





上亿的表没索引,主键不是聚集主键,想要对这个表的一个列分组统计数据,怎么办?本期介绍达梦数据库中rowid的简单应用。
rowid是数据库中的伪列,伪列从语法上和表中的列很相似,查询时能够返回一个值,但实际上在表中并不存在。用户可以对伪列进行查询,但不能插入、更新和删除它们的值。
DM 中行标识符 ROWID 用来标识数据库基表中每一条记录的唯一键值,标识了数据记录的确切的存储位置。ROWID 由18位字符组成,分别为“4 位站点号+6位分区号+8位物理行号”。如果是单机则4位站点号为AAAA,即0。如果是非分区表,则6位分区号为AAAAAA,即0。
几种操作符。
假设TT1表的表定义如下:
CREATE TABLE TT1 (ID INT primary key,c1 varchar2(20));
SQL> explain select rowid,* from tt1 where rowid=?;1 #NSET2: [1, 1, 24]2 #PRJT2: [1, 1, 24]; exp_num(5), is_atom(FALSE)3 #CSEK2: [1, 1, 24]; scan_type(ASC), INDEX33555475(TT1), scan_range[exp_param(no:0),exp_param(no:0)]used time: 3.226(ms). Execute id is 0.SQL> explain select rowid,* from tt1 where id=?;1 #NSET2: [1, 1, 24]2 #PRJT2: [1, 1, 24]; exp_num(4), is_atom(FALSE)3 #BLKUP2: [1, 1, 24]; INDEX33555476(TT1)4 #SSEK2: [1, 1, 24]; scan_type(ASC), INDEX33555476(TT1), scan_range[exp_param(no:0),exp_param(no:0)]used time: 0.789(ms). Execute id is 0.
CSEK2:聚集索引范围扫描,通过键值精准定位范围。(存储了整行的数据即id,c1,rowid)
SSEK2:二级索引范围扫描,通过键值精准定位范围。(存储的是索引列和对应rowid,例子中是id,rowid)
LKUP2:根据二级索引的 ROWID 回原表中获取数据。
CSCN:基础全表扫描,从头到尾,全部扫描。
SSCN:二级索引扫描, 从头到尾,全部扫描。
从上面的介绍来看,CSEK不用再回原表获取数据,显然是比SSEK高效的。
说到rowid,与之类似的有rownum,rownum也是伪列,区别在于rownum是对sql的结果集的逻辑编号,rowid存储的是数据记录的存储位置,普通表是逻辑位置,而堆表是物理位置。
上亿的表,无索引,主键不是聚集主键。如何按某一列分组统计每组的数据量?模拟场景:tt1表数据量5000000,按c1列分组统计。
数据构造create table tt1 (id int primary key,c1 int,c2 int);insert into tt1 select level,dbms_random.value(1,1000),dbms_random.value(1,1000) from dual connect by level<=3000000;commit;insert into tt1 select level+3000000,dbms_random.value(1,10000),dbms_random.value(1,1000) from dual connect by level<=2000000;commit;
方案1
DECLAREv_sql varchar(2000);v_pageno bigint;v_operate_num bigint;v_size number;BEGINexecute immediate 'drop table if exists BK_TEST';execute immediate 'create table BK_TEST (C1 int, C1_COUNT NUMBER(10))';--创建备份表select max(rowid) into v_operate_num from TT1;v_pageno:= 100000; -- 100000条数据循环一次v_size:= ceil(v_operate_num/v_pageno);for i in 1..v_size loopv_sql:= 'insert into BK_TEST select c1,count(1) C1_COUNT from TT1 where rowid<='||i*v_pageno||'and rowid>='||(i-1)*v_pageno||'group by c1;';--利用rowid分批插入备份表execute immediate v_sql;commit;end loop;END;--最后分组统计select c1, sum(c1_count) C1_sum from BK_TEST group by C1;
DECLAREv_sql varchar(2000);v_pageno bigint;v_operate_num bigint;v_size number;BEGINexecute immediate 'drop table if exists BK_TEST';execute immediate 'create table BK_TEST (C1 int, C1_COUNT NUMBER(10))';--创建备份表select max(rowid) into v_operate_num from TT1;v_pageno:= 100000; -- 100000条数据循环一次v_size:= ceil(v_operate_num/v_pageno);for i in 1..v_size loopv_sql:= 'insert into BK_TEST select c1,count(1) C1_COUNT from TT1 where id in (SELECT ID FROM (SELECT INNER_TABLE.*, ROWNUM OUTER_TABLE_ROWNUMFROM (select ID from tt1 order by id desc) INNER_TABLEWHERE ROWNUM <='||i*v_pageno||')OUTER_TABLEWHERE OUTER_TABLE_ROWNUM >'||(i-1)*v_pageno||')group by c1;';execute immediate v_sql;commit;end loop;END;--最后分组统计select c1, sum(c1_count) C1_sum from BK_TEST group by C1;
方案1:执行耗时725毫秒. 执行号:64478
方案2:执行耗时37秒 51毫秒
显然方案1的性能比方案2的性能好。
方案1中主要是利用rowid去批量插入备份表来分组统计,方案2中主要是利用id去批量插入备份表来分组统计。下面看看insert into语句的计划。
方案1 insert into语句计划
insert into BK_TEST select c1,count(1) C1_COUNT from TT1 where rowid<=? and rowid>=? group by c1;1 #INSERT : [0, 0, 0]; table(BK_TEST), type(select), hp_opt(0), mpp_opt(0)2 #PRJT2: [36, 1875, 16]; exp_num(2), is_atom(FALSE)3 #HAGR2: [36, 1875, 16]; grp_num(1), sfun_num(1), distinct_flag[0]; slave_empty(0) keys(TT1.C1)4 #CSEK2: [24, 187500, 16]; scan_type(ASC), INDEX33555475(TT1), scan_range[exp_param(no:1),exp_param(no:0)]
方案2 insert into语句计划
insert into BK_TEST select c1,count(1) C1_COUNT from TT1 where id in (SELECT ID FROM (SELECT INNER_TABLE.*, ROWNUM OUTER_TABLE_ROWNUMFROM (select ID from tt1 order by id desc) INNER_TABLEWHERE ROWNUM <=?)OUTER_TABLEWHERE OUTER_TABLE_ROWNUM >?)group by c1;1 #INSERT : [0, 0, 0]; table(BK_TEST), type(select), hp_opt(0), mpp_opt(0)2 #PRJT2: [2, 1, 12]; exp_num(2), is_atom(FALSE)3 #HAGR2: [2, 1, 12]; grp_num(1), sfun_num(1), distinct_flag[0]; slave_empty(0) keys(TT1.C1)4 #NEST LOOP INDEX JOIN2: [1, 1, 12]5 #DISTINCT: [1, 1, 4]6 #PRJT2: [1, 1, 4]; exp_num(1), is_atom(FALSE)7 #SLCT2: [1, 1, 4]; OUTER_TABLE.OUTER_TABLE_ROWNUM > exp_param(no:1)8 #PRJT2: [1, 3, 4]; exp_num(2), is_atom(FALSE)9 #RN: [1, 3, 4]10 #PRJT2: [1, 3, 4]; exp_num(1), is_atom(FALSE)11 #TOPN2: [1, 3, 4]; top_num(exp11)12 #SSEK2: [1, 300, 4]; scan_type(DESC), INDEX33555476(TT1), scan_range(min,max)13 #BLKUP2: [1, 1, 4]; INDEX33555476(TT1)14 #SSEK2: [1, 1, 4]; scan_type(ASC), INDEX33555476(TT1), scan_range[DMTEMPVIEW_889214639.colname,DMTEMPVIEW_889214639.colname]
方案2中扫描表两次,然后id不是聚集主键,它还要回原表去获取数据,所以方案2耗时比方案1高。
注意事项:
每个表有且只有一个聚集索引,如果id是聚集主键,rowid就不是聚集索引。
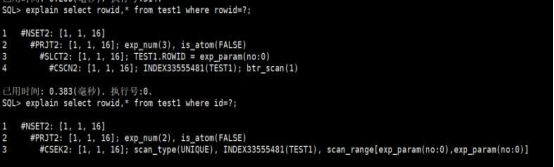
案例主要是利用聚集索引的性能比二级索引好,以及rowid的递增性。如果当主键是聚集主键时,同理,利用CSEK性能比SSEK性能好的这一点去做数据统计。
以上为本期分享,希望能带给大家帮助。想要了解更多往期干货,可访问页面最下方#达梦技术干货攻略#合集或下方相关分享。在此邀请更多学员参与“达梦技术干货投稿活动”,稿件获选后将在达梦“干货分享”专栏进行发布,欢迎来稿!
相关分享:

