亲爱的开发者们,我们很高兴宣布,DB-GPT 社区又迎来了新的合作伙伴。InternLM (书生·浦语)大模型与 DB-GPT 社区 (eosphoros-ai) 正式达成合作。

InternLM 是上海 AI 实验室与商汤联合发布的通用大模型,包括书生·多模态、书生·浦语和书生·天际等三大基础模型,以及面向大模型研发与应用的全链路开源体系。书生大模型坚持以创新引领技术进步,以开源开放赋能创新生态的理念与 DB-GPT 社区的开源理念高度契合,我们共同相信大模型的能力、LLMOps 相关框架、微调框架、评测体系、Text2SQL 准确性等在内的许多技术将成为新时代的基础设施,也将共同携手合作和探索。
当我们将目光聚焦在围绕数据库与大模型构建海数精算,笔笔洞察的时候,发现面对私域知识与数据,还有非常多应试与感性的诉求。比如基于 DB-GPT 搭建一套自动出题与阅卷系统或者在吟诗作赋、对对联等符合人类道德与价值观以及微调后带有情感的回复能力,而这些正是 InternLM (书生·浦语)之所长。
此次与 InternLM 大模型体系达成合作,可以进一步助力我们围绕数据构建大模型领域的基础设施,全面构建理能海数精算、笔笔洞察,文能吟诗作赋、诗情画意的能力。同时我们万分期待后续 InternLM (书生·浦语)大模型更深度的合作,面向未来,当我们沉浸在数字化的大厦当中,即便被数据包围,我们依然可以面朝大海,享受诗与远方。

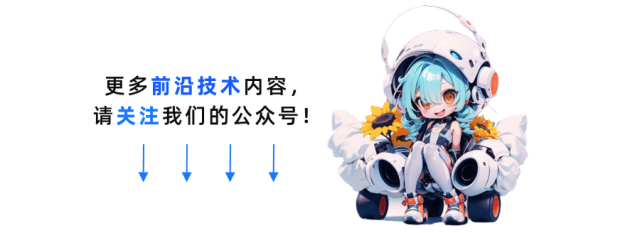
DB-GPT 是围绕大模型与数据库最通用,最流行的框架。在技术生态上从产品、框架、底层模型效果实现了全方位覆盖。在框架本身构建上提供了 Serverless 的多模型管理能力,支持多模型的生命周期管理以及场景切换。同时 DB-GPT 多模型管控的能力,可以按集群模式进行部署。
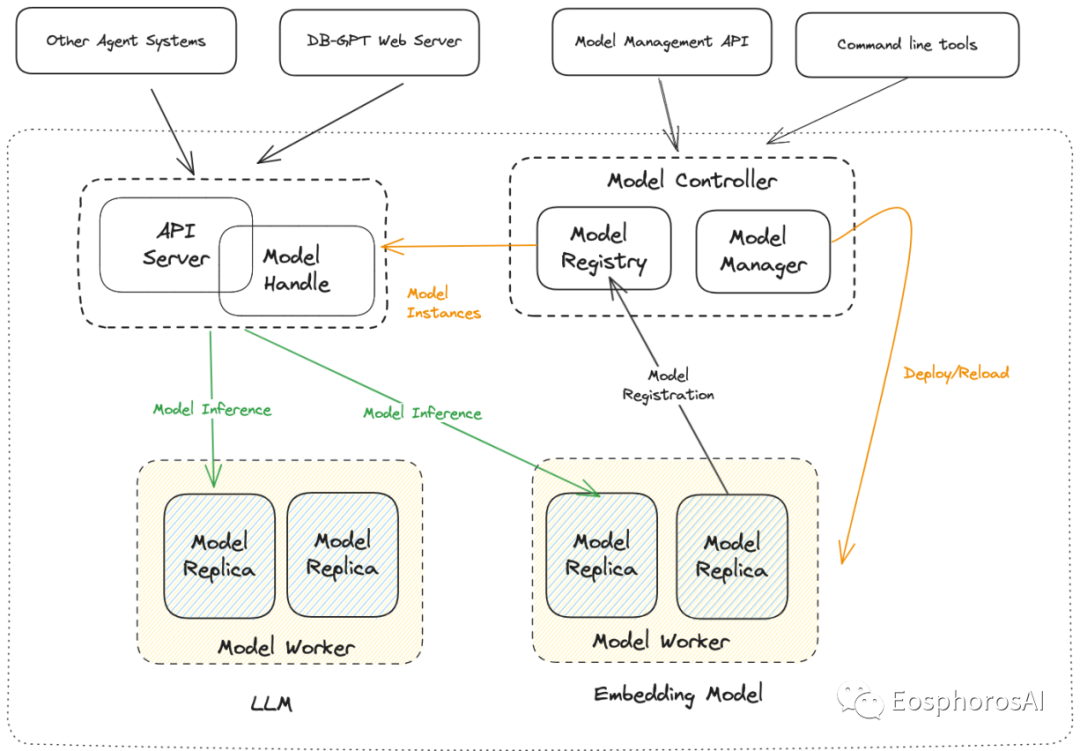
实际业务落地过程中,在 BaseModel 之上针对垂直领域的任务,会衍生出很多的小模型,同样数据库这个领域也是如此,会有 Text2SQL 的模型、Text2API 的模型、Text2Tool 的模型等等。在使用时,则可以通过场景配置进行多模型切换。
DB-GPT在多模型的管理方面主要提供命令行与界面白屏化管理两种方式。下面主要介绍下如何通过命令行进行多模型管理。
DB-GPT 多模型管理是 Controller 与 Worker 的管理机制。
1. 运行 Controller
# 在运行之前需要首先安装命令pip install -e .# 运行controller服务dbgpt start controller

2. 运行模型服务,并注册到 Contoller 当中
dbgpt start worker --model_name internlm-chat-7b-v1_1 \--model_path app/models/internlm-chat-7b-v1_1 \--port 8001 \--controller_addr http://127.0.0.1:8000
我们同时支持其他版本的 InternLM 模型,只需通过命令注册到模型服务,即可在后续的场景中进行使用。比如我们继续运行 8k 上下文的模型,并注册到模型服务。
dbgpt start worker --model_name internlm-chat-7b-8k \--model_path app/models/internlm-chat-7b-8k \--port 8001 \--controller_addr http://127.0.0.1:8000dbgpt model list
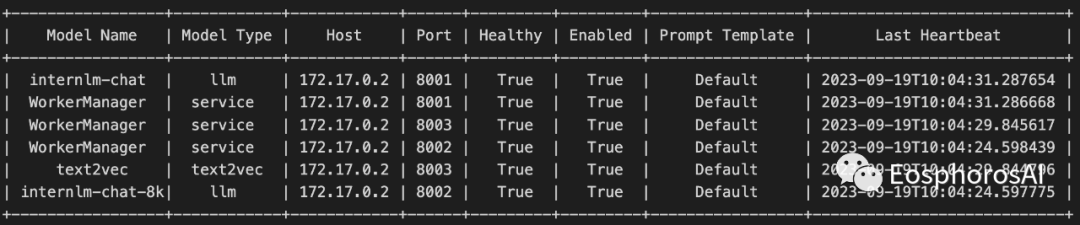
更多操作命令可以通过运行 dbgpt --help
查看
dbgpt --helpUsage: dbgpt [OPTIONS] COMMAND [ARGS]...Options:--log-level TEXT Log level--version Show the version and exit.--help Show this message and exit.Commands:install Install dependencies, plugins, etc.knowledge Knowledge command line toolmodel Clients that manage model servingstart Start specific server.stop Start specific server.
部署好模型后,我们即可通过 DB-GPT 提供的知识库、插件、数据分析等能力使用 InternLM 模型。
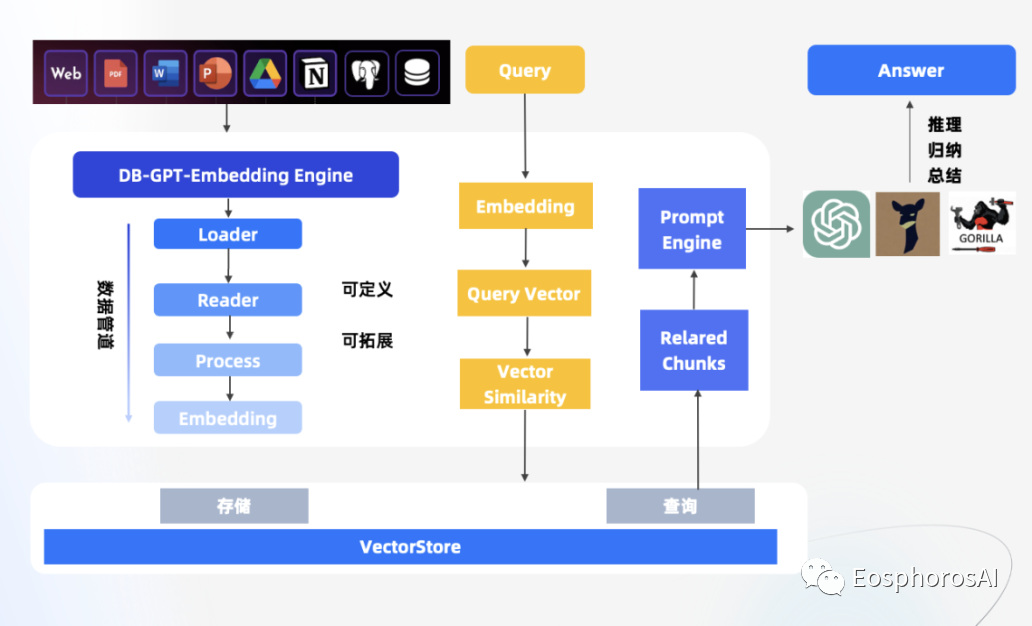
此种模式在知识库问答里面属于端对端模式,是对传统的两阶段方法知识问题的升级。传统两阶段方法主要分为召回阶段和阅读理解阶段。召回阶段中,使用传统的 TF-IDF 的方式返回评分最高的 top-k 个文章片段。阅读理解阶段中,采用神经网络模型 RNN 将问题转化为序列标注问题,即对于给定文档中出现的每个词,判断是否出现在答案中。
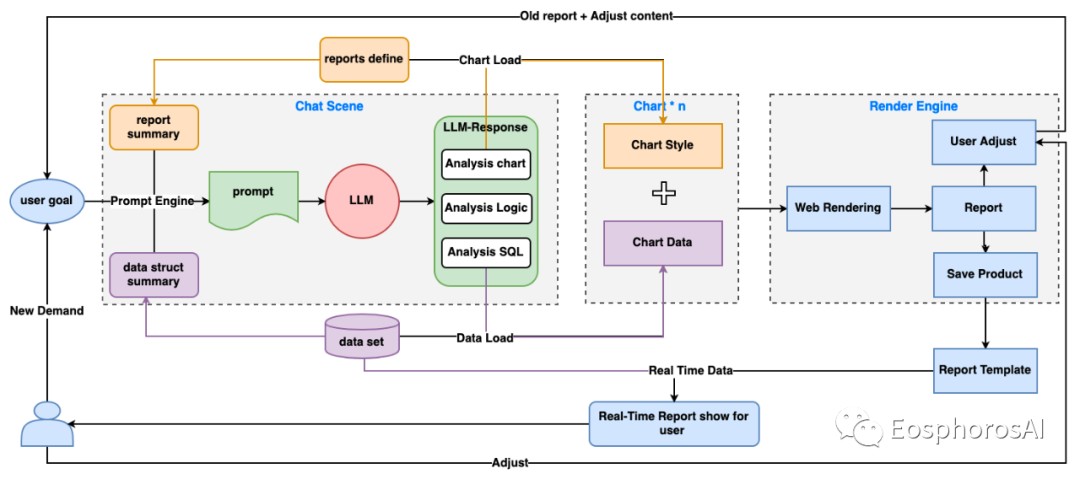
大模型时代外挂本地知识库的流程可以描述为如下所示,整个过程可以分为九个步骤:
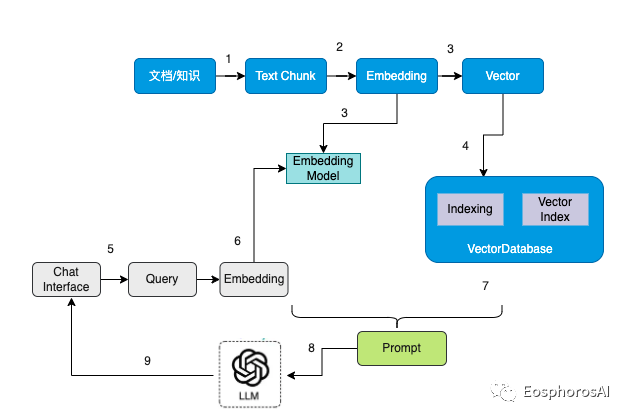
文档/知识切分成 Text chunk
加载 Embedding 模型
通过 Embedding 模型将 text chunk 转换为向量
将向量数据写入到向量数据库中
用户通过 ChatUI 发起一次查询
查询内容通过 Embedding 转换为向量
通过相似度匹配,在向量数据库中检索相似的内容
根据查询到的内容以及 Query 组装对应的 Prompt
将 Prompt 给到大模型进行整理总结,给出最后的回答
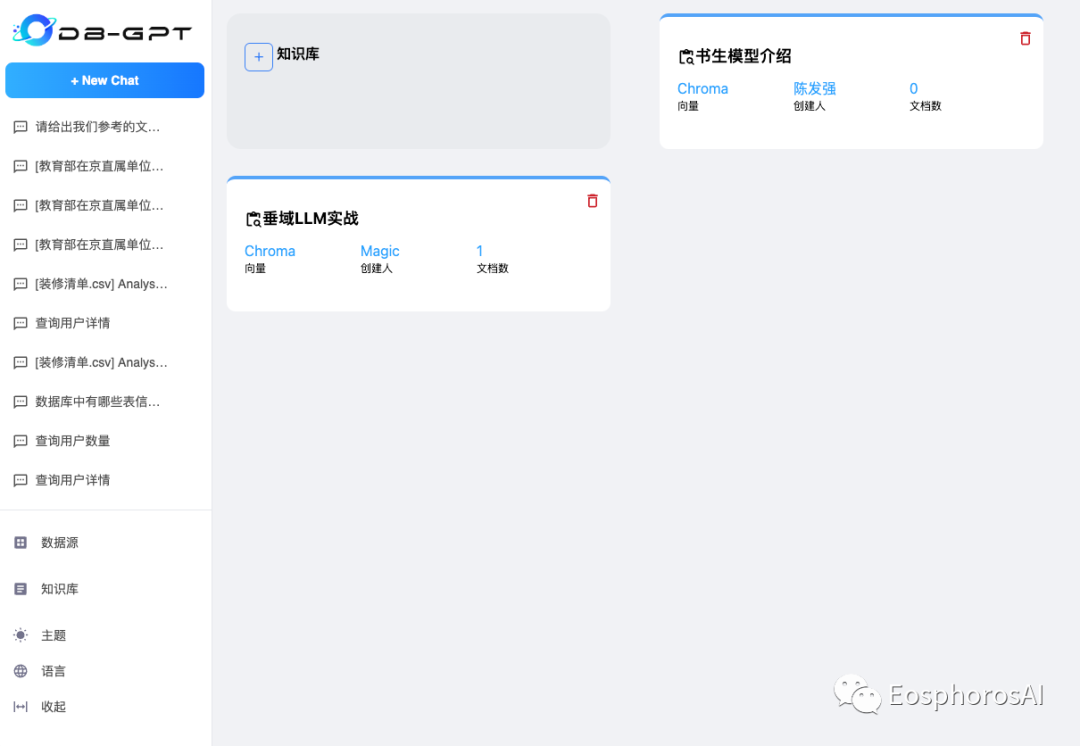
目前 DB-GPT 私域知识问答能力已支持了 txt、pdf、markdown、html、doc、ppt、csv 等多种文档类型,并在知识库管理上提供了知识空间 ( Knowledge Space ) ,只需要在使用时将文档、数据上传到知识空间做向量化,即可以愉快地使用啦。
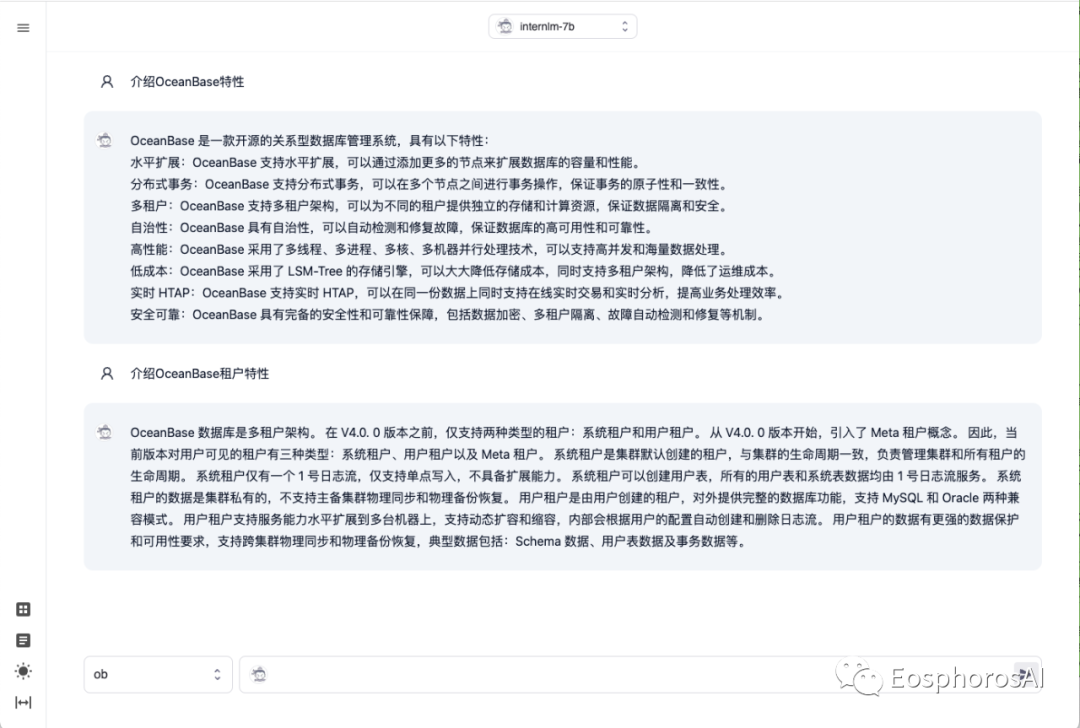
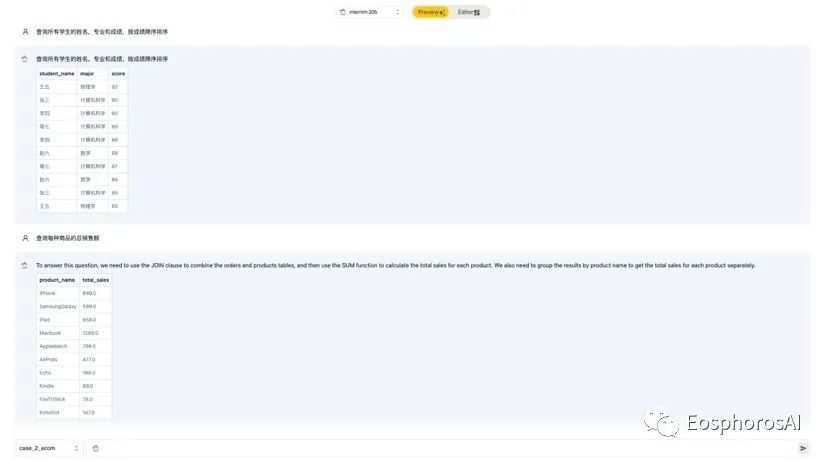
DB-GPT 支持基于 InternLM 的 Text2SQL 微调。在 DB-GPT-Hub 项目中,我们提供了从数据处理、模型微调、模型预测、模型部署一整套的能力,可以通过我们的项目丝滑进行 InternLM 的模型效果微调。
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \--model_name_or_path internlm-chat-7b-v1_1\--do_train \--dataset example_text2sql \--max_source_length 1024 \--max_target_length 512 \--template default \--finetuning_type lora \--lora_rank 32 \--lora_alpha 64 \--lora_target W_pack \--output_dir path_to_sft_checkpoint \--overwrite_cache \--per_device_train_batch_size 4 \--gradient_accumulation_steps 4 \--lr_scheduler_type cosine \--logging_steps 10 \--save_steps 1000 \--learning_rate 5e-5 \--num_train_epochs 6.0 \--plot_loss \--fp16
更多详细信息,请参照我们的微调项目,同时也非常欢迎参与贡献。
随着大模型越来越丰富,越来越强,如何实现业务落地与增长是一个重要的课题。此次双方的合作,将充分发挥各自的技术优势,相互弥补各自差异化的能力,共同打造丰富活跃的社区生态,为业务早日落地提供技术与社区生态基础。我们也非常欢迎,更多的同学参与到社区的建设中,与我们一起打造更好的社区,构建更强的技术。