




人工智能有三要素:算力、算法、数据。其中算力又是最基础部分,它的价值等同于工业时代的石油,离开了算力,构建人工智能就是空中楼阁。最近AI大神山姆.奥特曼要融资7万亿美元开发算力芯片冲上全球热搜,美股英伟达股价冲破2万亿美元,ARM股价数月之间翻了三倍,超过1200亿美元,国家从上层到地方准备大力推进算力基础设施建设,都说明了算力对人工智能产业发展的巨大影响,和它在未来的不可缺失地位。
由于算力对人工智能的巨大赋能作用,最近各路大V宣传算力重要性的文章和短视频也越来越多,但是算力到底是什么,很多自媒体鲜有提及,加上各种带节奏文章,和所谓遥遥领先的言论,把简单的技术和产品问题搞得云山雾罩,所以今天就重点说说构成算力的几个要素,希望本篇能起到正本清源的目的,网上少点带节奏、自嗨遥遥领先的狂妄想法。
之前我在文章中说过,人工智能算力是一个技术体系,从属性上分为硬件算力和软件算力两部分。硬件算力的主角是算力芯片以及服务算力芯片的各种硬件设备。软件算力是各种编程接口,以及编程接口依赖的操作系统。这是算力的基本构成,下面展开说一说。
硬件算力
硬件算力有三个主角:算力芯片、卡间通信、算力网络
算力芯片
算力芯片是整个算力体系的核心部件,用于处理大规模数据和执行复杂计算的芯片,它们分为多种类型,其中CPU(中央处理器)和GPU(图形处理器)是最常见的两种。在人工智能产业早期,算力芯片以CPU为主,但是随着计算规模增加,GPU在单位时间内提供的计算能力远超CPU,算力芯片也从CPU转向以GPU。目前二者的分工是:CPU承担指挥者的角色,管理算力服务器,GPU负责工作者的角色,执行大规模计算工作。
GPU替代CPU成为AI计算的根本原因,在于GPU是并行计算,而CPU是串行计算,并行计算能够近乎无限增长,串行计算却无法实现这一点。以英伟达发布的几款算力卡为例,在这些GPU内部,有数千个乃至上万个计算核心,规模远远超越任何一款CPU。当GPU计算核心并行参与AI计算工作时,相比CPU的串行计算是指数提升。GPU取代CPU,成为计算主流,是一种计算范式的变革,未来不止AI,所有计算业务,都将从串行计算改为并行计算。
目前的GPU市场,英伟达是算力芯片的主导者,国内一些厂商,比如华为、摩尔线程、海光,也推出了针对算力市场的芯片,但是由于它们刚刚发展起来,还不足构成对英伟达的影响。
评价一块GPU的性能,主要看双精度浮点(FP64)、单精度浮点(FP32)、整数计算(INT8、INT4)几项指标,数值越大计算能力越算。随着业务需求多样化,一些新型的算力芯片,如NPU(神经网络处理器)和ASIC(专用集成电路)等也逐渐出现。这些芯片针对具体应用场景进行优化,具有更高的计算效率和更低的能耗,将在特定领域发挥作用。

卡间算力
卡间算力是一个新概念,以英伟达的DGX/HGX算力服务器为例,它们的主要面向深度学习和高性能计算。在这些算力服务器内部,通常会有2块以上的GPU。为了实现通信和数据传输,协调多卡并行计算,保证高效的并行计算效果,就产生GPU与GPU之间通信的需求。这种情况,在其它的算力服务器,比如华为的 Atlas集群上同样存在。
卡间通信只用于算力服务器内部,目前卡间通信主流有两种:NVLink、PCIe。NVLink是英伟达产品,用于CPU和GPU、GPU和GPU之间的连接,传输速率达到50G/秒。PCIe是一款标准化产品,传输速度4G/秒。由于NVLink传输性能太过优秀,已经进入米国禁令名单,不过有一个好消息是,华为也研发了用于卡间通信硬件组件,传输速率达到30G/秒,已经用在Atlas算力集群。
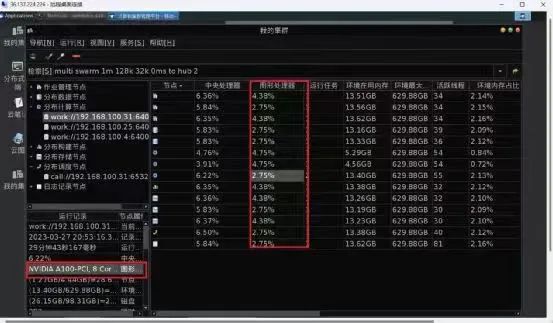

算力网络
与卡间通信不同,算力网络被用来连接算力服务器,来组成计算能力超强的算力集群。与卡间通信类似,算力网络也需求有强大的通信和数据传输能力,目前主流的算力网络是RDMA。
RDMA(Remote Direct Memory Access,远程直接内存访问)网络解决网络传输中服务器端数据处理的延迟。与传统的Socket通信方式相比,RDMA在数据收发过程中绕过了操作系统内核,数据交换过程并不需要CPU参与,报文的组装和解析是由硬件完成的,从而大大提高了数据传输的效率。
在RDMA通信过程中,客户端和服务器分别通过系统调用创建好通信所需要的内存资源。服务器通知硬件准备接收数据,并告诉硬件将接收到的数据放在哪片内存中。客户端通知硬件发送数据,并告诉硬件待发送数据位于哪片内存中。然后,客户端的RDMA网卡从内存中搬移数据,并组装报文发送给对端。服务器收到报文后,对其进行解析并通过DMA(直接内存访问)将有效载荷写入内存。最后,服务器以某种方式通知上层应用,告知其数据已接收并妥善存放到指定位置。
目前RDMA网络有两个流派:IB网络和RoCE网络。其中IB网络有更高的传输效率,但是价格也更为昂贵,比如微软Azure云就采用了IB网络。RoCE网络性能略低一些,不过同时价格相对较为便宜。
在算力网络中,另一个主角是算力网络交换机,已经有多家国际企业布局这个市场,包括中国企业也多有参与,英伟达的NVSwitch是其中一个佼佼者。

软件算力
软件算力有两个主角:算力操作系统、算力编程接口。
算力操作系统
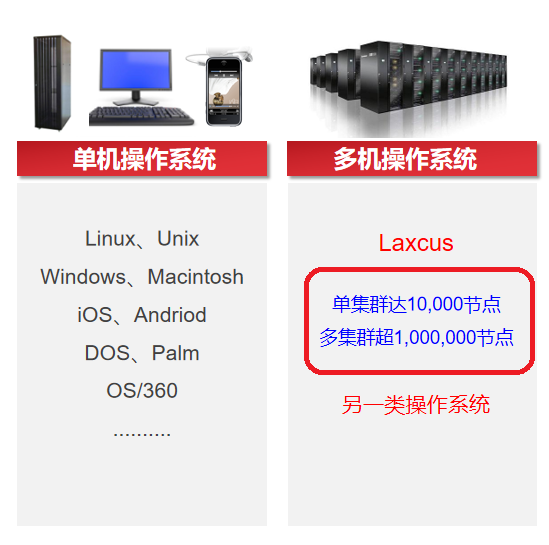
目前算力操作系统的主角是Linux。但是就像CPU和GPU的关系一样,Linux本质是一个单机操作系统,它只能提供对一台计算机和计算资源的管理和维护,而AI计算是一个分布式的大规模并行计算过程,所以Linux并不完全适合人工智能和高性能计算领域。这时操作系统市场就出现了这样一个缺口:市场需要一种新的操作系统,这种操作系统能够管理海量的计算机,并把海量的算力资源聚合起来,集中输出给AI和其它高性能计算业务。
Laxcus分布式操作系统是针对AI计算业务设计的操作系统,它实现了一项重要基础创新:即能够把一堆物理的硬件的计算机组成一台虚拟的软件的超级计算机。在实际的物理层面,Laxcus管理着各种软硬件资源,在虚拟的逻辑层面,用户操作起来就像是在使用一台计算机。由于Laxcus完成了海量计算机的计算资源的聚合工作,做到统一对外输出,它能够更加胜任大规模和分布式的计算业务。
除此之外,Laxcus分布式操作系统还完成诸多其它基础创新,其中最重要是Laxcus将单集群节点上限规模扩大到1万台计算机左右,在此基础上,又实现了多集群并行管理能力,将多集群的计算节点进一步增加到100万台以上 。这个规模,足以将中国国内所有所有算力中心的服务器组织到一起,形成一个超级巨大的算力矩阵,统一管理统一维护统一调度。由于Laxcus提供了如此强大的并行计算和管理能力,不止是人工智能,很多超大规模的计算业务,包括大数据、高性能计算,它们的计算工作都变成唾手可得。在算力主导一切计算业务当下,Laxcus分布式操作系统的重要意见可见一般。
由于人工智能对算力的巨大需求,已经可以预见的是,未来的算力操作系统,也会像GPU取代CPU一样,从执行串行处理的单机操作系统转向并行处理的多机分布式操作系统。
算力编程接口
如果说算力操作系统的工作是完成计算资源的聚合和管理,那么算力编程接口的工作就是服务应用软件开发者,通过开发者编程调用算力编程接口,实现芯片算力的聚合和输出。算力编程接口目前主要分为两种:卡间计算编程接口、网络计算分布式编程接口。
1. 卡间计算编程接口
卡间计算编程接口对应卡间计算。通过卡间计算编程接口,将算力芯片、驱动程序、函数库、编程器、调试器和开发者链接到一起,目前卡间计算编程接口的代表是英伟达的CUDA(Compute Unified Device Architecture)。
CUDA有以下特点和优势:
并行处理能力:
CUDA利用GPU的并行处理能力,使得可以同时执行多个任务,大幅度提高了计算效率。GPU拥有大量的核心,每个核心都可以独立执行指令,实现高效的并行计算。CUDA通过线程块(Block)和线程(Thread),实现了并发执行和并行计算。在一个线程块包含多个线程,这些线程可以并行执行相同的指令,以实现高效的并行计算。此外,CUDA还支持线程之间的同步和通信,来满足高复杂的计算需求。
易于编程:
CUDA提供了类似于C/C++的编程接口,使得开发者可以轻松地编写GPU程序。CUDA C/C++是一种扩展的C/C++语言,它增加了一些新的关键字和函数,用于描述并行计算的任务和数据。
高效的内存管理:
CUDA具有高效的内存管理机制,可以充分利用GPU的内存资源。它提供了统一的内存管理机制,使得主机(CPU)和设备(GPU)之间的数据传输更加高效。此外,CUDA还支持零拷贝(Zero-Copy)技术,可以避免不必要的数据复制和传输。
广泛的应用领域:
CUDA不仅适用于图形渲染、物理模拟等领域,还广泛应用于深度学习、数据挖掘等机器学习领域。随着人工智能和大数据技术的快速发展,CUDA的应用前景越来越广阔。
除此之外,AMD发布了ROCM,国内海光发布了DTK,它们目前处于追赶者的状况,无论是应用生态还不足以对CUDA构成威胁,各种算力应用开发者有兴趣可以试一试。

2. 算力网络编程接口
算力网络编程接口对应算力网络。不同卡间计算编程接口限于一台算力服务器,算力网络编程接口面对的是整个计算机集群,所以二者的应用场景完全不同。
在算力网络编程接口这个领域,Laxcus分布式操作系统提供了DSDK(Distributed SDK),它有以下特点和优势。
基本特点:
DSDK是允许开发者在单机操作系统上编写、在计算机集群部署和运行分布式应用程序。
与传统的SDK(软件开发工具包)不同,DSDK完全面向分布式处理作业,支持在多个计算机节点上并行执行代码,让应用业务充分利用集群的计算资源。
DSDK在总结多种计算框架不足的基础上,采用了大量新的分布式计算理念,具备敏捷开发、可持续交付、快速部署、快速迭代和容器管理等特点。这意味着开发者可以更加高效地开发、测试和部署分布式应用程序,提高开发速度和响应能力。
编程模型与接口:
DSDK提供了多种分布式编程模型,开发者在使用DSDK进行编程时,需要遵循这些分布式编程模型的规范,将应用业务嵌入到编程接口中。DSDK提供了一组丰富的API,用于处理分布式数据、通信、任务调度等任务。开发者可以通过调用DSDK的API来指定分布式应用程序的行为和逻辑。例如,开发者可以使用DSDK提供的接口来分配任务到不同的计算机节点上,实现并行计算和数据处理。
使用体验与兼容性:
对于使用过Windows或Linux等操作系统的开发者来说,Laxcus的DSDK提供了类似的使用体验。开发者可以使用熟悉的编程工具和界面来开发分布式应用程序,降低了学习成本。
Laxcus的分布式应用软件提供图形和字符界面,这使得使用操作变得更加直观和简单。开发者可以轻松地管理集群、监控任务执行情况、查看日志等。
总之,Laxcus的DSDK是一个功能强大、易于使用的分布式软件工具包。它提供了丰富的API,支持高效、快速地开发、部署和运行分布式应用程序,为开发者提供了更加灵活和可扩展的编程环境。

Laxcus分布式操作系统研发团队正在扩招中,岗位包括:技术合伙人、项目主管、核心开发人员,公司提供了丰厚的股权和期权奖励,欢迎“有想法”和“不安分”的小伙伴联系我,加入Laxcus分布式操作系统研发团队,抓住人工智能浪潮红利!

