




点击上方“IT那活儿”公众号--专注于企业全栈运维技术分享,不管IT什么活儿,干就完了!!!
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
Hive本质:
Hive特点:
6)YARN和Slider实现秒级查询搜索
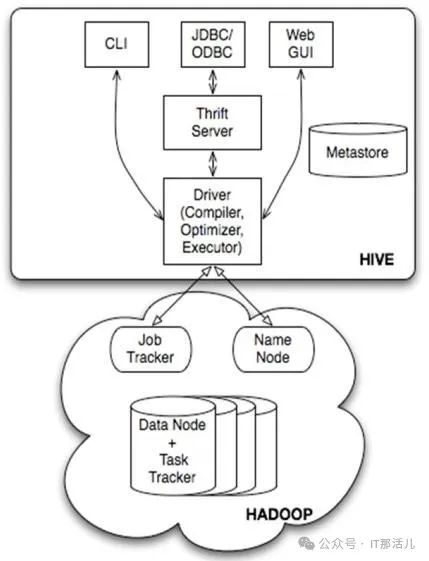
架构图:
内部表 外部表 分区表
外部表创建表的时候,不会移动数到数据仓库目录中(/user/hive/warehouse),只会记录表数据存放的路径; 内部表会把数据复制或剪切到表的目录下删除表; 外部表在删除表的时候只会删除表的元数据信息不会删除表数据; 内部表删除时会将元数据信息和表数据同时删除。
UDF 一进一出,处理原文件内容某些字段包含 [] “” UDAF 多进一出,sum() avg() max() min() UDTF 一进多出,ip -> 国家 省 市
使用 ORDER BY 子句排序 ASC(ascend): 升序(默认); DESC(descend): 降序。 ORDER BY 子句在SELECT语句的结尾
当distribute by和sorts by字段相同时,可以使用cluster by方式。cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。
MapJoin
小表在前大表在后,把小表全部读入内存中。
行列过滤
过滤空值(根据行列进行过滤)。
列式存储
hive的格式。
采用分区技术
建分区表。
合理设置Map数
过多的map数会造成数据倾斜。
合理设置Reduce数
过多的Reduce数会造成文件过多。
压缩
时间换空间,空间换时间。
总 结:
本文作者:王佳琛(上海新炬中北团队)
本文来源:“IT那活儿”公众号

文章转载自IT那活儿,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
