




背景
水印简单回顾
水印是Flink支持事件时间重要的组件,在与窗口使用中,是根据业务时间进行计算判断重要条件依据。
我们知道在网络中存在网络延迟,客户端发送数据,服务端接收的结果可能顺序不一致!如:客户端发送了1,2 服务端收到的可能是2,1。
服务端不能知道客户端什么时候发送完所有小于2的数据,所以需要有一套机制来判断客户端发送的进度。
这里就得提到水印(Watermark) ,服务端通过对业务时间判断增长阈值,来判断数据具体发送到哪一个时间段了,通过这个水印判断认为不再会有比它更小的数据进来。
多并行度的水印
常见在kafka中,一个topic有多个分区,flink一个并行度消费一个分区,那水位线是怎么推进的呢?flink中会取分区中最小的水印当做系统中的水印。
那么新的问题来了,如果kafka中数据倾斜或者某个分区就没有数据,那么某个分区水印就一直不更新,造成系统水印也就推进不了?这个怎么办呢?
flink其实也想到这个问题,提供了一个withIdleness
举个例子
以下代码版本都是flink1.11
实际withIdleness如何使用和注意事项可以看如下栗子🌰。
建立 topic
建立idleness_topic,设置为两个分区。
| topic | partition |
|---|---|
| idleness_topic | 0 |
| idleness_topic | 1 |
编写发送代码
public class IdlenessKafkaProducer {
public static void main(String[] args) {
Properties prop = new Properties();
prop.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "10.130.11.208:9092,10.130.10.243:9092,10.130.11.207:9092");
prop.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
prop.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
prop.setProperty(ProducerConfig.ACKS_CONFIG, "all");
prop.put(ProducerConfig.RETRIES_CONFIG, 0);
prop.put(ProducerConfig.BATCH_SIZE_CONFIG, 4096); //默认的批量处理消息字节数
prop.put(ProducerConfig.LINGER_MS_CONFIG, 1); //延迟等待发送时间
prop.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 1024 * 1024 * 50); //producer可以用来缓存数据的内存大小。
//发送客户端
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(prop);
//控制台输入
Scanner scanner = new Scanner(System.in);
System.out.println("请输入: 姓名,业务时间,分区");
while (scanner.hasNext()) {
String rs = scanner.nextLine();
if (StringUtils.isBlank(rs)) {
continue;
}
if (rs.equalsIgnoreCase("exit")) {
kafkaProducer.close();
return;
}
String[] split = rs.split(",");
Map<String, Object> map = new HashMap<>(2);
map.put("name", split[0]);
map.put("ts", Long.valueOf(split[1]));
Integer partition = Integer.valueOf(split[2]);
//实际发送数据
ProducerRecord record = new ProducerRecord("idleness_topic", partition, null, JSON.toJSONString(map));
Future send = kafkaProducer.send(record, (RecordMetadata data, Exception e) -> {
System.out.println("数据发送成功!" + data.topic() + ":" + data.partition() + ":" + data.offset());
});
System.out.println("请输入下一条:");
}
}
}
简单说下代码:就是在控制台按照格式手动输入 姓名,业务时间,主题分区 如:
控制台输入:王思聪,1000,0 代码会解析字符串 将王思聪,1000封装到Map 将Map对象的json串发送到idleness_topic主题0分区
Flink 处理实时数据
我们简单定义下业务处理数据的规则 :需求就是将收到的数据信息按照用户名分组,然后每隔5秒统计一次各个用户组的总条数!代码如下:
public class IdlenessJob {
public static void main(String[] args) throws Exception {
//自己封装的带环境区分的参数工具类
ParameterTool parameterTool = ParameterToolEnvironmentUtils.createParameterTool(args);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置为业务时间
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//设置kafka消费基本信息
String bootstrapServers = parameterTool.get(KafkaSinkUtil.KAFKA_BOOTSTRAP_SERVERS);
String groupId = "idleness-group";
Properties kafkaProp = new Properties();
kafkaProp.setProperty(KafkaConstant.BOOTSTRAP_SERVERS_KEY, bootstrapServers);
kafkaProp.setProperty(KafkaConstant.GROUP_ID_KEY, groupId);
FlinkKafkaConsumer<Buy> kafkaConsumer = new FlinkKafkaConsumer("idleness_topic", new KafkaDeserializationSchema<Buy>() {
@Override
public boolean isEndOfStream(Buy nextElement) {
return false;
}
@Override
public Buy deserialize(ConsumerRecord<byte[], byte[]> record) throws Exception {
//将接收到的数据对象 解析到 Buy 封装的对象中
String json = new String(record.value(), "UTF-8");
return JSONObject.parseObject(json, Buy.class);
}
@Override
public TypeInformation getProducedType() {
return TypeInformation.of(Buy.class);
}
}, kafkaProp);
kafkaConsumer.setStartFromLatest(); //每次启动从卡夫卡最新数据拉取
//抽取EventTime生成Watermark 可以处理迟到2秒数据
FlinkKafkaConsumerBase<Buy> source = kafkaConsumer.assignTimestampsAndWatermarks(WatermarkStrategy.<Buy>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner((e, t) -> e.ts));
DataStreamSource<Buy> dataStreamSource = env.addSource(source);
//通过name分组后 5秒滚动一个窗口
SingleOutputStreamOperator<Tuple4<String, Long, Long, Long>> process = dataStreamSource.keyBy(e -> e.name).window(TumblingEventTimeWindows.of(Time.of(5, TimeUnit.SECONDS)))
.process(new ProcessWindowFunction<Buy, Tuple4<String, Long, Long, Long>, String, TimeWindow>() {
@Override
public void process(String key, Context context, Iterable<Buy> elements, Collector<Tuple4<String, Long, Long, Long>> out) throws Exception {
long start = context.window().getStart(); //窗口开始时间
long end = context.window().getEnd(); //窗口结束时间
Long total = 0L; //总条数
String name = ""; //用户名
for (Iterator<Buy> iterator = elements.iterator(); iterator.hasNext(); ) {
Buy next = iterator.next();
name = next.name;
total += 1;
}
out.collect(Tuple4.of(name, total, start, end));
}
});
//控制台输出
process.print();
env.execute("Test IdlenessJob");
}
static class Buy implements Serializable {
private String name; //用户名
private Long ts; //业务时间
//get set 省略
}
}
数据准备
从代码可以知道窗口时间范围5秒。提示:1000ms(毫秒)等于1s(秒) 所以5秒开窗有以下窗口。
| 窗口 | 开始时间 | 结束时间 |
|---|---|---|
| 1 | 0 | 5000 |
| 2 | 5000 | 10000 |
| 3 | 10000 | 15000 |
| 4 | 15000 | 20000 |
| n | ... | ... |
假设发送数据如下:
| topic分区 | 0 | 1 |
|---|---|---|
| 思聪 | 500,1000,900,7000 | |
| 一宁 | 7000 |
情况一:窗口正常输出
往分区0发送数据
思聪,500,0 思聪,1000,0 思聪,900,0 思聪,7000,0
往分区1发送数据
一宁,7000,1
结果:7000-2000 > 5000 -1 会输出窗口计算结果!
因为有两秒迟到数据容错 所以水位线必须推进到 7秒才会触发窗口!这个时候会统计到这三条数据:
思聪,500,0 思聪,1000,0 思聪,900,0
这三条数据在 0-5000 窗口打印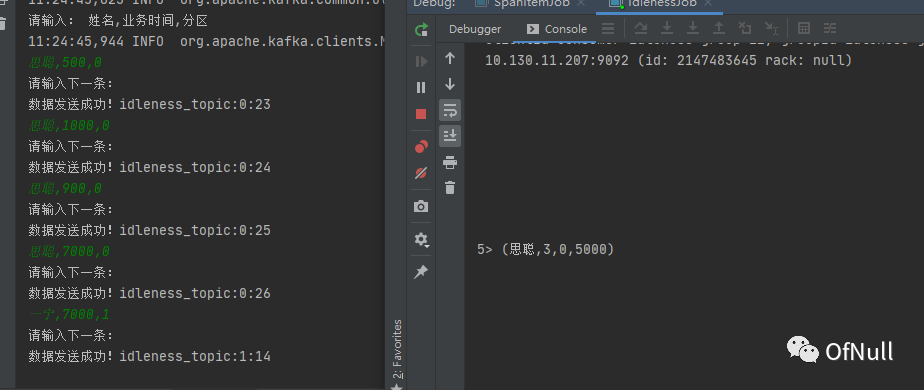
情况二:不触发窗口?
首先重启任务(程序)
开始往分区0发送数据
思聪,500,0 思聪,1000,0 思聪,900,0 思聪,7000,0
这里我不再分区1发送数据,结果如下:
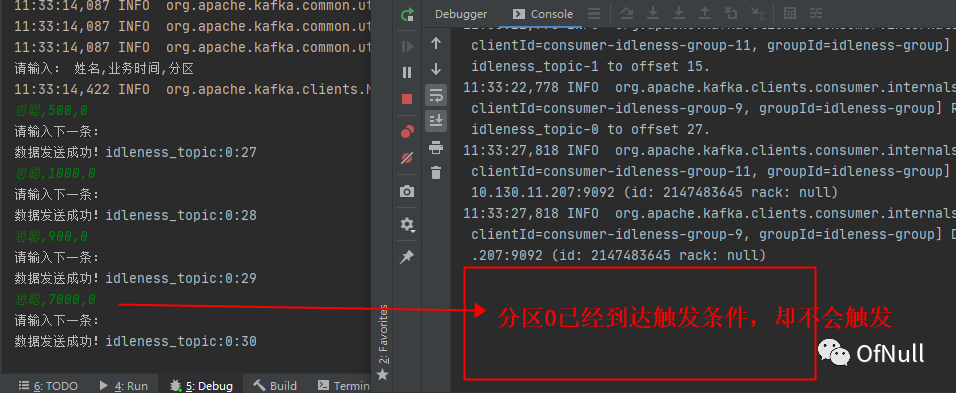
这就是多并行度情况下,分区水印推进只会取最小的水印,现在分区一没有数据,所以水印不能达到5秒 这里我们可以加一条分区数据但是时间还是小于5秒
一宁,4000,1
可以发现它也不会触发,因为分区1的水印现在推进到了4s也没到达7s ,如果之后一直没数据推进,那这个窗口就永远不会触发了。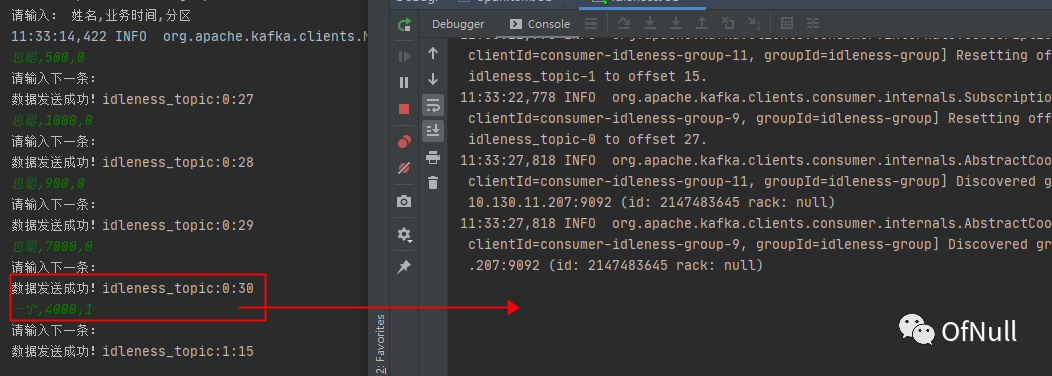
解决方案:withIdleness
首先修改下代码,添加空闲分区检测 .withIdleness(Duration.ofSeconds(60))
//抽取EventTime生成Watermark
FlinkKafkaConsumerBase<Buy> source = kafkaConsumer.assignTimestampsAndWatermarks(WatermarkStrategy.<Buy>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner((e, t) -> e.ts)
.withIdleness(Duration.ofSeconds(60))); //添加空闲分区检测 60s
往分区0发送数据
思聪,500,0 思聪,1000,0 思聪,900,0 思聪,7000,0
这里我也不再分区1发送数据,等待60秒后,可以看到窗口还是触发了。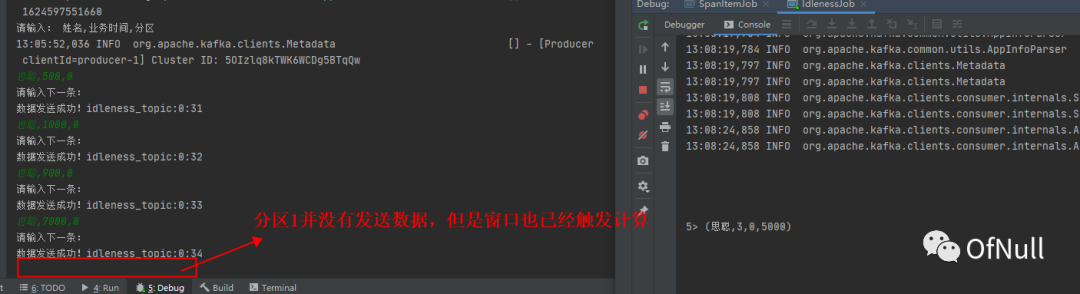
如果此时我再往分区1里面发送数据小于5秒 0-5000 窗口内的数据会有什么影响?其实没有影响 因为这条数据已经过期了。当然这里可以配置侧输出处理这条过期数据。
一宁,4000,1
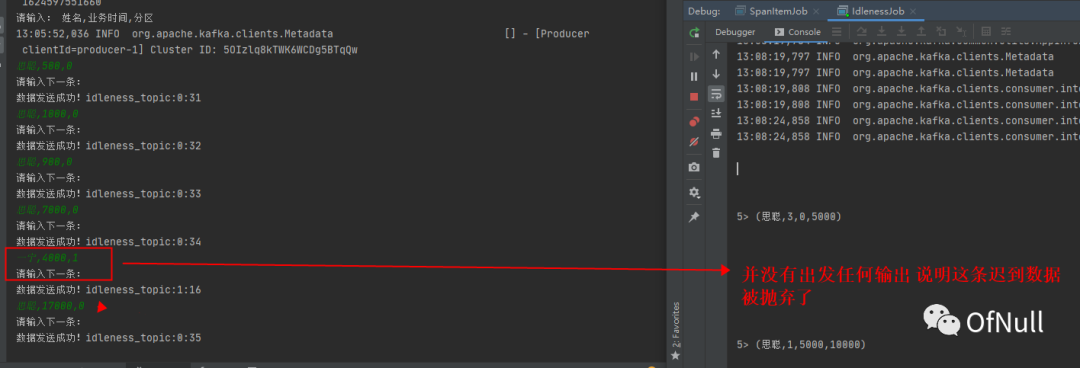
注意:比如所有分区,全部都不增长水印,那么配置了空闲检测也是无效的!
