




(一)背景
开源数据库 MyTopling 是基于开源存储引擎 ToplingDB 的 MySQL,MyTopling 分叉自 MyRocks,兼容 MyRocks,ToplingDB 分叉自 RocksDB,兼容 RocksDB。MyTopling 和 ToplingDB 相比上游都实现了巨大的性能提升与成本降低。
在阿里云的大力支持下,MyTopling 成功上线计算巢:私有化部署版,高级版,基础版,集成版(集成 LNMP/Wordpress),特价版 2核2G ¥99包年。
(二)Parallel Scan
innodb 有个选项 innodb_parallel_read_threads,其最典型的用途是在select count(*) from SomeTable中启用多线程扫描。
我们认为该特性对 MyTopling 引擎也非常有用,但是上游 MyRocks 没有这个功能,并且这个功能还需要下层 ToplingDB 的支持,同样 ToplingDB 的上游 RocksDB 也没有这个支持。
因为这种 Feature 需要很多脏活累活,我们本想着偷懒等上游来实现,前两天实在忍不了,就自己来下手。
(三)引子:并行排序
传统排序算法中,快速排序与归并排序可以优雅地实现多线程排序,其中快排的线程数在递归中先少后多,归并排序线程数的在递归中先多后少。但这都有一个问题,就是无法线性 Scale,瓶颈在于其中的串行部分,例如对于快排:
void pqsort(Type* a, int n) {
if (n <=1) return;
int pivot = cut(a, n);
thread t(&pqsort, a, pivot); // 先不管数组太小时是否值得启动 thread
pqsort(a + pivot + 1, n - pivot - 1);
t.join();
}
cut(a, n)是串行的,并且最开始工作在整个数组上,所以无法按线程数 scale。
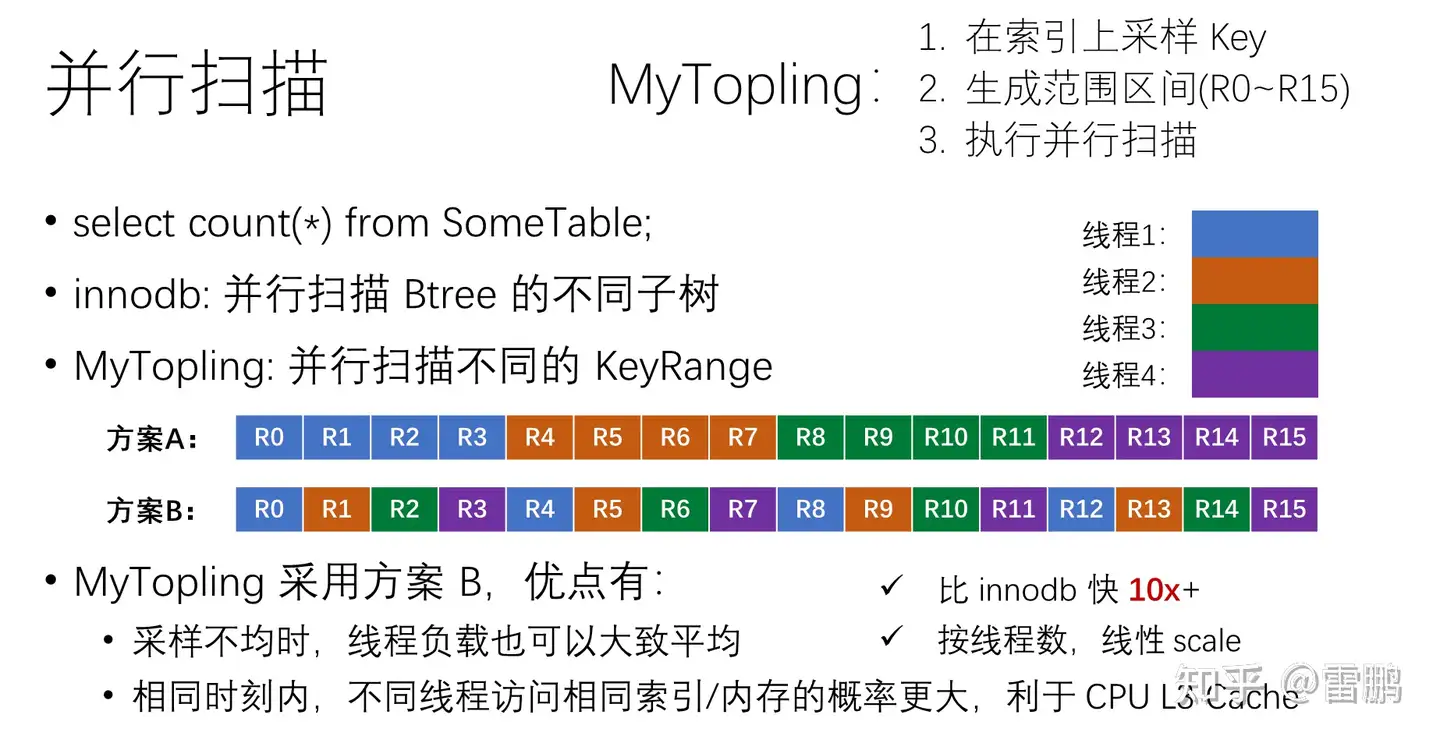
我们换个思路,考虑 MapReduce 方案,其中有个关键是 Partition,Partition 一般是 hash Partition,而 hash 跟排序完全不搭边。我们自然而然想到另一种 Partition 思路:Range Partition,这就需要相应的 Range 边界,而我们并不知道这些边界。
一般情况下,我们不知道该怎么办的时候,总能找到某种随机大法,在这里就是 Random Sampling:在输入数据中随机采样,比如从100亿条数据中采样出 100 条,然后对这 100 条排序,得到 101 个Range 区间。
然后,Map 阶段,将输入分成 M 等份,每个 Mapper 按 Range 切分成 R(前例101) 份,在 Reduce 阶段,每个 Reduce 对属于自己的那一份数据(M个分段)进行排序。因为是按 Range 进行的分区,不同的 Range 没有重叠,所以 Reduce 的输出,实际上就是全排序的结果。这个方案中,开始的 Sampling 阶段是串行的,但其耗时几乎可以忽略,所以整体上可以线性 Scale,充分利用所有计算资源。
(四)历史脉络:如何更好地切分 Sub Compaction
2017 年的时候,我们曾经给 RocksDB 提交了一个 Feature Request: Optimization for subcompact: Add Get Random Keys · Issue #1842,但是一直没有得到积极回应。
2021 年我们开始 ToplingDB 项目时,上游 RocksDB 仍未实现该 Feature,所以我们就自己实现了(GetRandomInteranlKeys)。
2022 年,上游 RocksDB 实现了这个 Feature(ApproximateKeyAnchors),为了持续跟进上游代码,减小合并代码的心智成本,我们采用了 RocksDB 的方案。
这里面的关键点就是 Random Sampling,当然实际的 Sampling 未必是真的 Random,只要“差不多就行了”。
有了 Random Sampling,在 Compact 中,对输入的所有 SST 采样,然后把采样结果排序并切分成 n 份——“大致 n 等份”。而在这之前,对每个 SST 只有 begin end 两个采样点,无法保证“大致 n 等份”。
(五)复用 ApproximateKeyAnchors
Random Sampling 是一个通用的 Feature,切分 Sub Compaction 只是它的一个应用。它还可以用在很多地方,比如我们向上游提交的 Pull Request:
- Feature Request: Create Index in Parallel #1245 · facebook/mysql-5.6
- Feature Request: Add DB::ApproximateKeyAnchors · Issue #10888 · facebook/rocksdb
可以看到,ApproximateKeyAnchors 这个功能,上游 RocksDB 是在 SST(TableReader) 中定义的,仅使用在 Sub Compact 切分中,我们希望把它暴露到用户接口中(DB::ApproximateKeyAnchors)。这样一来,任何需要它的地方都可以使用。
(六)MyTopling 的并行扫描
上游 rocksdb 和 myrocks 迟迟不实现相应功能,我们就只能自己撸起袖子干了。先实现DB::ApproximateKeyAnchors:
virtual Status ApproximateKeyAnchors(ColumnFamilyHandle*, const Range*, std::vector<Anchor>*) = 0;相比 TableReader::ApproximateKeyAnchors,这里多了一个 Range 参数,因为我们并不需要整个 DB 的 Random Sample,只需要我们感兴趣的部分。
在 MyTopling 中,我们增加一个选项:rocksdb_parallel_read_threads
为了兼容性,我们不更改 myrocks 的命名规则,仍使用 rocksdb_ 前缀
剩下的事情是按部就班的,拿到相应的样本,进行一些预处理(删除非法样本,排序,消重……)。最终样本(n个)构成的区间数目(n-1)一般远大于线程数(T),所以并发任务的分配有两种方案:
- 预先分配:把 n-1 个小区间按数目等分成 T 个大区间,每个大区间(n-1)/T个小区间,每个线程执行一个大区间
- 即时分配:把把 n-1 个小区间看成包含 n-1 个元素的队列,多个线程循环地从队列里面取任务执行,效果是交替执行
我们采用即时分配的交替执行方案,主要考虑到两个原因:
- ApproximateKeyAnchors 不是真的随机,在某些情况下可能会有数据偏斜
- 更好地利用 CPU L3 Cache(L3 是多核共享的)
交替执行有助于缓解上面两个问题:
- 例如某些连续小区间的实际数据量更大,预先按小区间数目等量切分就会出现 Skew
- 对于 L3 Cache,多个线程有较大概率会扫描相同 SST 的不同 Range,这些 Range 在 Index 中可能会有共享的内存区间,于是 L3 Cache 就可以得到共享。
(七)效果
我们使用长时间运行的 TPCC 数据进行测试,其数据规模如下:
select TABLE_NAME, ENGINE, TABLE_ROWS, DATA_LENGTH from tables
where table_schema = 'tpcc_rocksdb' ;
+-------------------------+---------+------------+--------------+
| TABLE_NAME | ENGINE | TABLE_ROWS | DATA_LENGTH |
+-------------------------+---------+------------+--------------+
| bmsql_config | ROCKSDB | 4 | 7035 |
| bmsql_customer | ROCKSDB | 94867478 | 49107884087 |
| bmsql_district | ROCKSDB | 20068 | 1933257 |
| bmsql_history | ROCKSDB | 471235271 | 16680338003 |
| bmsql_history_innodb | InnoDB | 435539240 | 36326866944 |
| bmsql_item | ROCKSDB | 100000 | 6767496 |
| bmsql_new_order | ROCKSDB | 62502329 | 108264824 |
| bmsql_oorder | ROCKSDB | 523372021 | 14391031941 |
| bmsql_order_line | ROCKSDB | 5418105614 | 243993989997 |
| bmsql_order_line_innodb | InnoDB | 1856301006 | 168447442944 |
| bmsql_stock | ROCKSDB | 379704874 | 122897109192 |
| bmsql_warehouse | ROCKSDB | 4000 | 344405 |
+-------------------------+---------+------------+--------------+其中 bmsql_history_innodb 是我们从 bmsql_history 拷贝得来的。
我们也尝试拷贝 bmsql_order_line 到 innodb,运行了一个晚上结果失败(进程挂了),重启后恢复数据,结果是只完成了一部分。所以就不测 bmsql_order_line_innodb 了。
我们执行一下 count:
mysql> set rocksdb_parallel_read_threads = 32;
mysql> select count(*) from bmsql_history;
+-----------+
| count(*) |
+-----------+
| 471235271 |
+-----------+
1 row in set (0.73 sec)
mysql> set innodb_parallel_read_threads = 32;
mysql> select count(*) from bmsql_history_innodb;
+-----------+
| count(*) |
+-----------+
| 471235271 |
+-----------+
1 row in set (10.07 sec)32 线程时,ToplingDB 性能是 innodb 的 13 倍多!我们减少线程数:
mysql> set rocksdb_parallel_read_threads = 16;
mysql> select count(*) from bmsql_history;
+-----------+
| count(*) |
+-----------+
| 471235271 |
+-----------+
1 row in set (1.40 sec)
mysql> set innodb_parallel_read_threads = 16;
mysql> select count(*) from bmsql_history_innodb;
+-----------+
| count(*) |
+-----------+
| 471235271 |
+-----------+
1 row in set (7.76 sec)16 线程时,ToplingDB 耗时多了 1 倍,而 innodb 反而更快了。再减少线程数到 8:
mysql> set rocksdb_parallel_read_threads = 8;
mysql> select count(*) from bmsql_history;
+-----------+
| count(*) |
+-----------+
| 471235271 |
+-----------+
1 row in set (2.67 sec)
mysql> set innodb_parallel_read_threads = 8;
mysql> select count(*) from bmsql_history_innodb;
+-----------+
| count(*) |
+-----------+
| 471235271 |
+-----------+
1 row in set (11.20 sec)ToplingDB 耗时又多了接近 1 倍,innodb 耗时只多了 44%。
可以看到,ToplingDB 的单线程性能远高于 innodb,并且随线程数线性 scale,innodb 的 scale 能力则差很多。简单计算可知,ToplingDB 每线程每秒钟可扫描 2200万条,这还是在 Xeon 2682v4 这种老古董的服务器上,较新的服务器会快 ~50%!
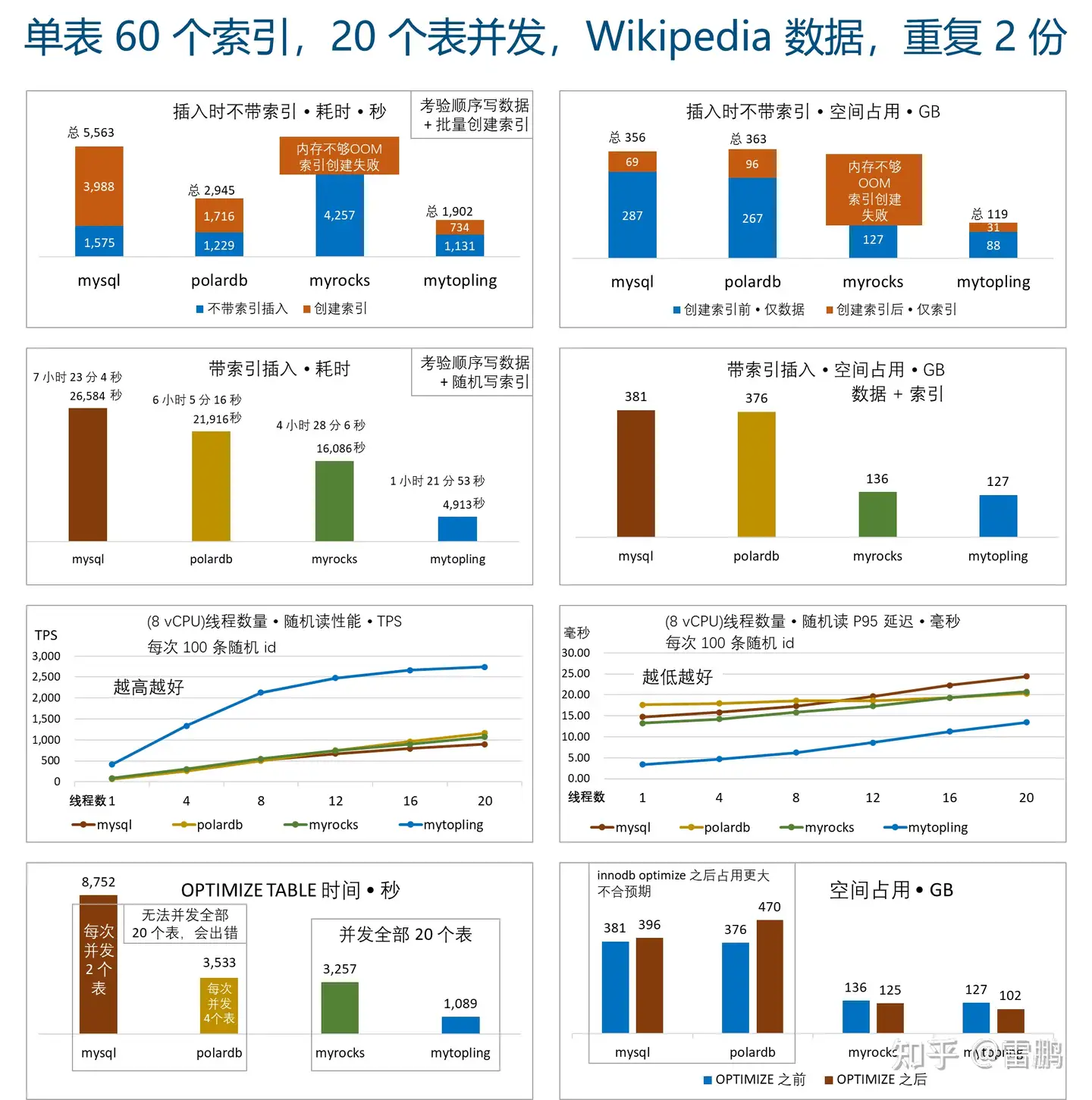
一般而言,因为读放大,LSM 的读性能不可能追得上 Btree,但是 ToplingDB 凭借各种优化,不仅超越了同宗的 RocksDB,还超过了使用 Btree 的 innodb。不仅仅这个功能实现了巨大超越,还有很多其它功能也是大幅超越:
(八)限制
目前我们仅支持 select count(*) 全表/全索引扫描的并行化。
