传感器或监控数据支持从Kafka写入时序表。Kafka和Uqbar可通过Kafka JDBC Connector进行连接。该连接器负责从Kafka读取数据,然后将消息中的SQL发送到Uqbar执行并记录失败消费结果,维护消息消费位置。向数据库插入数据需要使用批量插入模式。

安装流程
下载Kafka
访问 Kafka官网 下载Kafka软件包,下载完成后解压。
下载数据库驱动
下载对应数据库的JDBC驱动,以openGauss为例。访问openGauss官网下载对应操作系统的JDBC驱动。
下载完成后解压,得到相应的JAR包。
复制JAR包到kafka路径下,例如/kafka_2.12-3.2.1/libs。
下载Kafka JDBC Connector
可通过访问https://www.confluent.io/hub/confluentinc/kafka-connect-jdbc?_ga=2.140576818.1269349503.1660542741-1354758524.1659497119,点击“Download”下载Kafka JDBC Connector。
下载完成后解压到任意目录供后续使用。
修改配置文件
server.properties
编辑kafka目录下的 config/server.properties 文件。
listeners=PLAINTEXT://0.0.0.0:9092 advertised.listeners=PLAINTEXT://your.host.name:9092
修改或添加 listeners=PLAINTEXT://0.0.0.0:9092 ,否则将无法监听外网请求。
修改或添加 advertised.listeners=PLAINTEXT://your.host.name:9092 ,your.host.name为本机的IP地址,否则外部网络将无法访问您的kafka。
connect-distributed.properties
编辑kafka目录下的 config/connect-distributed.properties 文件。
plugin.path=/usr/local/Cellar/confluentinc-kafka-connect-jdbc-10.5.2
plugin.path存放confluentinc-kafka-connect-jdbc文件夹的位置。如plugin.path=/usr/local/Cellar/confluentinc-kafka-connect-jdbc-10.5.2。
启动Kafka
-
打开cmd/terminal并进入kafka目录,例如/kafka_2.12-3.2.1。
cd /usr/local/Cellar/kafka_2.12-3.2.1 -
启动zookeeper。
sh bin/zookeeper-server-start.sh config/zookeeper.properties -
启动Kafka。
sh bin/kafka-server-start.sh config/server.properties -
输入jps查看zookeeper和kafka启动情况。
81243 QuorumPeerMain #Zookeeper 30701 Launcher 81598 Kafka # Kafka -
启动Kafka Connect Worker。
sh bin/connect-distributed.sh config/connect-distributed.properties如果显示如下回显信息,表示启动成功。

通过jps可以查看到ConnectDistributed进程运行。
83931 ConnectDistributed -
启动JDBC Connector。
-
方式一:启动JDBC Connector
通过终端或cmd 启动JDBC Connector。
解释curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{ "name":"connector-name", "config":{ "connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector", "connection.url":"jdbc:opengauss://localhost:15432/OpengaussDB", "connection.user":"user", "connection.password":"password", "topics":"test_topic", "insert.mode": "insert", "table.name.format":"table_name_${topic}", "auto.create":true, "dialect.name": "PostgreSqlDatabaseDialect" } }' -
方式二:创建json文件配置 JDBC Connector。
创建名为
test.json的json文件,内容如下:解释{ "name":"connector-name", "config":{ "connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector", "connection.url":"jdbc:opengauss://localhost:15432/OpengaussDB", "connection.user":"user", "connection.password":"password", "topics":"test_topic", "insert.mode": "insert", "table.name.format":"table_name_${topic}", "auto.create":true, "dialect.name": "PostgreSqlDatabaseDialect" } }在终端或cmd启动Kafka。
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d @test.json -
方式三:使用Postman等接口测试工具
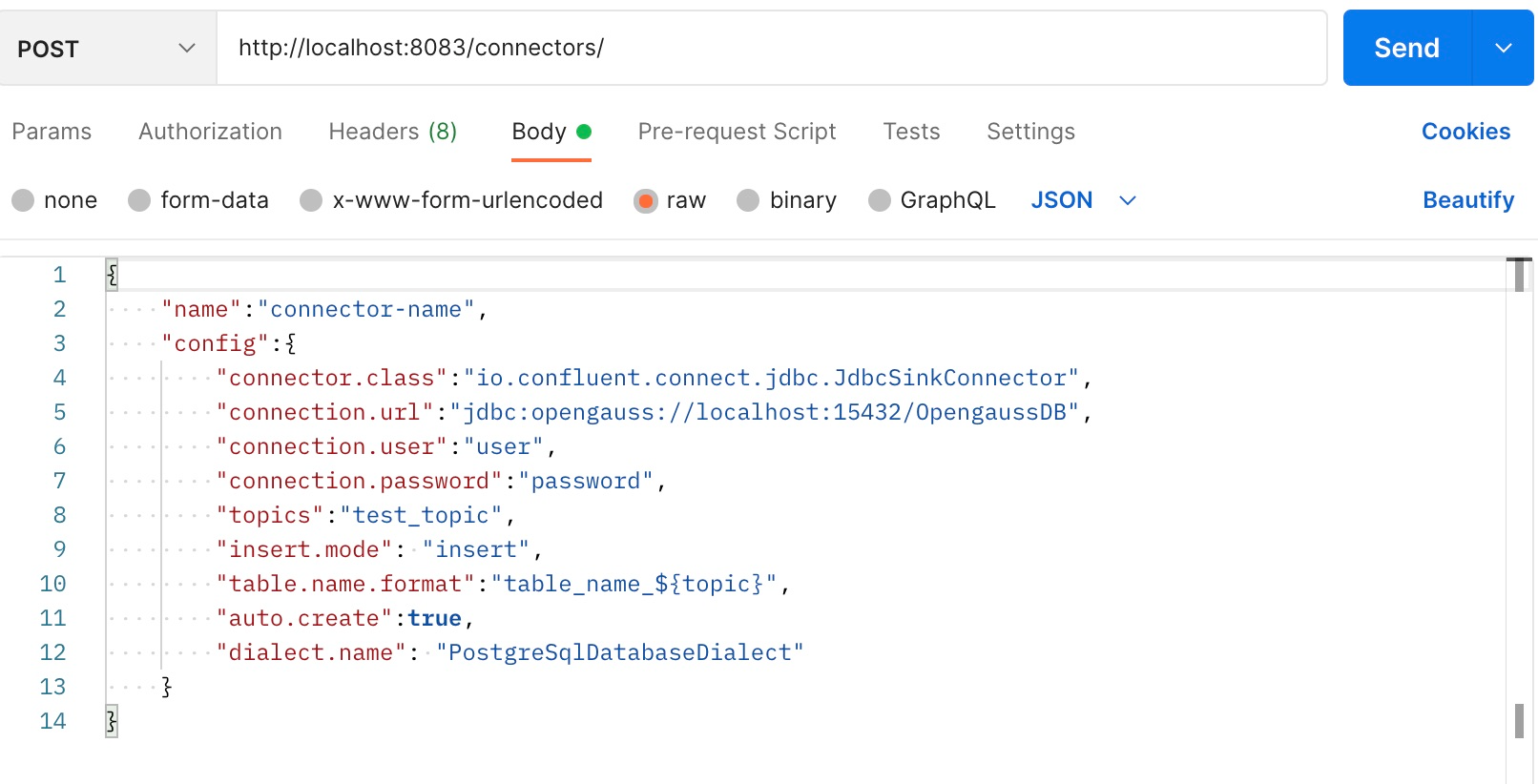
设置好参数后发送post请求。
显示类似如下的消息表示Connector启动成功。
解释{ "name": "connector-name", "config": { "connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector", "connection.url": "jdbc:opengauss://localhost:15432/sink", "connection.user": "user1", "connection.password": "Enmo@123", "topics": "test", "insert.mode": "insert", "table.name.format": "tableName_${topic}", "auto.create": "true", "dialect.name": "PostgreSqlDatabaseDialect", "name": "connector-name" }, "tasks": [], "type": "sink" }
-
数据写入示例
一个JDBC Connector,至少需要包含如下参数:
解释"connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector", "connection.url":"jdbc:opengauss://localhost:15432/OpengaussDB", "connection.user":"user", "connection.password":"password", "topics":"test", "table.name.format":"tableName"
假设要写入数据库的数据表结构以及配置如下:
解释CREATE TABLE "test" ( "id" INT NOT NULL, "longitude" REAL NULL, "latitude" REAL NULL, "temperature" REAL NULL, "humidity" REAL NULL, "time" TIME NULL, "string_time" TEXT NULL, "randomString" TEXT NULL );
解释curl -X POST http://localhost:8083/connectors -H "Content-Type:application/json" -d '{ "name":"connector-name", "config":{ "connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector", "connection.url":"jdbc:opengauss://localhost:15432/sink", "connection.user":"user1", "connection.password":"password", "topics":"topic", "table.name.format":"test" } }'
在source端发送数据,启动JDBC Connector。如果终端或cmd显示如下信息,表示Kafka启动成功。

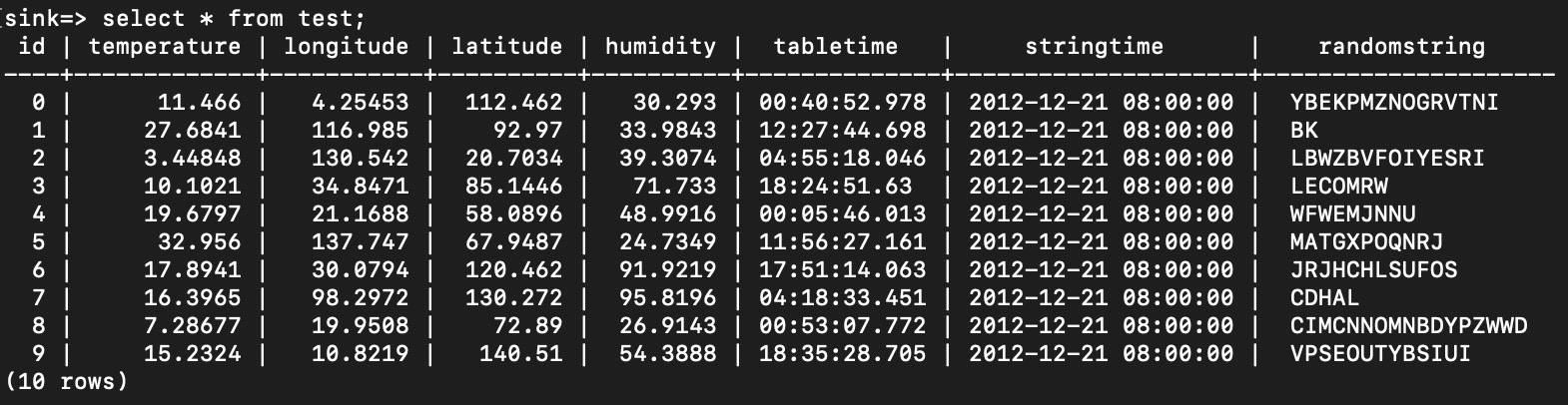
在数据库中查询,可以发现数据已保存到表中。