





2023 年 Large Language Model 发展得如火如荼,各大模型的更新、发布更是层出不穷,模型输出的内容如何给用户带来更优的表达显得尤为重要。除了最基础的文本、列表、表格,LLM 也都可以输出代码、图片、图表等形式的内容。目前 LLM 的输出基本都遵循了 markdown 协议,基于 markdown 语法的 LLM to Vision 的标准和渲染规范显得尤为重要。
在开始讲 LLM Vision 内容之前,先来看几个展示案例。
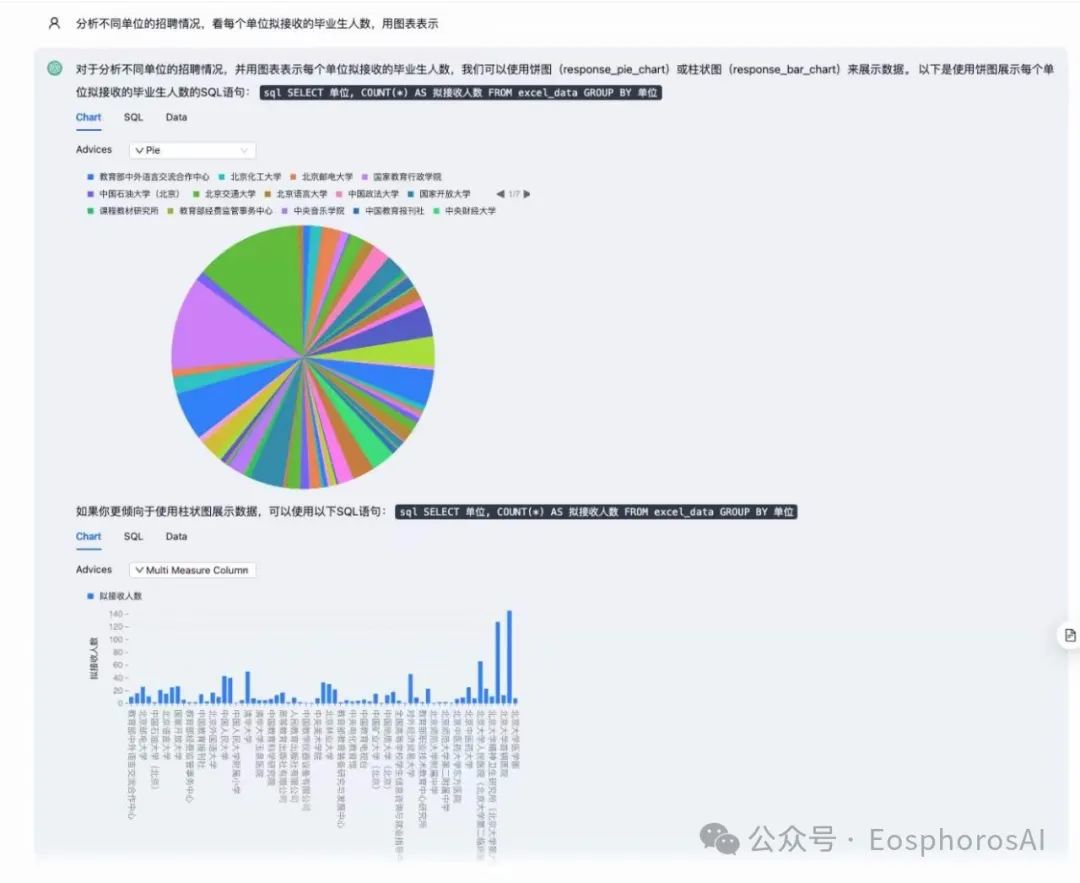
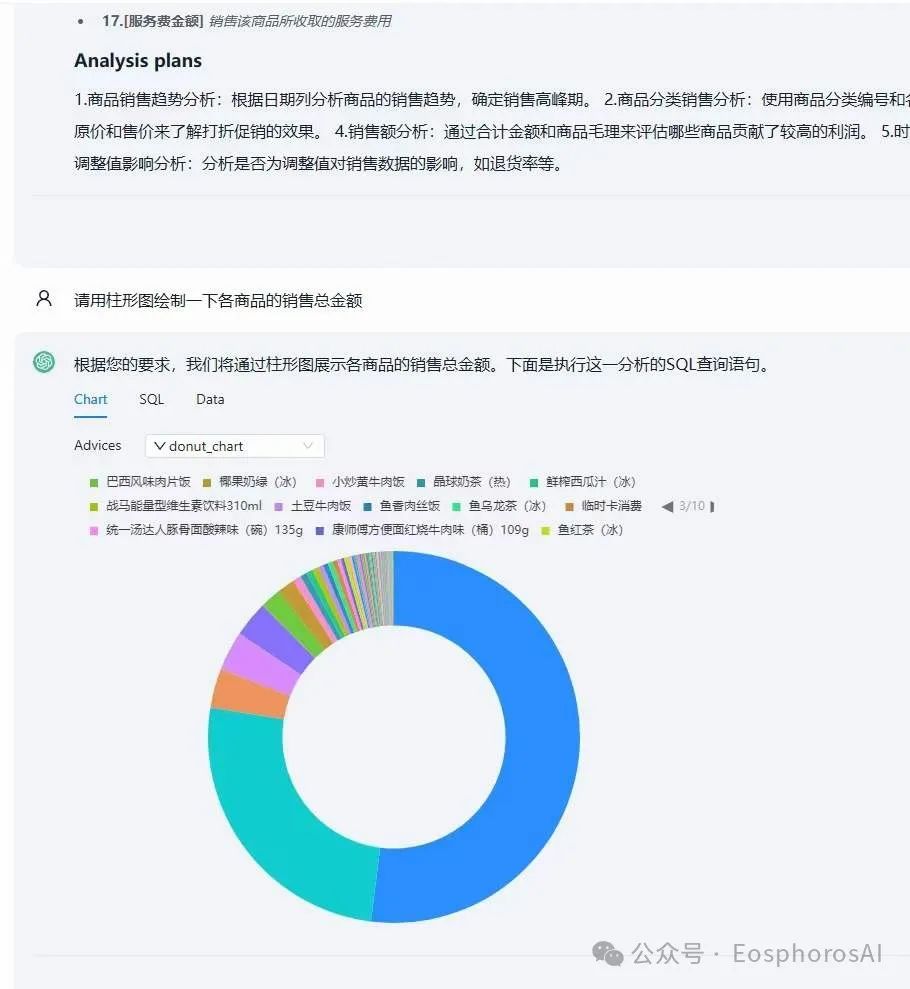
LLM 只需输出一份数据,做前端智能图表推荐,满足丰富图表内容可视化,同时支持图表、SQL、表格切换展示。
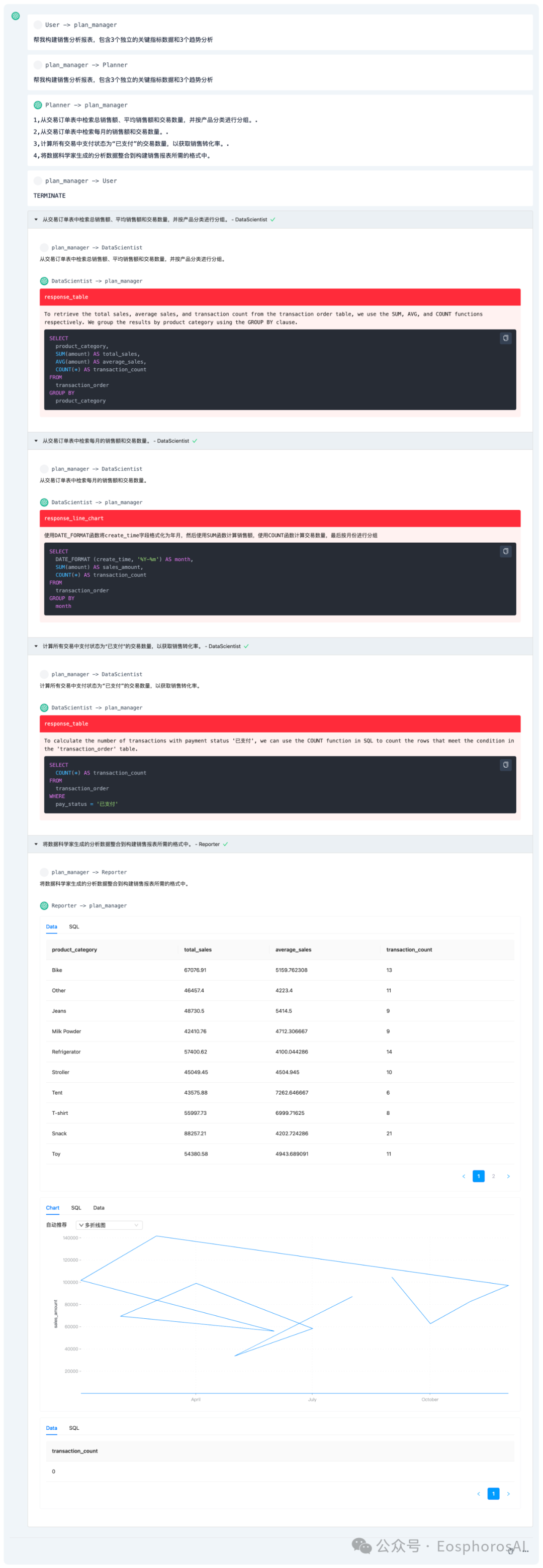
Agent 智能体处理复杂任务的可视化。
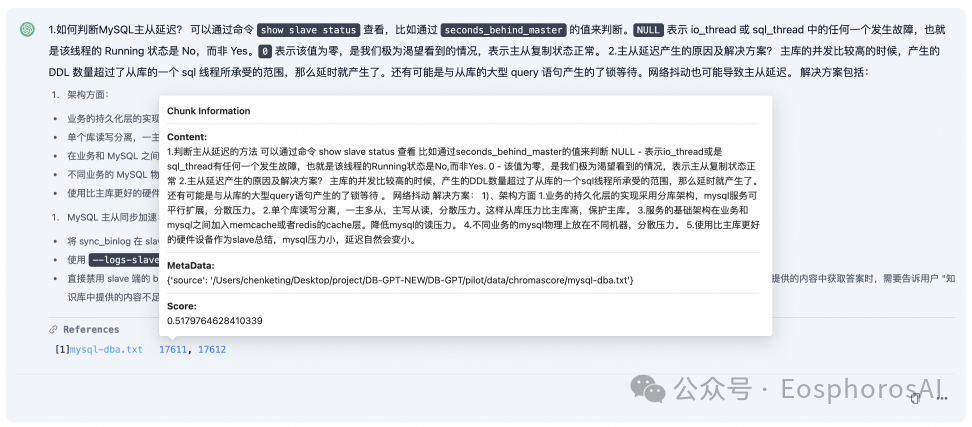
RAG 文档总结与召回 Top K 展示。
从以上的例子可以简单的概括出:LLM Vision 就是对模型的输出结果,进行合理、准确的可视化并展现给用户。
因为大模型输出的内容,通常是 markdown 格式或是 xml 标签格式,所以在前端渲染组件上,我们采用 react-markdown 组件作为内容展示的基础组件,并按需扩展组件。
在初期讨论标签该采用哪种协议时,提出了两种方案:
(1)多层自定义标签
<plguin-view><name>插件名称</name><status>运行状态</status><result>LLM返回的内容</result></plguin-view>
(2)单层自定义标签 + json序列化
<plugin-view>{"name":"插件名称","status":"complete","result":"LLM返回的内容"}</plugin-view>
以上两种方案,经过研究并结合 react-markdown 组件(以下简称“RM”)对标签处理的结果后发现:
多层自定义标签:在 RM 的处理中,每个闭合标签都会被当成节点处理,这样并不利于我们通过最外层的结构去解析里面的内容,所以不适合。❌
单层自定义标签 + json:单层自定义的方式加上 RM 处理后输出的标签,结构相对简单很多,更有利于我们后续将标签进行 json 反序列化,处理成想要的数据格式。✅
在标签协议 1.0 中,我们将序列化后的 json 字符串放到自定义标签的内容中,再利用 react-markdown 中的 components 属性去实现标签处理的逻辑。
<plugin-view>{"name":"插件名称","status":"complete","result":"LLM返回的内容"}</plugin-view>
2.1 代码示例
import ReactMarkdown from 'react-markdown';type MarkdownComponent = Parameters<typeof ReactMarkdown>['0']['components'];export const markdownComponents = {'plugin-view'({ children }) {try {const data = JSON.parse(String(children));return <div></div>} catch(e) {return children;}}
import ReactMarkdown from 'react-markdown';import { markdownComponents } from './config';function LLMContent() {const [content] = useState('');return <ReactMarkdown components={markdownComponents}>{content}</ReactMarkdown>;}export default LLMContent;
2.2 Tip:使用 ts 时可以在 global.d.ts 中声明自定义标签类型,在开发中有较好的语法提示
declare namespace JSX {interface IntrinsicElements {'plugin-view': React.DetailedHTMLProps<React.HTMLAttributes<HTMLElement>,HTMLElement>;}}
2.3 实际应用中发现,该协议存在较多的问题:
内容被换行了,导致 json 解析失败;
json 中的 " 引号没有正常转译会导致失败;
大多数情况下,我们并不知道大模型最终输出的内容是什么,可能是纯文本也可能包含 markdown 语法,这样会导致标签中的 markdown 语法提前被 react-markdown 解析成节点,使得我们在处理标签内容时,无法按照约定的 json 协议去解析数据。
由于 1.0 协议中,存在像内容包含 markdown 语法时会被 react-markdown 组件提前解析成节点的问题,我们尝试了第二种方案:用标签属性传值来代替内容传值。
经研究后发现:使用标签属性传值,标签属性中的内容不会被 react-markdown 处理,这样便可解决 1.0 协议中内容被换行、markdown 内容被提前解析的问题。
3.1 示例
<plugin-viewtitle=""status="completed"result="{"name":"","status":"","result":""}"></plugin-view>
但同时也引入了新的问题:
放在属性中的
"
需要转译成"
;如果返回的标签,不是闭合标签
<plugin-view content="" >
,这样会导致标签内容匹配异常
3.2 思考
难道没有一种方案,既不需要对字符进行转译,又能保证内容不被 react-markdown 过早解析的吗?
显然有的,协议 3.0 它来了~
在 markdown code语法中,内容并不会被深层解析成元素节点,序列化后的内容也不需要关心是否被换行,且语言类型判断简单,很符合我们的需求。
```plugin-view{"name": "插件名称","status": "completed","result": "LLM返回的内容"}```
4.1 示例
创建展示组件
interface Props {data: {name: string;status: 'completed' | 'todo' | 'wating';result: string;}}function PluginView({ data }: Props) {return <div></div>;}export default PlguinView;
处理自定义 code 语言
import ReactMarkdown from 'react-markdown';type MarkdownComponent = Parameters<typeof ReactMarkdown>['0']['components'];export const markdownComponents = {code({ className, children }) {const lang = className?.replace('language-', '');if (lang === 'plugin') {try {const data = JSON.parse(String(children));return <PluginView data={data} >} catch(e) {return children;}}}}
渲染组件
import { markdownComponents } from './config.tsx';import ReactMarkdown from 'react-markdown';function LLMContent() {const [content] = useState('');return <ReactMarkdown components={markdownComponents}>{content}</ReactMarkdown>;}export default LLMContent;
4.2 灵活性
我们可以跟后端同学约定好,在每个对象中有一个 markdown 的属性,这个属性代表大模型的输出内容。同时这里面的内容也包含了其他的自定义 code 语言,这样我们就可以实现多嵌套解析了,Muilt-Agent 就是一个很好的嵌套解析例子。
```plguin-view{"name": "","status": "","markdown": "```message\n{\"sender\":\"\",\"content\":\"\"}\n```"}```
改造代码示例
## 文件名:PluginView.tsximport { markdownComponents } from './config.tsx';import ReactMarkdown from 'react-markdown';interface Props {data: {name: string;status: 'completed' | 'todo' | 'wating';markdown: string;}}function PluginView({ data }: Props) {return (<div><div>{data.name}</div><ReactMarkdown components={markdownComponents}>{data.markdown}</ReactMarkdown></div>);}export default PlguinView;
## 文件名:MessageView.tsxinterface Props {data: {sender: string;content: string;}}function MessageView({ data }: Props) {return <div>{data.sender}: {data.content}</div>;}export default PlguinView;
## 文件名:config.tsximport ReactMarkdown from 'react-markdown';import PluginView from './PluginView';import MessageView from './MessageView';type MarkdownComponent = Parameters<typeof ReactMarkdown>['0']['components'];export const markdownComponents = {code({ className, children }) {const lang = className?.replace('language-', '');if (lang === 'plugin-view') {try {const data = JSON.parse(String(children));return <PluginView data={data} >} catch(e) {return children;}}if (lang === 'message') {try {const data = JSON.parse(String(children));return <MessageView data={data} >} catch(e) {return children;}}}}
以上提及的自定义协议处理,都是基于后端同学能够正常处理协议格式、以及确保按照markdown标准语法返回来促成的。
随着大模型的不断迭代更新,我们应该继续深入思考:内容该如何为用户带来更准确的表达与展示。
我们不仅仅只追求 UI 上的美化,更重要的是如何准确表达和展示内容,降低用户对大模型输出的结果所带来的心智负担,帮助其清晰、准确的理解模型输出的结论是什么。
而协议的制定,则是整个表达的基础。同时让我们在开发过程中,能更加灵活的定制组件、在处理数据的方式上有更多的可能性。
https://github.com/eosphoros-ai/DB-GPT
https://github.com/eosphoros-ai/DB-GPT-Hub
https://github.com/eosphoros-ai/DB-GPT-Web
以上文章整理自之前的征文大赛,作者是个塔,感兴趣可以点击阅读原文跳转查看原文哦。
