Resource
模块重构
将插件模块和资源模块重构为统一的资源模块 Agent中有多种 Resource
类型,包括database, knowledge, tool, pack等。另外,资源的集合是一种特殊类型的资源,称为Resource Pack支持从 dbgpts
中安装资源,例如使用下面命令安装一个简单计算器工具dbgpt app install simple-calculator-example -U
examples/agents🌟 ChatKnowledge
支持 rerank
模型,同时支持将 rerank
模型发布成服务
.env文件设置模型参数并重启服务
## Rerank modelRERANK_MODEL=bge-reranker-base## If you not set RERANK_MODEL_PATH, DB-GPT will read the model path from EMBEDDING_MODEL_CONFIG based on the RERANK_MODEL.# RERANK_MODEL_PATH=## The number of rerank results to returnRERANK_TOP_K=3
dbgpt start controller --port 8000dbgpt start worker --worker_type text2vec \--rerank \--model_path app/models/bge-reranker-base \--model_name bge-reranker-base \--port 8004 \--controller_addr http://127.0.0.1:8000
.envLLM_MODEL=deepseek_proxyllmDEEPSEEK_MODEL_VERSION=deepseek-chatDEEPSEEK_API_BASE=https://api.deepseek.com/v1DEEPSEEK_API_KEY={your-deepseek-api-key}
test_proxyllm.pyDeepseekLLMClientimport asynciofrom dbgpt.core import ModelRequestfrom dbgpt.model.proxy import DeepseekLLMClient# You should set DEEPSEEK_API_KEY to your environment variablesclient = DeepseekLLMClient()print(asyncio.run(client.generate(ModelRequest._build("deepseek-chat", "你是谁?"))))
DEEPSEEK_API_KEY={your-deepseek-api-key}python test_proxyllm.py
.env# [Yi-1.5-34B-Chat](https://huggingface.co/01-ai/Yi-1.5-34B-Chat)LLM_MODEL=yi-1.5-6b-chat# [Yi-1.5-9B-Chat](https://huggingface.co/01-ai/Yi-1.5-9B-Chat)LLM_MODEL=yi-1.5-9b-chat# [Yi-1.5-6B-Chat](https://huggingface.co/01-ai/Yi-1.5-6B-Chat)LLM_MODEL=yi-1.5-34b-chat
Chroma向量数据库模块
Elasticsearch作为向量数据库
ChatKnowledge支持 Excel
修复在 EmbeddingRetriever
使用CrossEncoderRanker
问题修复 app pydantic error 支持 milvus autoflush 特性, 替换掉手动 flush
引用链接
[1]
《A survey on large language model based autonomous agents》 : https://link.springer.com/article/10.1007/s11704-024-40231-1

文章转载自EosphorosAI,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
