





本次分享将探讨在大模型时代基于湖仓一体的数据产品演进,以及我们观察到的一些智能开发相关的新范式。
分享内容将围绕以下四点展开:
大模型时代来临
大模型的发展历程
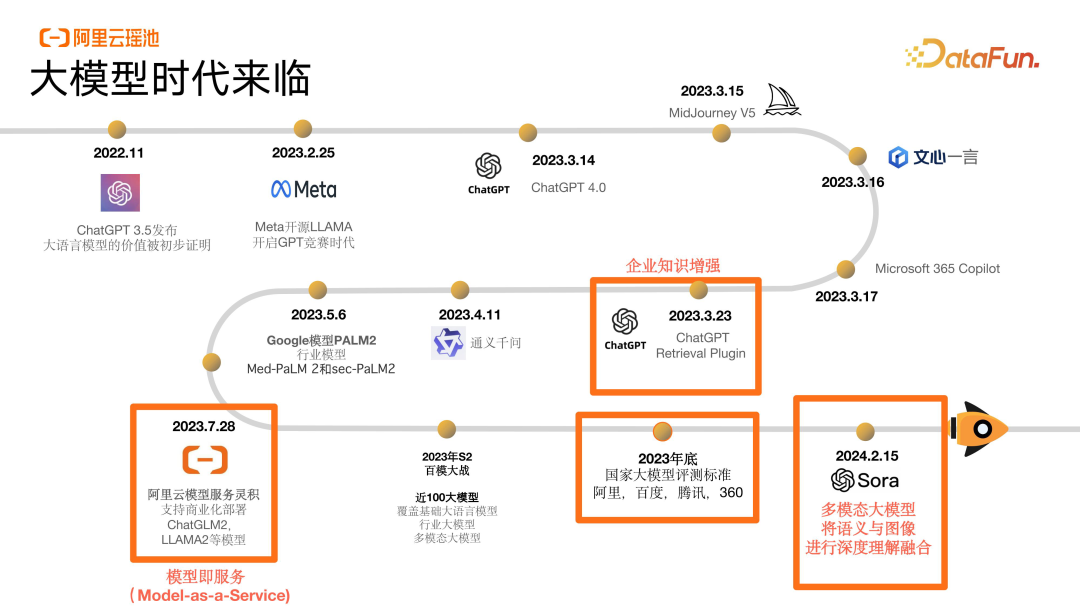
深化产业影响,驱动全行业能力升级

通过《2023年中国AIGC产业全景报告》我们可以看到大模型对于产业的影响非常广泛且程度不同,基于企业的数字化程度和技术拥抱程度,呈现出多档变化的节奏。具体如下:
对于那些价值链线上化程度越高,内容在价值链中占比越高的企业,它们对 AI 的拥抱度往往更高,同时能够将大模型更快地应用到内容生产上,现在可以看到的情况是在生产效率上能带来 50% 到 70% 的提升。同时,对于海量数据的开发效率提升背后,支撑着的扫描的数据面积也会变得更大,生产的数据也会变得更多,随着大规模的大模型的使用,会带来整个数据处理面向应用内容生产上数据量的大幅增长。
垂直领域的发展更多在于我们如何能够让大模型的数据质量更高,提供更为准确、更为可用的产品能力。以教育行业、影视行业为主的一些领域,对大模型的准确性和垂直领域的定向优化以及数据层面的质量提升有着强烈的诉求。
AIGC分层能力一览
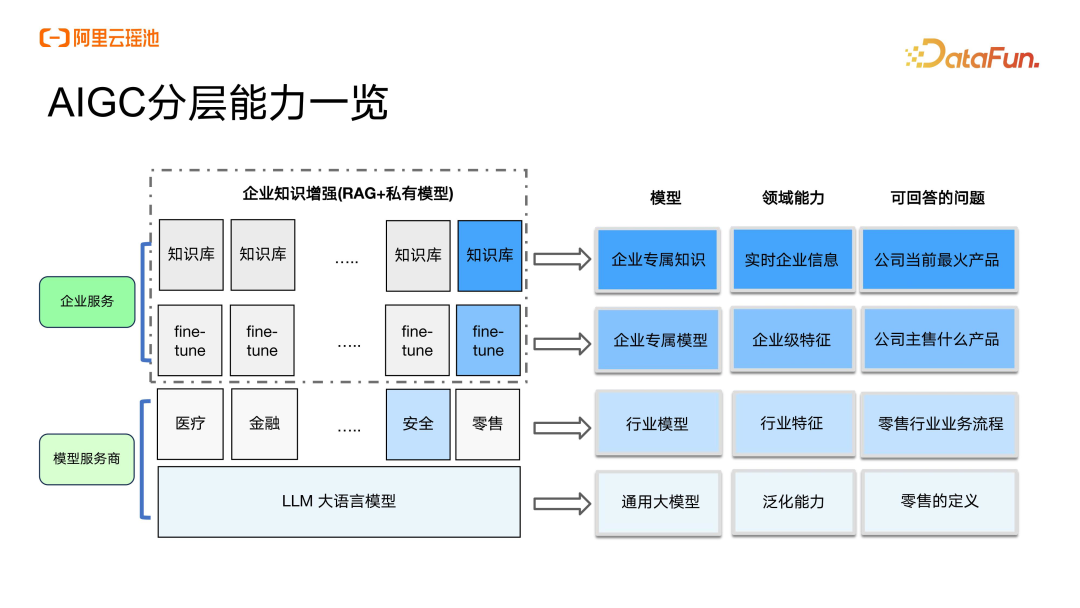
企业数据平台变革带来的挑战

从 AIGC 行业趋势和数据平台能力的演进方向上看。目前企业数据平台能力面临的挑战主要集中在三个层面:
第一个是 AIGC 应用层。目前 AIGC 应用具有自顶向下的发展趋势,应用层对于 AI 的集成度是最为广泛的,面向大模型的应用构建实际上是基于很多非结构化和半结构化的数据加上大模型的能力来去支持具体的业务场景。这对于数据源和数据处理的能力有着非常高的要求,而且数据辐射面积也会变得更大。这就要求应用侧增强智能化的数据在线加工能力,如向量、语义召回等。
第二个是 AIGC 平台工具层。目前以 Copilot 和 NL2SQL 等基于语义检索的能力为主,重点还是面向开发者提升开发效率。同时也有一些垂直行业,比如数据标注和面向垂直领域的一些开发属性链路的智能化提升,帮助分析师和数据使用者能够通过大模型降低基础的门槛,提升效率。
当前数据平台能力瓶颈
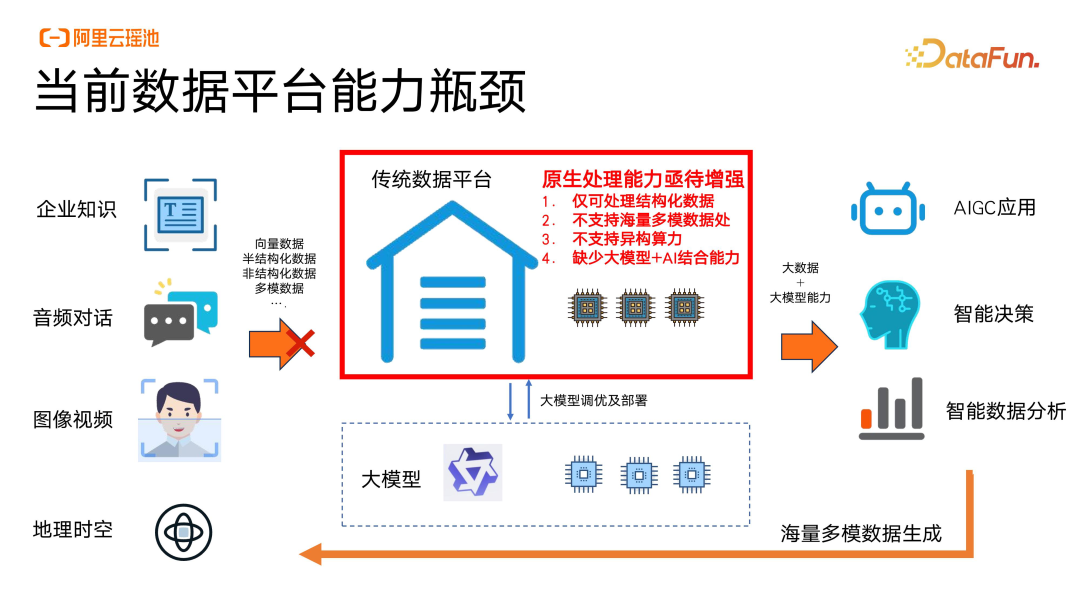
目前,传统的数据平台对多模数据的处理能力遇到了瓶颈。如文字、文本、音频、图像、地理信息这些数据的处理需要更加灵活的空间,接下来数据湖可能会成为主要的载体,并通过数据的分析引擎来处理、消化这些非结构化数据,拓广企业数据平台的覆盖面积。
由于 OLTP 平台只传入传统的结构化数据,目前已经不能很好地支撑企业的所有应用。所以企业的一些数据平台,包括传统的数仓,也要面向应用侧进行能力升级,把湖仓的能力上浮到应用侧。企业传统分离式的 OLTP 和 OLAP 平台可能在接下来一段时间内进行整合,并将部分应用下沉到湖仓一体的能力上,这对企业的数据平台是比较大的考验。
数据平台趋势分解

数据平台包含应用层、平台工具层和基础层。应用层的核心诉求是海量数据需要直接支持应用,集成方式更加灵活,比如企业的知识库、客服和 RAG 的一些场景。在平台工具层,我们希望把数仓的核心能力,比如数据分析能力、开发能力等和大语言模型进行结合,升级整体的能力。基础层则更多的是提供低成本的算力和存储。
一站式智能数据平台架构
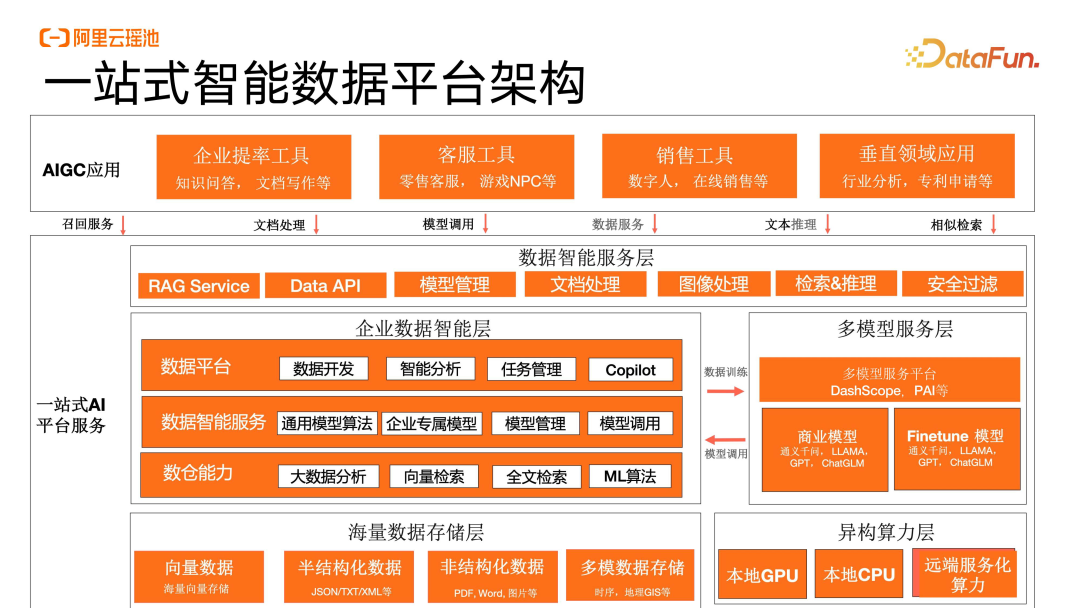
为了面向 AIGC 的业务和应用,我们将平台的数据能力向上浮了一层,也就是数据智能服务层,包括了 RAG Service、Data API、模型管理,同时也对文档处理、图像处理、检索推理和安全过滤等原子能力进行了覆盖,让上层应用能够更好地去直接访问中间的数据层。
对于企业核心的数据层,在保有数据平台和数仓、数据湖能力之上,我们添加了在仓内进行数据模型直接调用的方式。相比于企业原来对于数据只是做一些标准算子的分析,现在能够支持企业在仓内、湖内实现叠加上大语言模型的一些增强的分析能力。举个简单的例子,比如在文本中提取用户的情感倾向、核心关注点或者客诉客情申请。原来我们无法在仓内或者湖内直接实现,通过引入大语言模型到数仓、湖内,现在可以直接去调用这些非结构化数据进行快速的情感倾向判断,提升数据服务能力。同时这些能力也能反哺成为 NL2SQL 的支撑,通过自然语言的理解进行用户 Intention 的判断,然后投递成 SQL,转换到仓内湖内进行分析。
底层主要涉及对海量结构化、半结构化数据进行廉价的存储。为了支持海量数据的廉价存储,平台进行冷热数据的分离,确保对应用层的高性能支持。平台目前支持的异构算力包括 CPU、GPU 和远端服务化算力,对于向量检索、模型的使用资源也可以复用,避免了资源的浪费。
接下来将介绍阿里云AnalyticDB在相关领域上的一些探索。
阿里云AnalyticDB:在AIGC时代下,驱动企业架构升级

AnalyticDB是阿里云自研的云原生数据库,在数据仓库、语义检索、多模处理能力上面具备非常强的市场竞争力,被多个世界 500 强企业选为核心数仓系统。AnalyticDB 在 2020 年 TPC-H 30T 的评测结果为性价比世界第一,同时也是阿里云第一个被 OpenAI 的 Chatgpt-Retrieval-Plugin 项目推荐的向量数据库,也被 LangChain 等开源社区进行了集成。
AnalyticDB一站式湖仓设计
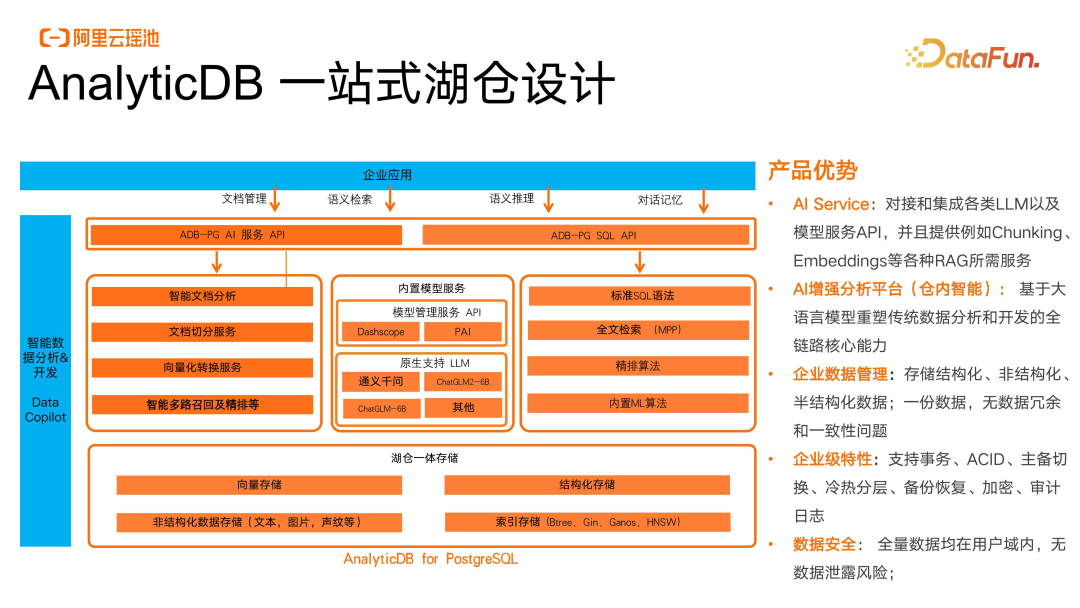
对于企业应用侧,我们通过 SQL API、服务 API,完成向量面向应用侧的加速和布局。并实现了在仓内通过内置的模型服务模块快速连接到自身企业部署的一些模型服务能力,同时将这些能力与原生的数据分析引擎进行了融合。所以无论是“通义千问”还是企业自己部署的私域模型,都可以直接在仓内进行数据的分析和检索,同时做一些非结构化数据的处理。底层湖仓一体的存储,我们通过分层对现有存储进行了解耦。配套的阿里云的数据库生态和开发工具,能够实现数据开发的Copilot在线支持,以及一站式自然语义的分析。
AI Service:大模型+湖仓RAG应用搭建
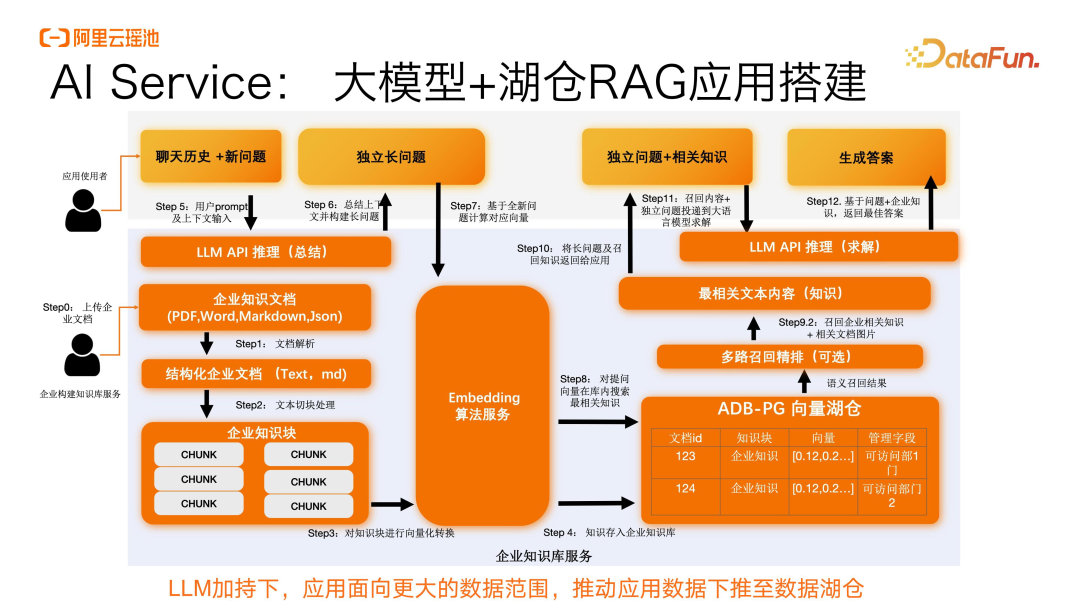
在面向应用侧的服务里面提供了一套 AI Service 的能力,包含了大模型和湖仓 RAG 的搭建。
为企业知识开发的阶段,提供了整套的 Data API,来支持企业快速进行数据湖的搭建,包括企业知识库构建的全流程、Embedding 算法的调用。对于数据入湖之后,提供了一套预检索、召回精排和面向推理的 API 和加速引擎。
AI增强分析平台-仓内智能
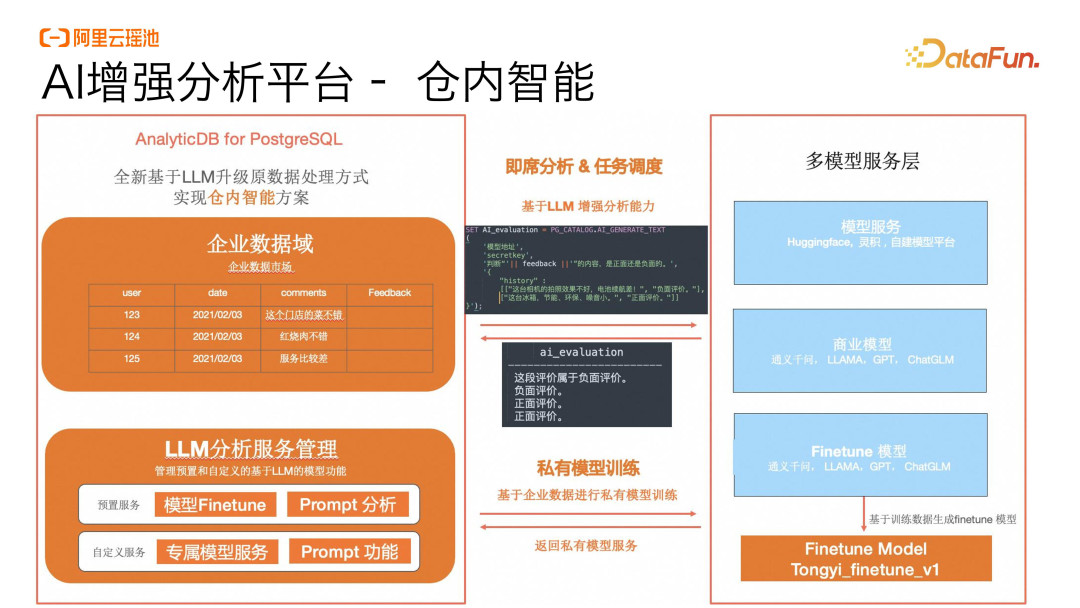
在 AI 增强分析平台上,可以支持企业对于一些业务场景进行快速的情感判断和分析。这里面包括了两个部分:
一个是传统的机器分析能力的增强,比如对某一系列的 Comments 进行情感分析的判断,我们实际上可以快速地在仓内构建一套情感分析的方式,通过调用一些企业自身的模型或者三方模型,快速地进行情感分析的判断,并结合原生的数据库引擎进行数据的持久化。通过这样的方式,对数据处理的效率会大幅增加,而且处理的难度会大幅降低。
AnalyticDB分布式架构设计
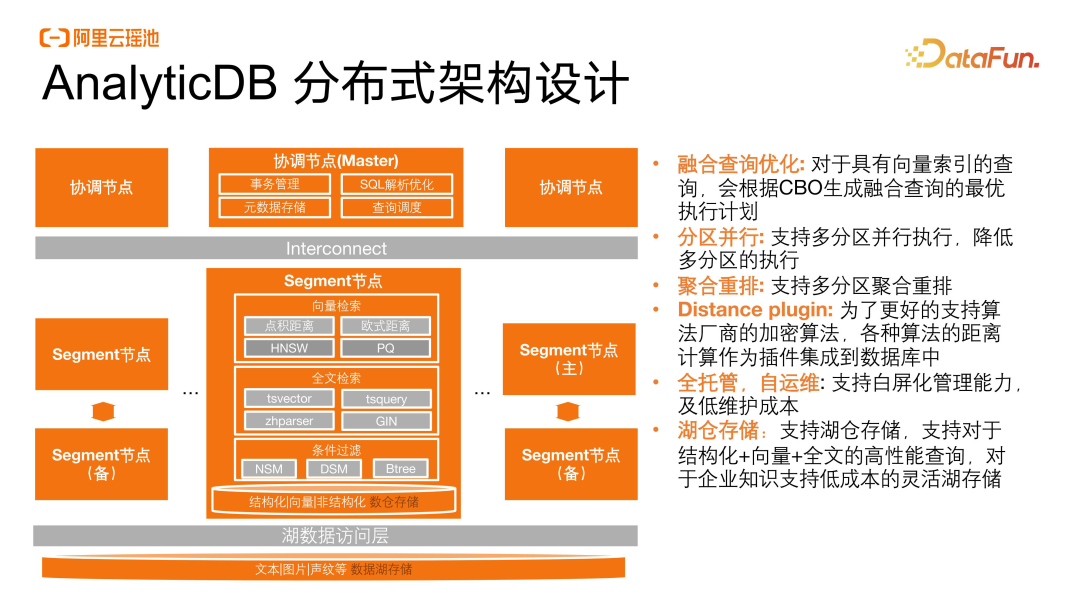
AnalyticDB采用的是分布式架构,在保有所有数据库能力的基础之上,支持所有语义相关的检索,包括了向量检索和全文检索。对于结构化向量和非结构化的全文检索,可以实现一站式的融合查询,并且通过 SQL 就可以直接实现语义查询。
AnalyticDB完备企业级能力

在实现了面向应用侧和自身的能力升级之外,AnalyticDB 保有了完备的企业级能力,包括写入事务的原子性。比如在做 AI 面向应用的支持时,对于语义查询存在的多路召回,可以在保证多路同时更新之后相关的事务才能被找到。同时它也是实时离在线一体的,对于实时数据写入、批量写入都可以支持不同接入方式和整套的update、delete操作。在高可用方面,可以同时支持多个向量索引构建,而且这些能力与同类产品相比更具完备性,更能够满足企业级的要求。
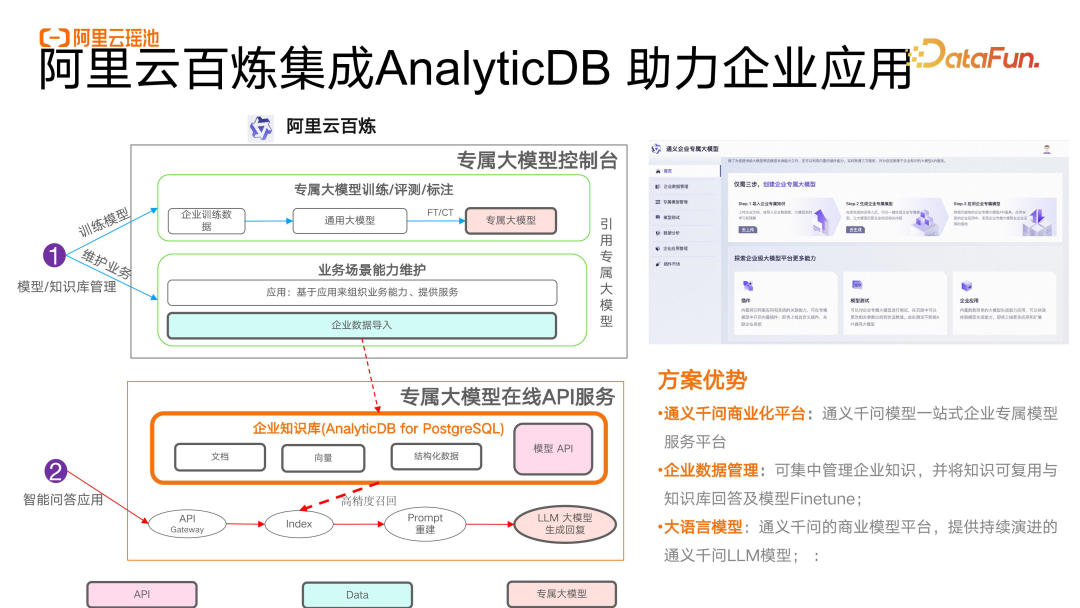
阿里云百炼集成AnalyticDB助力企业应用
钉钉群号:32960015260

问答环节
A:我们的产品在 2019 年的时候发布,使用的向量检索引擎是全自研的,当时面向的是万维以下的百亿数据量毫秒到秒的查询返回目标。一方面在指令侧做了相关的优化。另一方面,支持大规模数据的 PQ 降维。同时在参数和索引的构建上面也做了压缩和编码的优化,对 MPP 也做了一套适配,所以随着资源的增加,我们的并发检索效率是很高的。
END




点击了解 云原生数据仓库AnalyticDB
