





引言
随着大数据及AI时代的到来,数据安全和数据资产管理已经成为了企业和组织面临的重要挑战,国家金融监督管理局对数据分类分级的相关要求进行明确和强化,如何在数据价值释放的同时保障数据安全已成为企业的当务之急。本文结合腾讯云大数据WeData(一站式大数据开发治理平台)探索数据分类分级在某金融客户的应用实践和落地过程。
名词解释
面临的挑战
企业现状及传统解决方案的局限性:
数据安全防护孤岛:
产品堆砌、能力冗余、改造量大。 各自孤立的业务安全系统,形成了多个安全防护孤岛,无法有效联动形成以数据为核心的统一安全管理体系和防护能力。
企业对自身数据基本状况不清楚,安全管理难以下手。 数据业务域边界模糊,数据权属缺失。 缺乏对敏感数据自动定期发现/梳理手段,需要投入大量的人力。
缺乏对数据业务的基本认知,无法根据业务属性进行合理管控。
无法认识不同重要度、价值度的信息数据。
无法对核心/敏感/重要的数据数据针对性管理/防护。
传统数据安全已难以匹配数字化业务发展战略诉求。
数月甚至数年实施周期。
引入延迟造成业务性能下降,大数据量场景高达20%-40%延迟影响,造成安全策略难以实施。

数据分类分级在银行客户落地实践
我国在 2021 年发布了《中华人民共和国数据安全法》和《中华人民共和国个人信息保护法》两大法律,将数据安全提升到了新的高度。随着监管机构发布银行保险机构的安全管理办法,以及人民银行发布《中国人民银行业务领域数据安全管理办法(征求意见稿)》,对银行业数据安全提出了非常高的要求。
在此背景下,该银行客户需要完成数据分级分类以便后续准确识别需要重点保护的高敏感数据,以满足监管要求并确保数据安全。
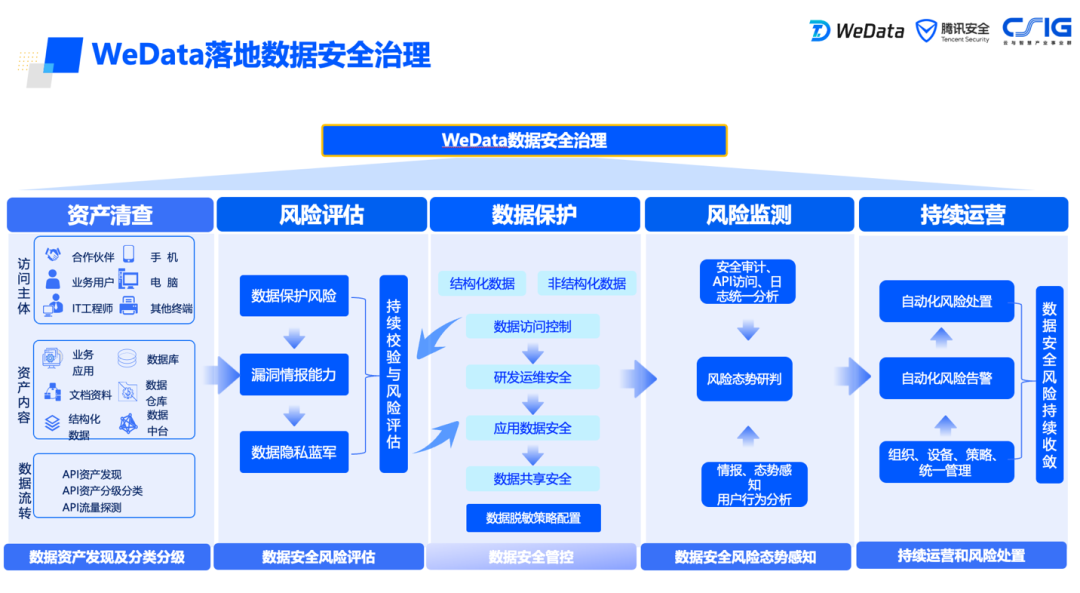
打通全局元数据,实现数据资产化管理全局视图; 适配行业监管要求,实现统一的分级分类敏感数据识别。
WeData平台提供了数据资产管理能力,以此实现数据资产化及统一视图展示,其中的关键步骤包括:
元数据采集:配置并采集了各个数据源的元数据,包括数据表结构、字段定义、数据类型、关系等信息。并通过自动化工具实现定期维护和更新元数据,以反映数据资产的变化和更新,确保元数据的准确性和及时性。 数据资产盘点:通过对元数据进行全面的清点和记录,扩展管理元数据和业务元数据,如明确责任人,数据归属部门,将数据挂载到数据资产目录上,增加业务描述和业务属性等,数据资产盘点的目的是建立一个全面的数据资产清单,以便组织能够更好地了解和管理自己的数据资产。 元数据关联和血缘分析:建立元数据之间的关联关系,包括数据表之间的关系、数据血缘关系等。这有助于理解数据的来源、流动和影响,提供更全面的数据资产视图。 通过以上步骤,可以建立一个统一的元数据管理系统,实现统一的数据资产视图。这将帮助组织更好地理解和管理数据资产,提高数据的可发现性、可理解性和可信度。
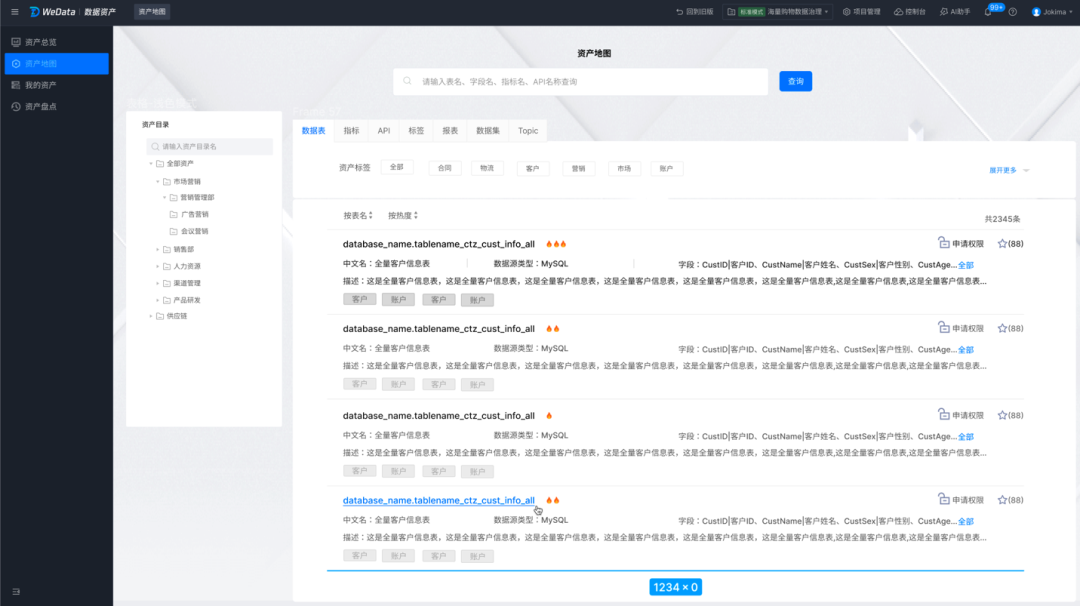
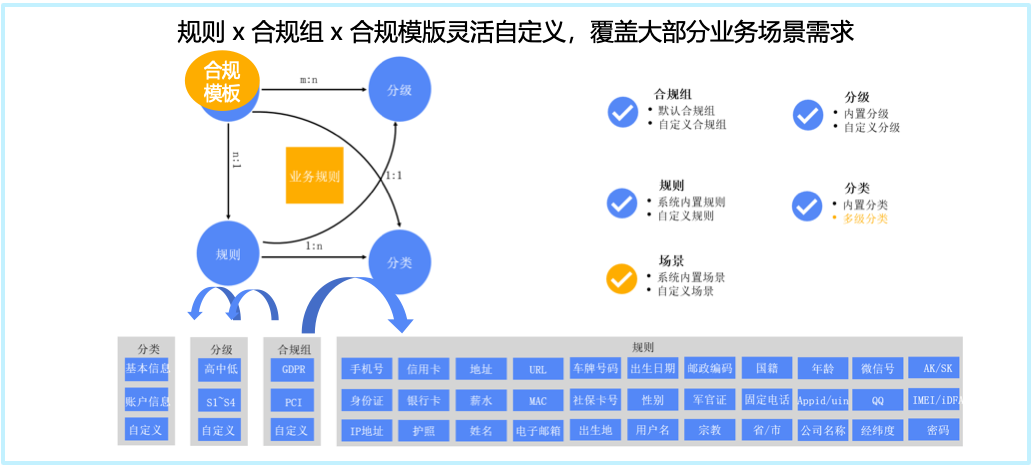
在完成智能分类分级之前,为了能够精确识别敏感数据,需要配置敏感数据识别模板,该模板涵盖了数据安全分类分级,数据识别规则等内容。各个国家和不同行业都有不同的分类分级标准,WeData中内置了国内金融行业分类分级模板的模板配置,如:GB/T 35273-2020《信息安全技术个人信息安全规范》、参考 JR∕T 0171-2020《个人金融信息保护技术规范》、参考 JR∕T 0197-2020《金融数据安全数据安全分级指南》等,也支持自定义配置分类分级模板。
参考国家法律法规、金融行业标准和客户自身数据资产现状来建立数据安全标签体系。
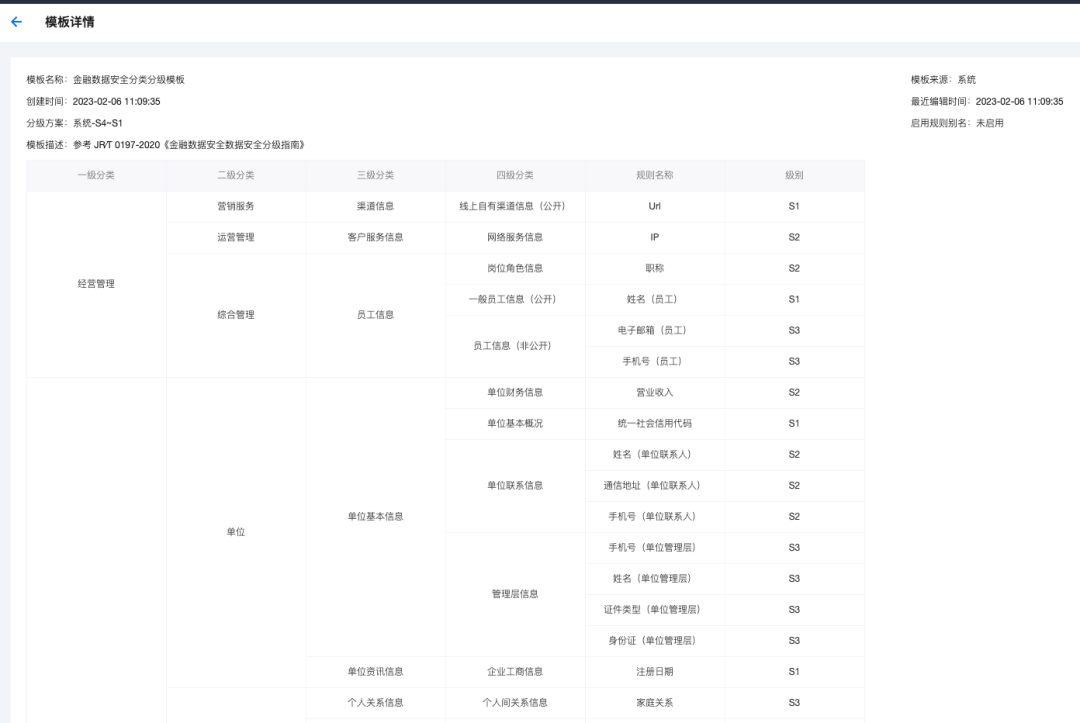
如上所示,准备好分类分级规则模板后,下一步就是进行敏感数据识别。通过敏感识别引擎,根据不同标准的分类分级模板进行数据资产的扫描和自动分类分级打标。
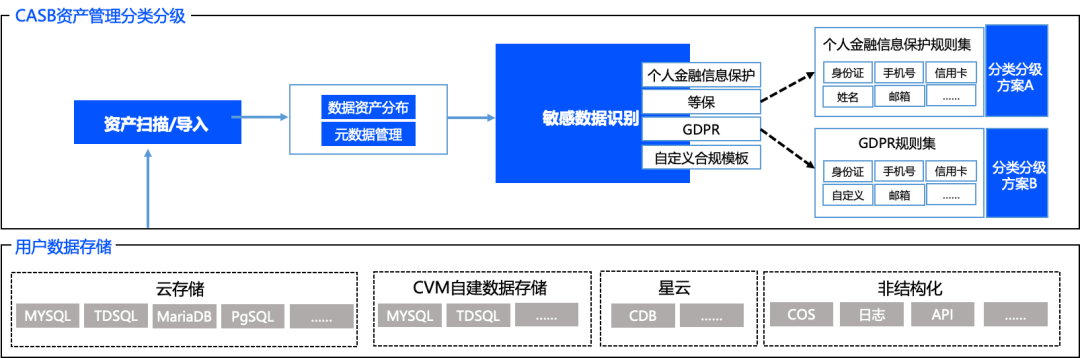
通过敏感识别与平台元数据和数据资产结合,我们可以获得以数据资产视角展示敏感数据分布结果,包括:
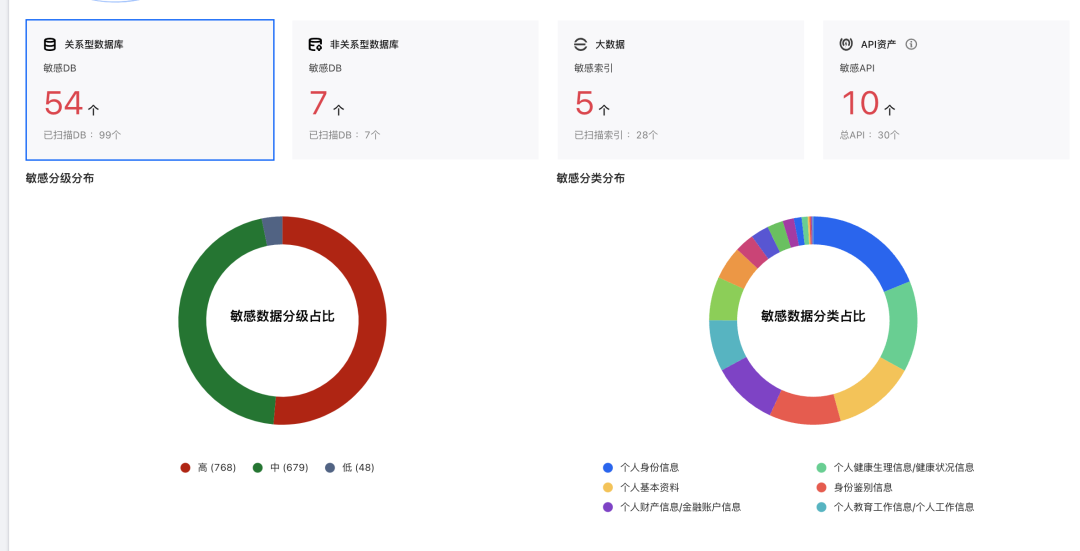
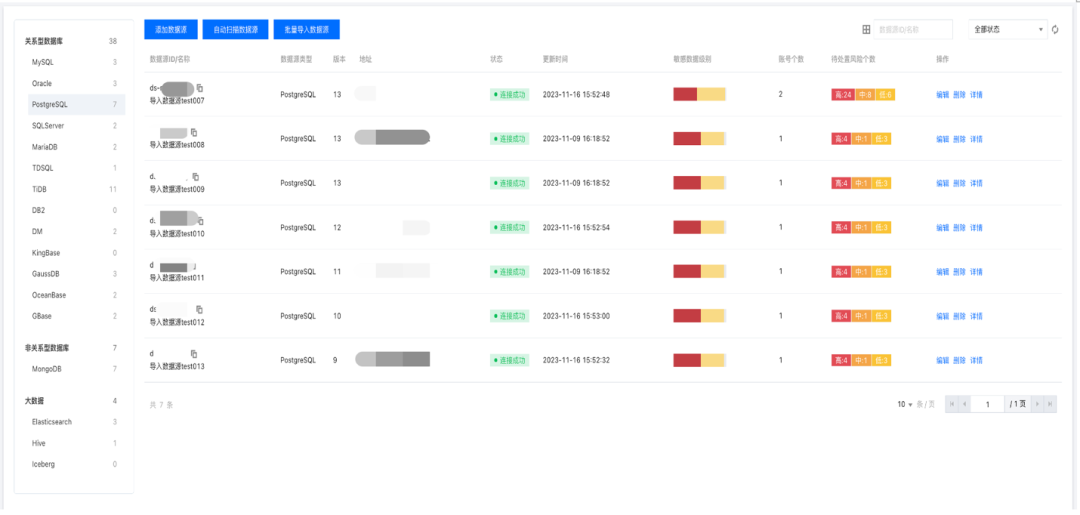
针对统一存储的数据资产进行敏感数据分类分级和识别,即可从全局获得数据的全貌,为后续的数据安全治理打下基础。以上过程通过WeData平台自动完成,这个过程中有哪些需要关注的点呢?我们总结出以下几点:
通过分层服务架构、预处理、水平扩容、并行计算、采样检测等机制,保障对海量数据检测的高性能。 内部引擎月均接入2.4W+库,稳定运行。
通过结构化引擎和非结构化引擎支持不同业务各类数据类型:
csv, excel, log, txt 等文本类。 API请求,云审计等 json类。 数据库 KV类。
算法、关键字、语义、正则等,发现数据特征。 在特征项基础上,加入业务特征识别,实现数据标识。 可信分 x 算法 x 人工打标,持续提升数据识别准确率。
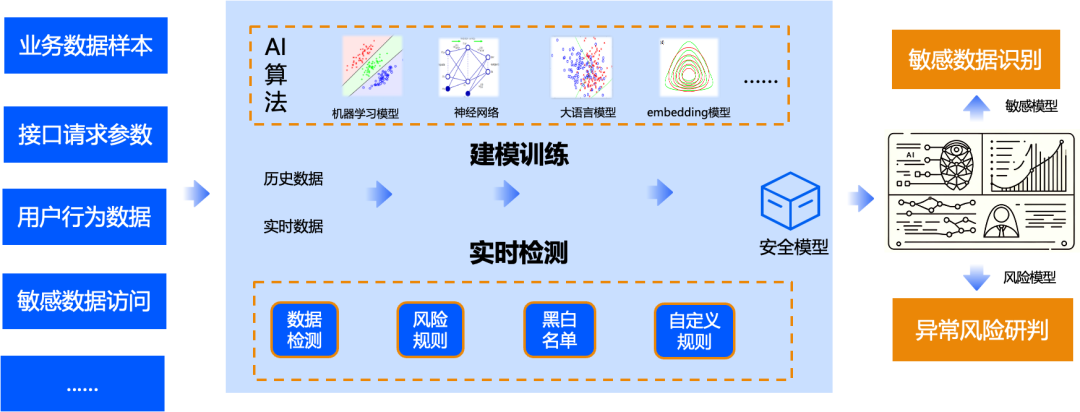
另外,因一些原因,还需要人工打标和复核,如:首先,进行人工打标,向智能打标模型提供训练集,进行训练;然后,智能打标模型生成打标结果;最后,再进行人工复核,随着准确率提升,人工复核不再进行大批量、全部的复核,而是仅做小部分抽样的人工复核。最终,打标结果有两个方向,一个是结果直接上架提供给各个数据平台使用;另一方面,将人工复核发现的错误反馈给模型进行优化,实现循环优化。
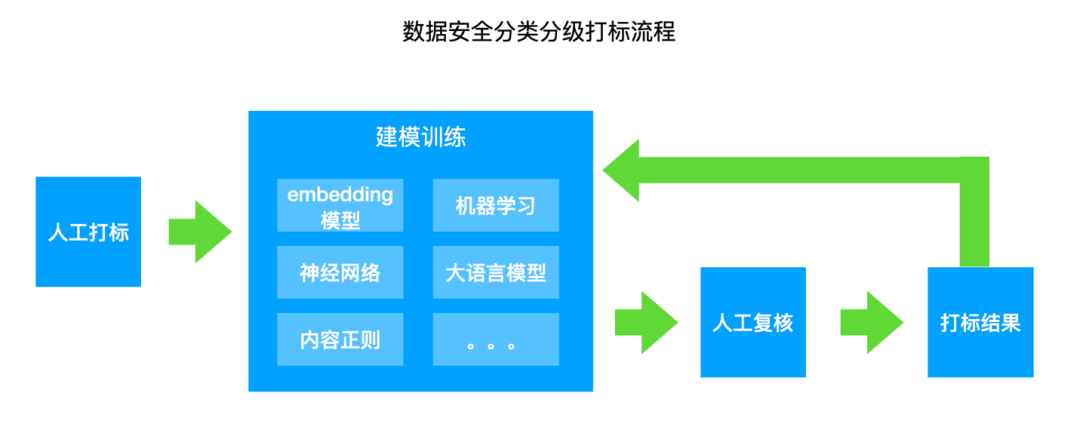
打标流程包括人工打标、智能打标模型训练和人工复核,形成最终打标结果。自动化打标识别准确率达到是95%,经过人工确认后达到100%。
高效及高准确率的数据识别与分类分级引擎确保了在大数据下可持续的自动定期获取和更新敏感数据数据,为数据安全后续打下了坚实基础,如帮助客户使用分类分级结果对银行敏感信息进行脱敏保护,比如根据保护措施要求,对客户余额加密,身份证掩盖等等,并在智能分类分级平台识别出全行的敏感字段数量和位置,一旦查询或展示这些数据,保护措施就能直接落地。
最后,依托平台轻量化和免改造的特性,基于安全能力,高性能,高稳定性,数据安全管控性能损耗控制在5%以内,不造成业务性能瓶颈。一键部署,简化配置运维管理工作。
应用程序和数据库不需要改造即可完成数据安全能力的接入,部署速度快,扩展能力强。
总结
关注腾讯云大数据公众号
邀您探索数据的无限可能

点击阅读原文,了解更多产品详情
↓↓↓
