




etl engine 实现 redis与mysql之间的数据同步
Redis是一个开源的使用C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,
因其读取速度快、也可用于消息队列使用等场景,已经成为项目中不可缺少的一部分。
本案例是通过etl engine实现redis与mysql之间的数据同步。
需求
读redis写mysql; 读mysql写redis
前置条件
事先准备一个可读写redis服务器;一个可读写mysql服务器;
读redis的key写到mysql的t_redis_info表;读mysql的t_redis_info表记录写到redis
- MySQL模拟数据
CREATE TABLE t_redis_info ( id VARCHAR(32) NOT NULL, caption VARCHAR(50), tag VARCHAR(50), memo VARCHAR(100), writetime VARCHAR(19), PRIMARY KEY (id) ); INSERT INTO t_redis_info(id,caption,tag,memo,writetime) VALUES ('1','herbin_beer_550','啤酒','哈尔滨雪花550ML','2023-01-01 11:12:13'); INSERT INTO t_redis_info(id,caption,tag,memo,writetime) VALUES ('2','qingdao_beer_550','啤酒','青岛纯生550ML','2023-01-02 01:02:03'); INSERT INTO t_redis_info(id,caption,tag,memo,writetime) VALUES ('3','qingdao_beer_330','啤酒','青岛干啤330ML','2023-02-03 01:02:03'); INSERT INTO t_redis_info(id,caption,tag,memo,writetime) VALUES ('4','herbin_beer_330','啤酒','哈尔滨勇闯天涯330ML','2023-02-03 01:02:03'); INSERT INTO t_redis_info(id,caption,tag,memo,writetime) VALUES ('5','budweiser_beer_330','啤酒','美国百威330ML','2023-03-04 01:02:03'); INSERT INTO t_redis_info(id,caption,tag,memo,writetime) VALUES ('6','wahaha_water_600','纯净水','娃哈哈600ML','2023-03-04 01:02:03'); INSERT INTO t_redis_info(id,caption,tag,memo,writetime) VALUES ('7','nongfushanquan_water_600','纯净水','农夫山泉600ML','2023-03-05 01:02:03');
配置模型图
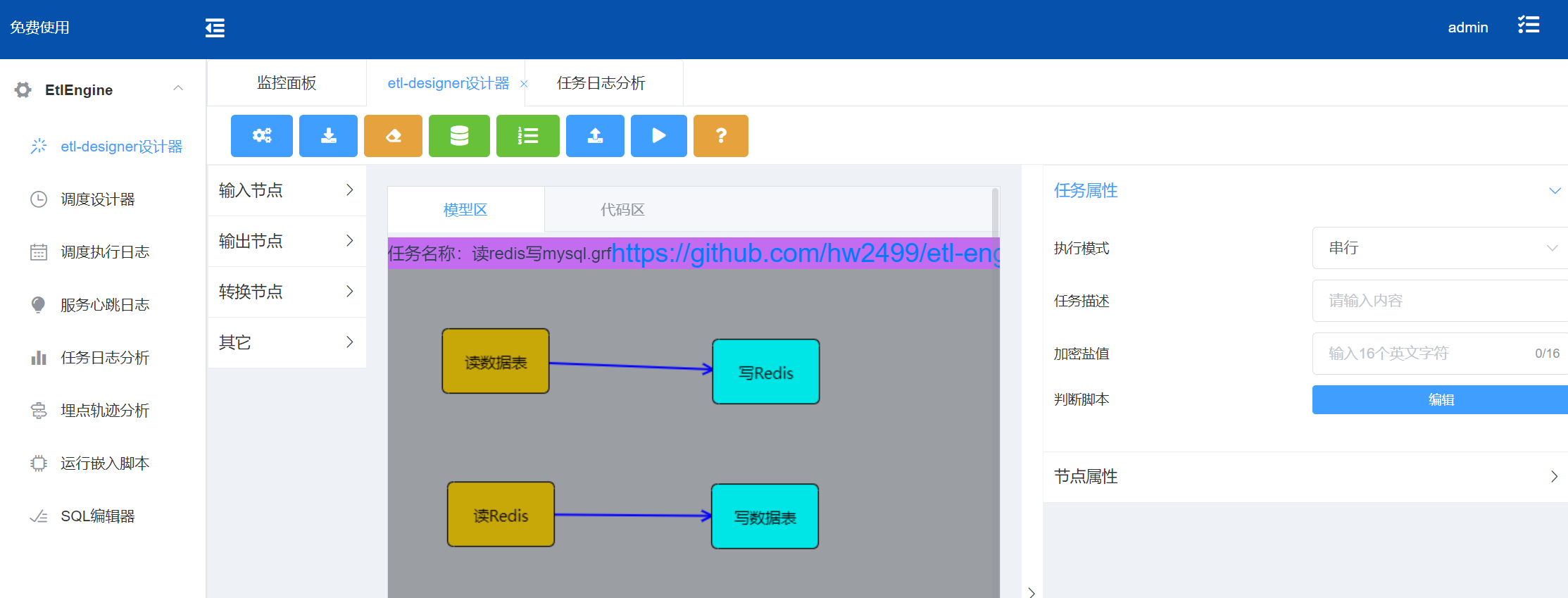
配置文件内容
<?xml version="1.0" encoding="UTF-8"?> <Graph runMode="1"> <Node id="DB_INPUT_TABLE_1" type="DB_INPUT_TABLE" fetchSize="1000" dbConnection="CONNECT_1" desc="读数据表" > <Script name="sqlScript"> <![CDATA[ SELECT caption AS k ,CONCAT(id,';',caption,';',memo,';', tag) AS v FROM t_redis_info]]> </Script> </Node> <Node id="DB_OUTPUT_TABLE_1" type="DB_OUTPUT_TABLE" dbConnection="CONNECT_1" outputFields="id;caption;memo;tag;writetime" renameOutputFields="id;caption;memo;tag;writetime" desc="写数据表" > <Script name="sqlScript"> <![CDATA[INSERT INTO t_redis_info (id,caption,memo,tag,writetime) VALUES(?,?,?,?,?);]]> </Script> <BeforeOut> <![CDATA[package ext import ( "errors" "fmt" "strconv" "strings" "time" "github.com/tidwall/gjson" "github.com/tidwall/sjson" "etl-engine/etl/tool/extlibs/common" ) func RunScript(dataValue string) (result string, topErr error) { newRows := "" rows := gjson.Get(dataValue, "rows") for index, row := range rows.Array() { //增加一个字段名称为id的列 tmpStr, _ := sjson.Set(row.String(), "id", common.GetUUID() ) //将系统默认输出的value字段拆分,并创建多个字段 values := gjson.Get(row.String(),"value").String() vArr := strings.Split(values, ";") caption := vArr[1] memo := vArr[2] tag := vArr[3] tmpStr, _ = sjson.Set(tmpStr, "caption", caption ) tmpStr, _ = sjson.Set(tmpStr, "memo", memo ) tmpStr, _ = sjson.Set(tmpStr, "tag", tag ) tmpStr, _ = sjson.Set(tmpStr, "writetime", time.Now().Format("2006-01-02 15:04:05")) common.GetLogger().Infoln("新行数据结构tmpStr:",tmpStr) newRows, _ = sjson.SetRaw(newRows, "rows.-1", tmpStr) } return newRows, nil }]]> </BeforeOut> </Node> <Node id="REDIS_WRITER_1" type="REDIS_WRITER" nameServer="127.0.0.1:16379" password="******" db="1" isGetTTL="false" patternMatchKey="true" outputFields="k;v" renameOutputFields="key;value" desc="写redis" /> <Node id="REDIS_READER_1" type="REDIS_READER" nameServer="127.0.0.1:16379" password="******" db="1" isGetTTL="false" patternMatchKey="true" keys="*" desc="读redis" /> <Line from="DB_INPUT_TABLE_1" to="REDIS_WRITER_1" type="STANDARD" order="0" metadata="METADATA_1" id="LINE_STANDARD_1"/> <Line from="REDIS_READER_1" to="DB_OUTPUT_TABLE_1" type="STANDARD" order="1" metadata="METADATA_2" id="LINE_STANDARD_2"/> <Metadata id="METADATA_2" > <Field name="id" type="string" default="" nullable="true" errDefault="" dataFormat="" dataLen=""/> <Field name="caption" type="string" default="" nullable="true" errDefault="" dataFormat="" dataLen=""/> <Field name="memo" type="string" default="" nullable="true" errDefault="" dataFormat="" dataLen=""/> <Field name="tag" type="string" default="" nullable="true" errDefault="" dataFormat="" dataLen=""/> <Field name="writetime" type="string" default="" nullable="true" errDefault="" dataFormat="" dataLen=""/> </Metadata> <Metadata id="METADATA_1" > <Field name="key" type="string" default="" nullable="true" errDefault="" dataFormat="" dataLen=""/> <Field name="value" type="string" default="" nullable="true" errDefault="" dataFormat="" dataLen=""/> </Metadata> <Connection id="CONNECT_1" type="MYSQL" dbURL="127.0.0.1:3306" database="db1" username="root" password="******" /> </Graph>
总结主要配置环节
- 配置串行执行任务
Graph标签中 设置 runMode=“1” ,使下面两个任务流可以按order配置的顺序执行。 - 画两个任务流
两个连接线中order属性分别设置0 和 1,任务执行行先执行order为0的任务,再执行order为1的任务。
第1个任务流(读mysql -> 写redis)
第2个任务流(读redis -> 写mysql) - 第1个任务流
- 读数据表节点设置
script 属性
SELECT caption AS k ,CONCAT(id,’;’,caption,’;’,memo,’;’, tag) AS v FROM t_redis_info
caption为redis中的键名称,组合的v为redis中的键值内容. - 写redis节点设置
patternMatchKey=“true”
outputFields 设置 k;v
renameOutputFields 设置key;value
系统默认会为redis的输出数据流生成key和value两个字段的数据结构 - 创建元数据 METADATA_0 结构是两个字段 key和value
连接线中order属性设置0 ,元数据选择 METADATA_0
该元数据用于写redis节点输出数据流时使用。
- 第2个任务流
- 读redis节点设置
patternMatchKey=“true”
keys="*" - 写数据表节点设置
script 属性
INSERT INTO t_redis_info (id,caption,memo,tag,writetime) VALUES(?,?,?,?,?);
outputFields 设置
id;caption;memo;tag;writetime
注意,通过嵌入go脚本来重新处理输入数据流中的各字段,因此outputFields中设置的字段名称要跟脚本中创建的字段名称相符
renameOutputFields 设置
id;caption;memo;tag;writetime
注意outputFields和renameOutputFields字段个数保持一致 - 嵌入go脚本,增加一个字段名称为id,调用了内置函数生成uuid
BeforeOut标签中嵌入go脚本,目的是将输入数据流结构转换成目标表中的各字段结构。 - 创建元数据METADATA_1 结构是5个字段 id,caption,memo,tag,writetime
连接线中order属性设置1 ,元数据选择 METADATA_1
该元数据用于写数据表节点输出数据流时使用。
输出结果图
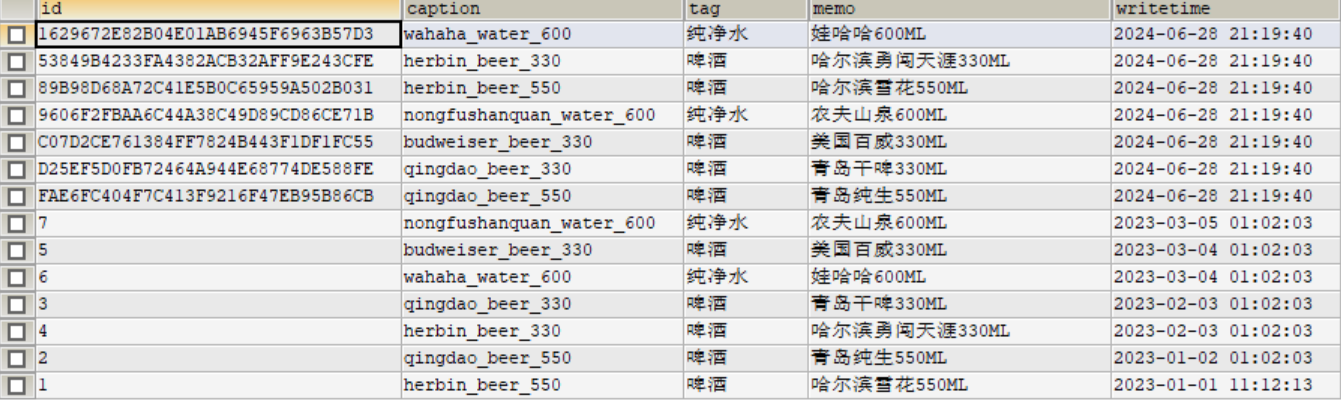
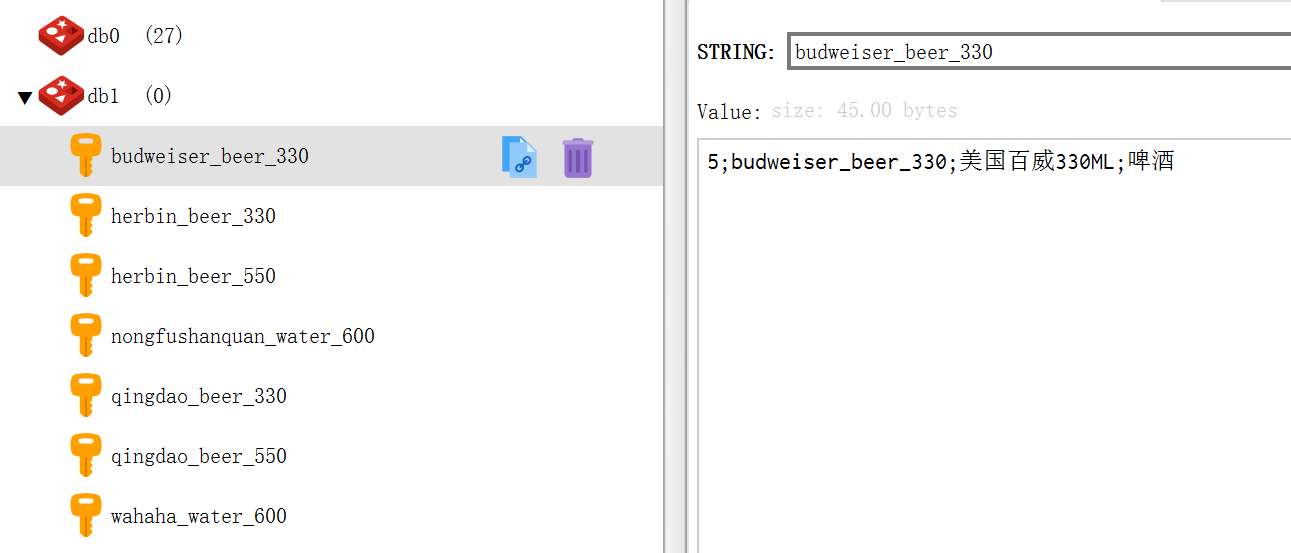
最后修改时间:2024-06-28 21:28:11
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
