




没错,不是2%不是千分之2,就是20%,RoCE远程读需要
800ns
左右,NetDAM只需要618ns
而抖动更是小了2个数量级,直接到了39ns
.可别小看这抖动数据,尾部延迟小了数倍这样会消除抖动获得确定性延迟会让实际应用性能提升数倍.
而前天的论文只是总体架构,接下来几天,我们会从最基本的读写通信到分布式计算优化,容器网络边斗优化,Serverless, 边缘计算、加解密和安全等多个方向给您娓娓道来NetDAM的用例
今天要讲的是第一节,最基本的如何通过使用NetDAM隔离I/O内存和计算主存来优化CPU的性能,并解决RoCE的一系列问题。
RoCE的问题
在数据中心内,RoCE的出现是有其历史背景的,主要原因是为了替代TCP实现低延迟高带宽的可靠传输并降低CPU的overhead, 也就是Kernel Bypass的一些工作(结果现在RDMA over TCP真是讽刺啊)。
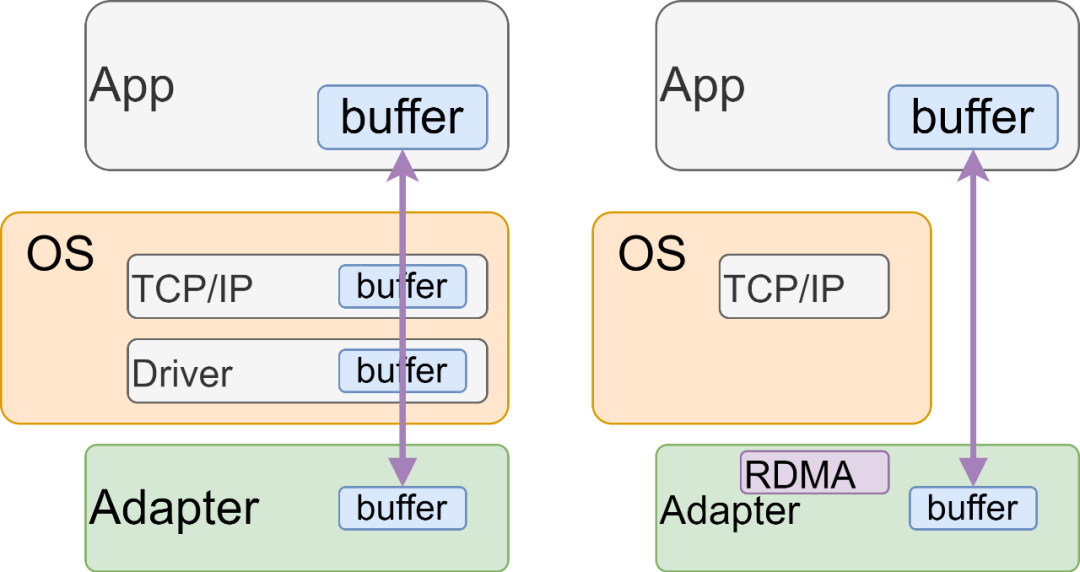
当然Kernel Bypass的工具也不止RDMA,还有后来的DPDK,以及衍生出来用在存储网络中的SPDK...
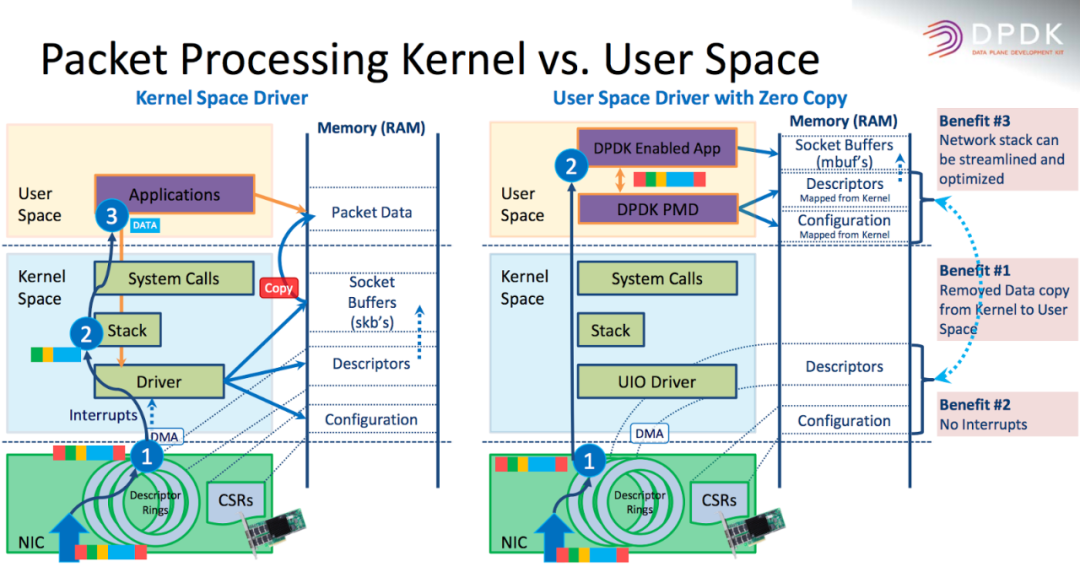
两者在设计思路上的跟不同点在哪?RDMA实际上是将传输层协议栈下沉到硬件,然后采用DMA Push
的方式,而DPDK则是将协议栈上移,在用户态处理,而PMD(Poll Mode Driver)这个词也说明了采用Poll
的方式。
一推一拉,各有异同。DPDK虽然消耗了额外的CPU资源,但是很多内容是按需读取的,CPU自己好控制。而RDMA的问题呢?数据是直接DMA push到内存的,而问题就出在DMA上, 看似好像DMA不用CPU核心的资源,但是DMA实现的时候,毕竟会对主内存带来干扰,特别是当网卡速率越来越高时。过去已经有很多论文pcie_bench[1] rdma_bench[2] 谈论到这个话题,结论就是RDMA的性能受到很多因素影响,DMA、PCIe、IOMMU都是需要考虑的东西,特别是PCIe本身的传输贡献了很大一部分延迟。
那么下一步的关键就是如何绕开PCIe DMA对整个系统的影响了?当然过去很多厂家也做了一些Direct Cache Access的尝试,例如Intel DDIO、CAT等技术,但是也会存在一些问题,具体分析可以看Reexaming DCA[3]
其实从本质上来看,就是RDMA网卡产生的DMA请求来自于外部主机具有高度的不可预测性,然后RootComplex又在CPU里没法可编程去控制和调度,外设DMA对于内存读写的争抢和CPU多核一起争抢,还有LastLevelCache的影响....让网卡根据CPU每个核的空闲程度去调度会搞得更复杂...
所以一个非常朴素的想法就产生了,能不能把I/O相关的内存和计算相关的内存隔离开来?或者在DMA的路径上绕开PCIe?
NetDAM:网存的出现
既然有了IOMMU的存在,但是体系结构里看不到IO Memory 呀~ 所以NetDAM最一开始的想法就是把内存放置在更靠近网络侧构建网存
,一方面可以在很多任务中绕开PCIe的影响,另一方面还可以将外部网络访问的DMA请求和内部CPU的访问隔离开:
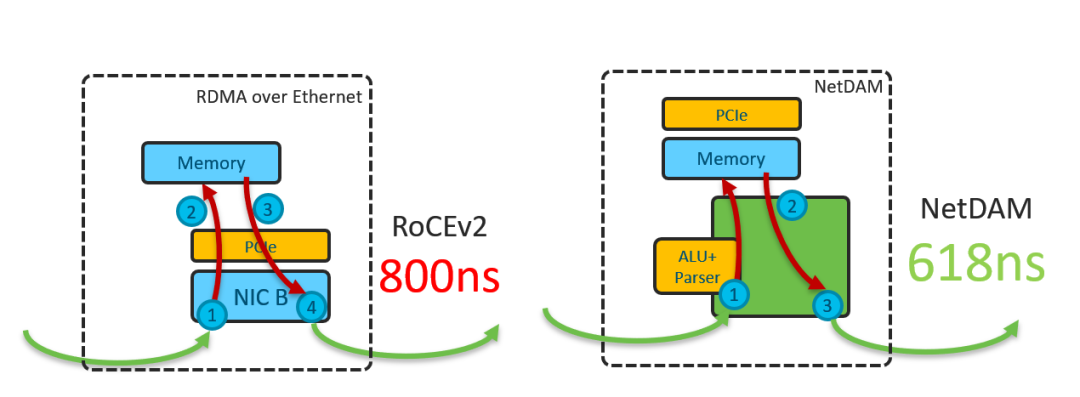
隔离开来最大的好处是,响应的抖动
被消除了,传统的RoCE做分布式存储的估计都非常头疼这个问题,而NetDAM由于响应直接绕开了PCIe DMA的操作,这样延迟具有完全的确定性。当NetDAM挂载的是PMEM的时候,或者直接在FPGA上实现SSD/NVMe控制器后,这样不就完全可确定性的存储了么?各个公有云开不开心?而且NetDAM只需要存储侧支持,虚机侧还是跟原来一样
但是很多人有疑惑,网卡不是有buffer么?网存和Buffer的最大区别就是:可编程性,buffer可能读完一次就没了,并且Buffer可能只能以包为单位调度,而网存可以单独的去access 某些Bytes,一个报文可以多次access,当然除了这些因素,另一个因素促成这件事的便是CCIX、CXL这样的新型总线:
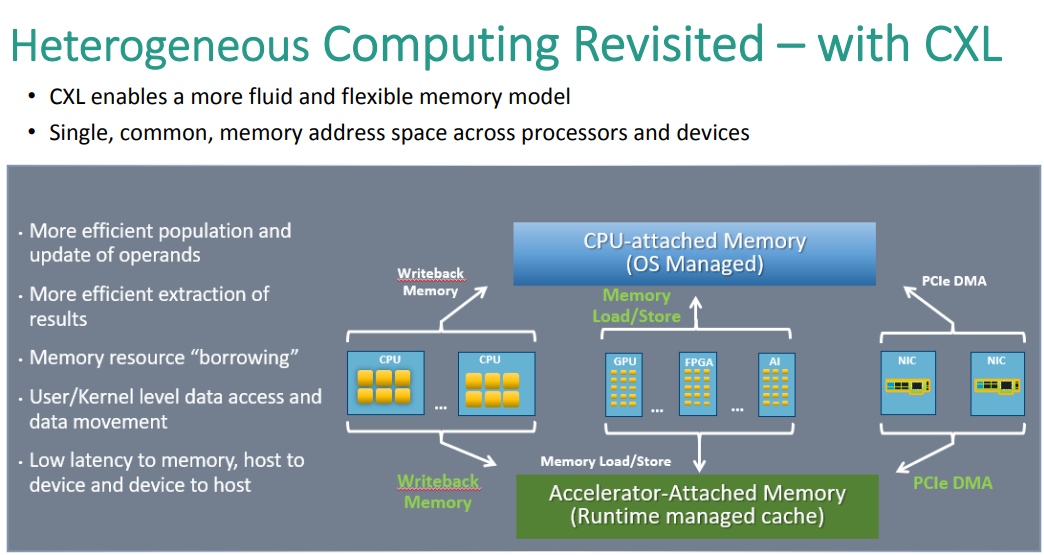
当然上图中设计CXL的人还没想到网卡直接也可以作为一个Accelerator Attach内存,而我们就实现了,这样就像一张加速卡一样,可以让CPU或者其他卡直接Load/Stoe。 应用通过CXL总线去micro batch poll read网卡的内存,看上去延迟大了一点,但是在CPU域上这样的读写更具可控性,可以根据计算任务做适当的Prefetch来隐藏延迟,如下图所示,这就是整个NetDAM的最大不同和比RoCE快的根本原因,它使得CPU的操作完全可控,而RDMA具有大量的不可控因素。而这样的方式对于NUMA也非常有用,传统的NUMA架构下,网卡必须要DMA到某个CPU的PCIe RootComplex,虽然买螺丝可以将一个网卡同时插两个PCIe插槽来解决,终归会很复杂,而NetDAM则是一个标准的I/O内存池,两个CPU都可以来取甚至两个CPU直接的一些流量都可以通过给NetDAM添加Memcopy指令集来实现。
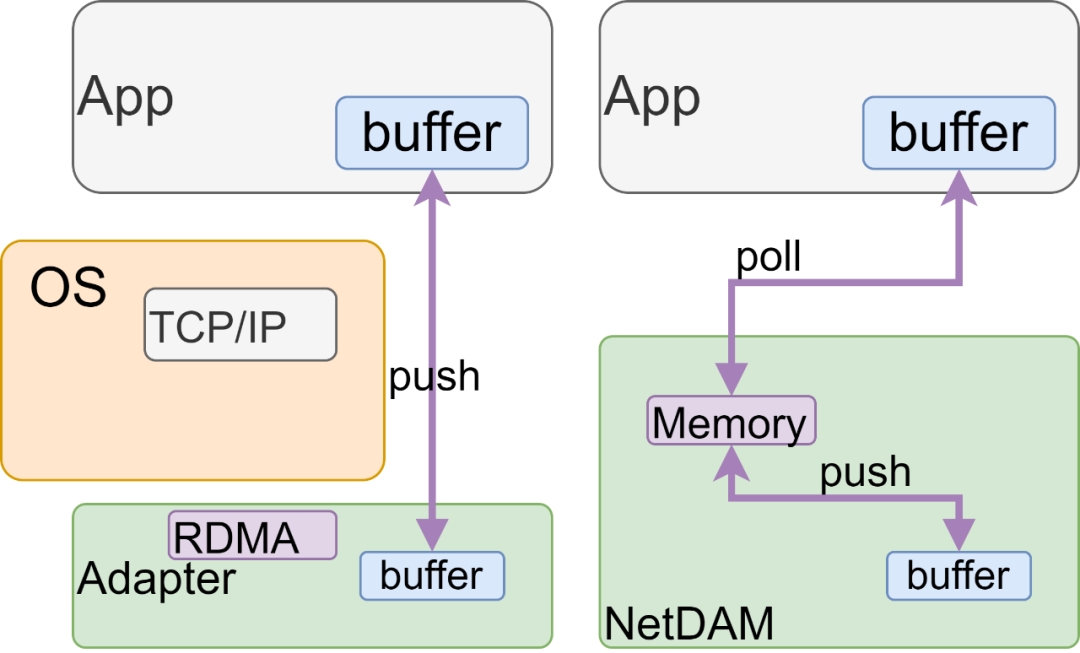
与此同时,思科还对开源社区共享了Memory Interface(memif)的技术,具体内容可以去看看B站上的视频:
https://www.bilibili.com/video/BV1qk4y1R7We/
原生的Memif为了安全性有一次内存拷贝,而我们原始的报文在NetDAM网存里,可以根据应用的需求,按需的拷贝到主存中。
通过这样的技术,我们可以很容易的给虚拟化平台,和容器实现快速的原生的用户态访问,当然思科的memif技术通过DPDK或者VPP的方式提供,也会消耗一些CPU,而NetDAM可以把这些内容硬化在了网卡的内存上, 所以NetDAM作为智能网卡时会存在如下形态:
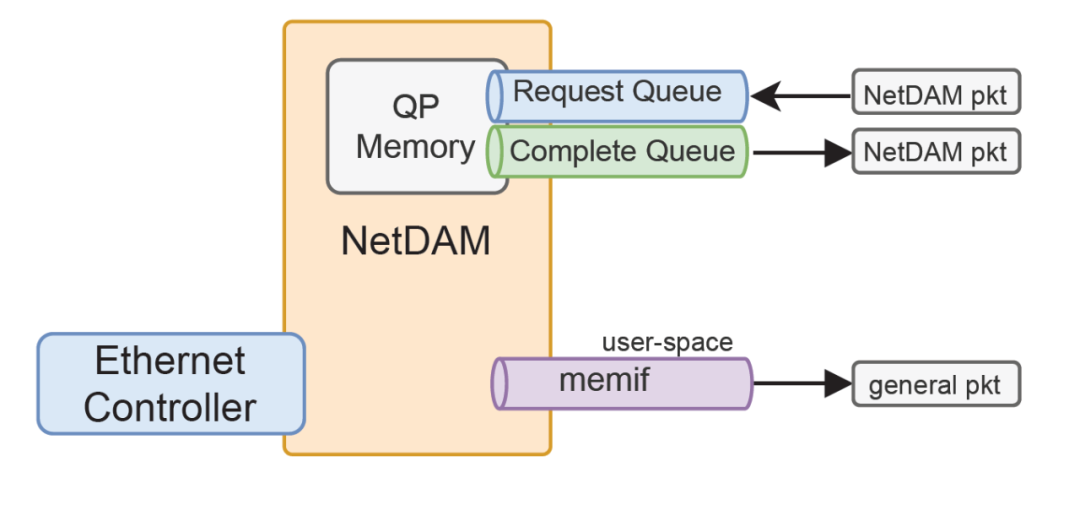
基于golang原生的报文读取速度达到了29Mpps, 后端另一个常用的Node.js也有memif的版本,至于NetDAM 容器网络加速、SSL加速和加解密Offload的技术,HPC加速和PGAs实现、Incast优化、分布式AI-MPI优化,分布式数据库优化的内容,后面几天慢慢给大家讲。
Reference
Understanding PCIe performance for end host networking : https://dl.acm.org/doi/10.1145/3230543.3230560
[2]Design Guidelines for High Performance RDMA Systems: https://www.usenix.org/conference/atc16/technical-sessions/presentation/kalia
[3]Reexamining Direct Cache Access to Optimize I/O Intensive Applications for Multi-hundred-gigabit Networks: https://www.usenix.org/conference/atc20/presentation/farshin
