




在过去三年中,DuckDB 的速度提升了 3-25 倍
title: Benchmarking Ourselves over Time at DuckDB[1]
author: Alex Monahan
TL;DR: 在过去三年中,DuckDB 的速度提升了 3-25 倍,并且可以在相同的硬件上分析规模扩大 10 倍的数据集。
写在前面
DuckDB这几年可以说发展神速,我是2020年第一次知道了DuckDB,被它的性能惊艳到,然后糊了个勉强能用的duckdb_fdw[2]。
这篇文章作者回归了过去三年的性能增强,他没有去和别的产品做横向对比,而是选择了和自己做纵向对比,也是很难得的一个思路。
另外作者也比较严谨地从多个维度做了对比。
从查看交互式图表的角度出发,我建议看原文。
正文
DuckDB 一直致力于为开发者提供卓越的数据处理体验。然而,性能是选择数据管理系统时不可忽视的重要因素。公平地使用基准测试比较不同的数据处理系统并非易事[3]。基准测试的设计者往往对某个系统更加熟悉,这可能会影响基准测试的选择、参数调整的时间投入等等。
因此,本文着重于对 DuckDB 自身性能的长期基准测试。 这种方式避免了许多比较陷阱,并为选择合适的系统提供了一些有价值的参考点。
• DuckDB 的改进速度如何? 学习新工具需要投入时间和精力。选择一个充满活力、快速改进的数据库可以确保您的投资在未来几年持续受益。此外,如果您已经有一段时间没有使用过 DuckDB,您可以通过本文了解它自您上次使用后性能提升了多少!
• DuckDB 特别擅长哪些方面? 基准测试的选择反映了该工具所适用的工作负载类型。基准测试中涵盖的分析类型越丰富,该工具的应用范围就越广泛。
• DuckDB 可以处理什么规模的数据? 许多基准测试的数据规模故意设置得比典型工作负载要小,以便在使用多种配置运行时,基准测试能够在合理的时间内完成。然而,在选择系统时,一个需要明确的关键问题是,您现有的计算资源是否能够处理您所面对的数据规模。
然而,评估系统性能随时间的变化也存在一些局限性。例如,对于全新的功能,由于缺乏历史数据,我们无法将其性能与之前的版本进行比较。因此,本文将重点关注 DuckDB 的基础工作负载,而不是其不断扩展的与各种数据湖格式、云服务等集成的功能。
此外,为了保持与早期版本的兼容性,本文使用的基准测试代码避免使用 DuckDB 更友好的 SQL 的许多新增功能,因为这些功能是最近才添加的。(编写这些查询的过程仿佛让人回到了过去!)
基准测试设计概述
本文使用 H2O.ai 基准测试[4],以及一些新增的用于测试导入、导出和窗口函数性能的基准测试,来评估 DuckDB 性能随时间的变化。有关我们选择 H2O.ai 基准测试的原因,请参阅我们之前的博客文章[5]和文章[6]。基准测试设计的完整细节请参见附录。
• 基准测试基于 H2O.ai,并新增了导入/导出和窗口函数测试
• 使用 Python 客户端,而不是 R 语言
• 所有测试的数据规模均为 5GB,分组和连接操作的规模额外测试了 50GB
• 报告结果为 3 次运行的中位数
• 测试环境为搭载 16GB RAM 的 MacBook Pro M1
• 测试的 DuckDB 版本范围为 0.2.7 至 1.0.0
• 时间跨度接近三年,从 2021 年 6 月 14 日至 2024 年 6 月 3 日
• 所有测试均使用默认设置
• 使用 Pandas 0.5.1 之前的版本和 Apache Arrow 0.5.1+
总体基准测试结果
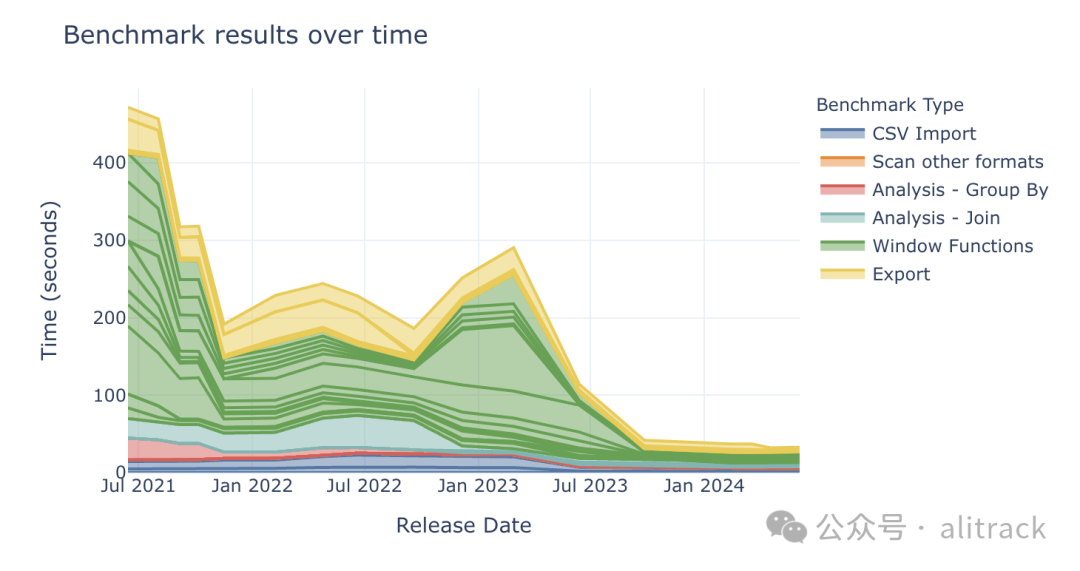
最新的 DuckDB 能够在 35 秒内完成一次完整的基准测试,而 0.2.7 版本在 2021 年 6 月需要将近 500 秒才能完成相同的任务。 这意味着 DuckDB 的性能在短短三年内提升了 14 倍!
性能变化趋势
注意:得益于 Plotly.js[7],这些图表是交互式的! 您可以自由地过滤不同的数据序列(单击隐藏,双击仅显示该序列),并通过单击拖动来放大图表。 将鼠标悬停在每个基准测试结果上可以查看详细信息。
上图展示了所有测试的中位运行时间(单位:秒)。由于窗口函数的用途广泛且算法相对复杂,因此 16 个窗口函数测试在所有测试类别中耗时最长。
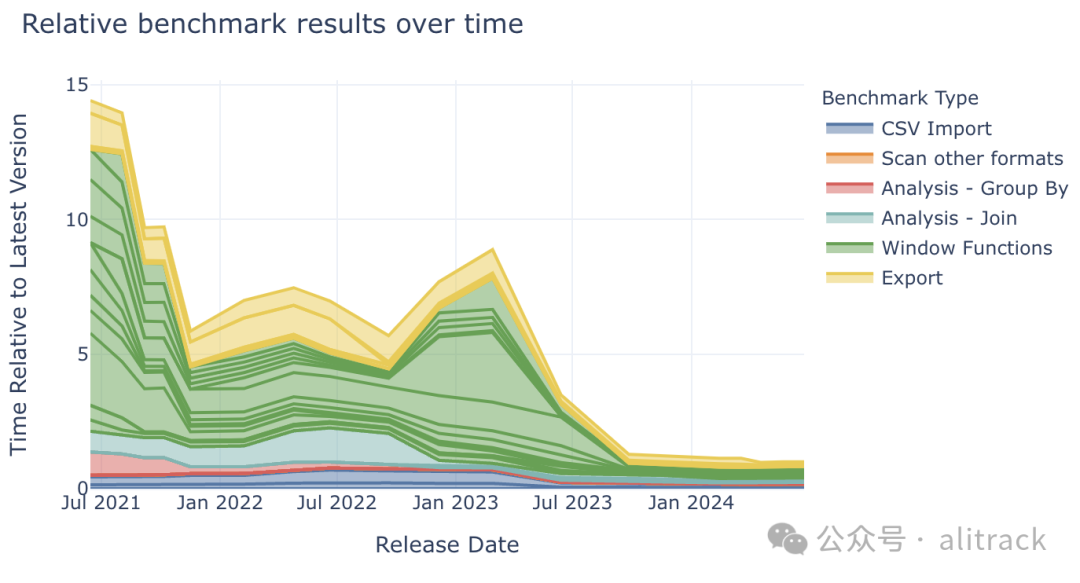
该图将 DuckDB 各个版本的性能标准化到最新版本,以便更直观地展示性能的相对提升。通过查看您上次测试 DuckDB 性能的时间点,您可以清楚地了解 DuckDB 现在的速度提升了多少倍!
DuckDB 性能提升的部分原因在于引入了多线程功能,该功能在 2021 年 11 月发布的 0.3.1 版本中成为默认功能。此外,DuckDB 在该版本中还采用了基于推送的执行模型,进一步提升了性能。在 2022 年 12 月发布的 0.6.1 版本中,并行数据加载和核心 JOIN
算法的改进也带来了显著的性能提升。我们将在后文中详细讨论 DuckDB 的其他改进。
值得注意的是,DuckDB 的改进并不仅仅局限于原始查询性能,而是体现在系统的各个方面。DuckDB 致力于优化整个数据分析工作流程,而不仅仅是聚合或连接操作的性能。CSV 解析、数据导入和导出以及窗口函数的性能都得到了显著提升,其中窗口函数的改进最为突出。
那么,从 2022 年 12 月到 2023 年 6 月,性能略微下降的原因是什么?这是因为窗口函数在新增功能的同时,性能略有下降。但是,从 2023 年 6 月开始,窗口函数的整体性能得到了大幅提升。如果在图表中剔除窗口函数数据,性能变化趋势将更加平滑。
您可能还注意到,从 2023 年 9 月发布的 0.9 版本开始,DuckDB 的性能似乎趋于稳定。这是怎么回事呢?首先,请不要忘记放大图表!在过去的一年中,DuckDB 的性能仍然提升了三倍多!最近,DuckDB Labs 团队专注于提升系统的可扩展性,开发了支持大于内存计算的算法。我们将在稍后的规模测试部分中展示这些努力的成果!此外,DuckDB 在 0.10.1、0.10.2 和 0.10.3 版本中专注于修复错误,为发布更加强大的 DuckDB 1.0 版本做好准备。现在,这两个重要的里程碑(大于内存计算和 DuckDB 1.0)已经实现,DuckDB 的性能将继续提升!值得一提的是,多线程带来的性能提升只有一次,但 DuckDB 仍然有许多其他优化空间。
不同版本的性能表现
我们还可以按照版本号而不是时间顺序来展示 DuckDB 的整体性能变化趋势。从图中可以看出,DuckDB 近期发布新版本的频率越来越高。有关 DuckDB 完整的版本历史记录,请参阅 DuckDB 版本发布日历[8]。

如果您还记得上次测试的 DuckDB 版本,您可以通过本文了解 1.0 版本的性能提升了多少!
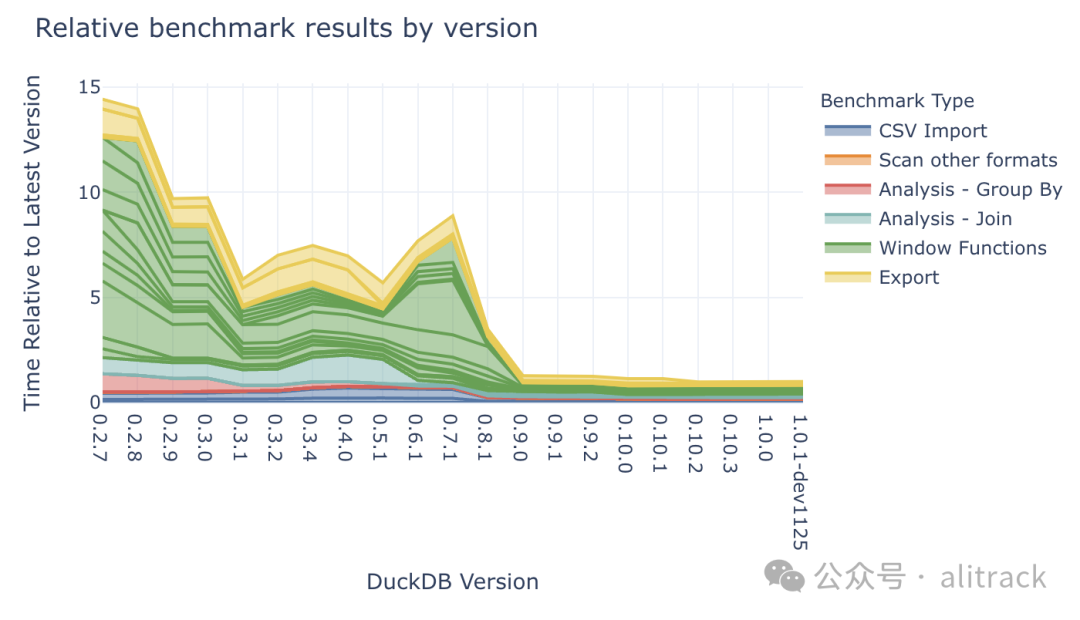
各类工作负载的测试结果
CSV 读取器性能
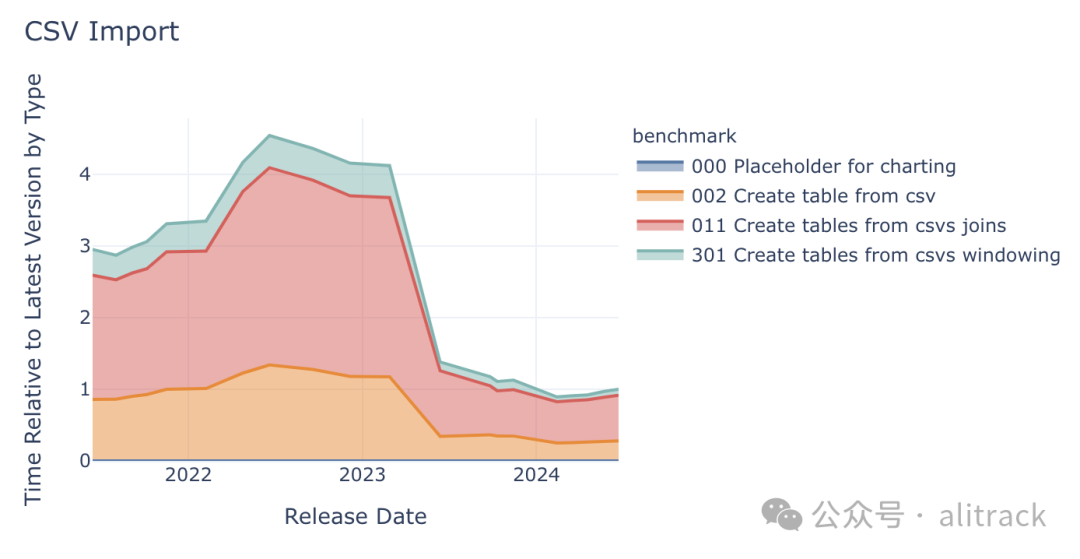
DuckDB 投入了大量精力来构建一个[快速且强大的 CSV 解析器]({% post_url 2023-10-27-csv-sniffer %})。CSV 解析通常是数据分析工作流程的第一步,但它往往被低估,基准测试也不足。DuckDB 将 CSV 读取器的性能提高了近三倍,并增加了自动识别和处理更多 CSV 方言的能力。
Group By (分组)性能
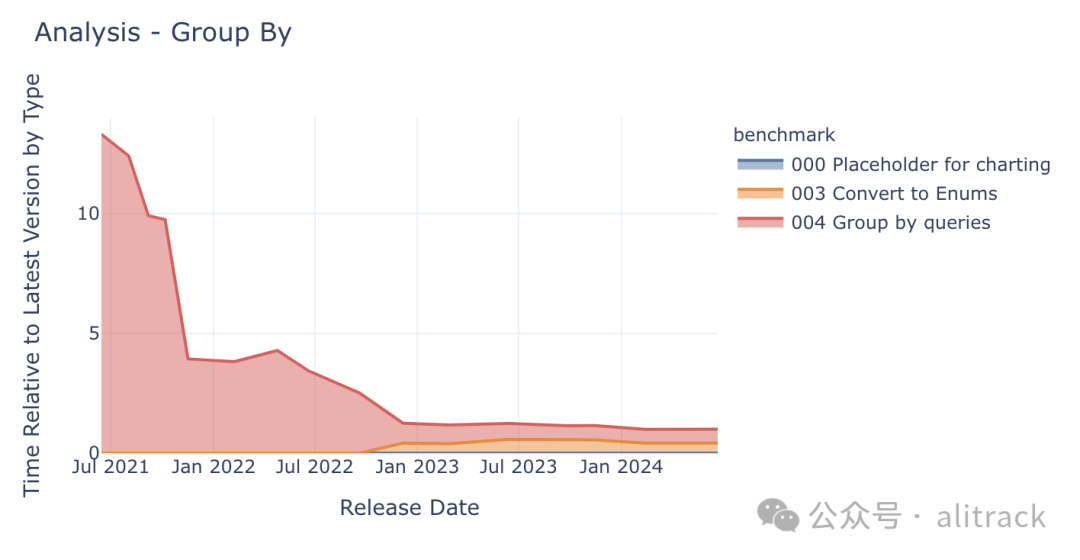
分组或聚合操作是 OLAP 工作负载中的关键步骤,因此 DuckDB 一直非常重视这方面的优化,并在过去三年中将分组操作的性能提升了 12 倍以上。
2021 年 11 月发布的 0.3.1 版本默认启用了多线程聚合功能,显著提高了分组操作的速度。
2022 年 12 月发布的 0.6.1 版本实现了数据加载的并行化,这再次体现了 DuckDB 对优化整个数据工作流程的关注,因为这个分组基准测试实际上对插入性能提出了很高的要求。插入结果的操作占用了大部分时间!
此外,0.6.1 版本还使用枚举类型(ENUM)代替字符串来存储分类列,这意味着 DuckDB 可以在处理这些列时使用整数而不是字符串,从而进一步提升性能。
尽管从图表上看,分组操作的性能似乎在后期趋于稳定,但如果放大 2023 年和 2024 年的数据,就会发现性能提升了约 20%。此外,在最近的几个版本中,DuckDB 还对聚合操作进行了大量的优化,以支持大于内存的聚合。这意味着在保持对小于内存数据的高性能处理的同时,DuckDB 也能够处理更大规模的数据集。
Join (连接)性能
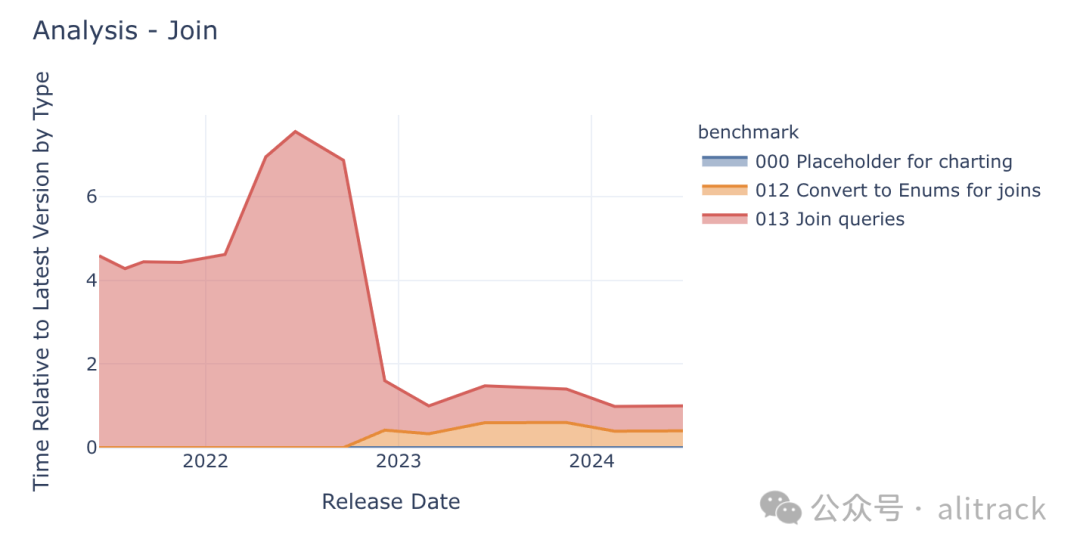
连接操作是分析型数据库(尤其是 DuckDB)的另一个重点优化领域。在过去三年中,DuckDB 的连接速度提升了四倍!
2022 年 12 月发布的 0.6.1 版本改进了核心外哈希连接算法,这不仅提升了处理大于内存数据的性能,也提高了处理小于内存数据的效率。此外,0.6.1 版本中并行数据加载功能的引入也有助于提升连接操作的性能,因为某些连接操作的结果集大小与输入表相当。
在最近的几个版本中,DuckDB 还对连接操作进行了升级,以支持大于内存的连接。这项改进不仅提升了 DuckDB 处理大于内存数据的性能,也惠及了处理小于内存数据的效率,并在 2024 年 2 月发布的 0.10 版本中得到了体现。
Window(窗口)函数性能
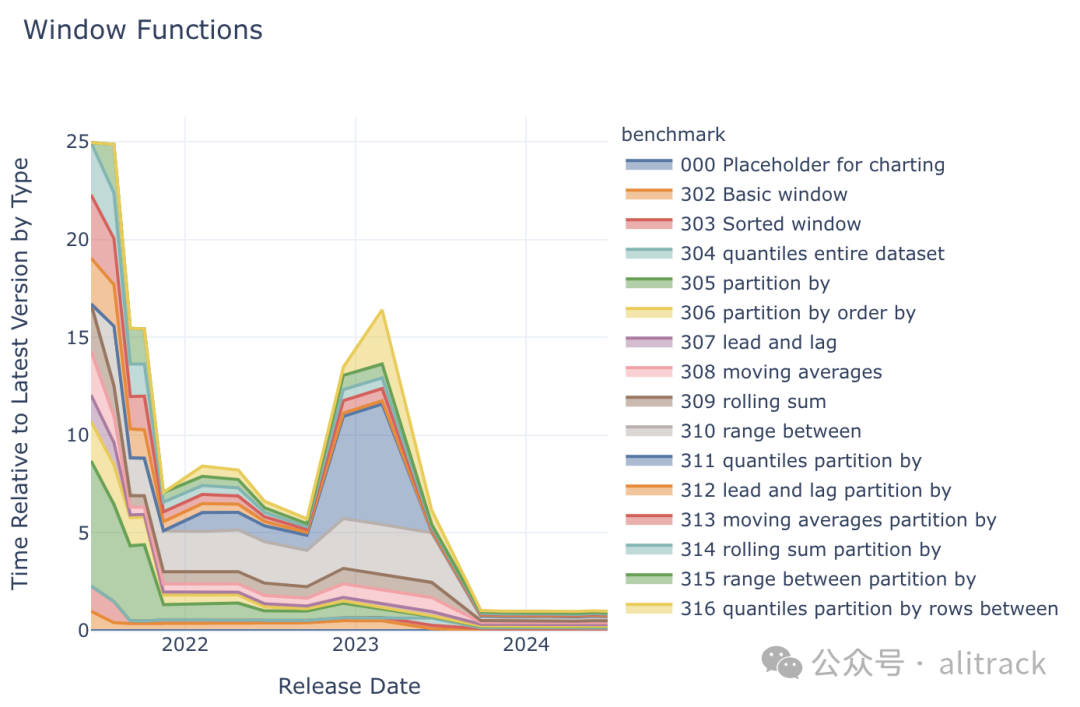
在过去三年中,DuckDB 的窗口函数性能提升了惊人的 25 倍!
2023 年 9 月发布的 0.9.0 版本对窗口函数的性能进行了大幅优化,共计实施了 14 项性能改进[9]。聚合计算实现了矢量化(特别是在 线段树数据结构[10] 方面进行了优化),工作窃取技术实现了多线程处理,排序操作也支持并行执行。此外,DuckDB 还优化了内存分配策略,以更大的批次预先分配内存。
DuckDB 的窗口函数还能够处理大于内存的数据集。我们将在未来的工作中对这项功能进行更深入的基准测试!
数据导出性能
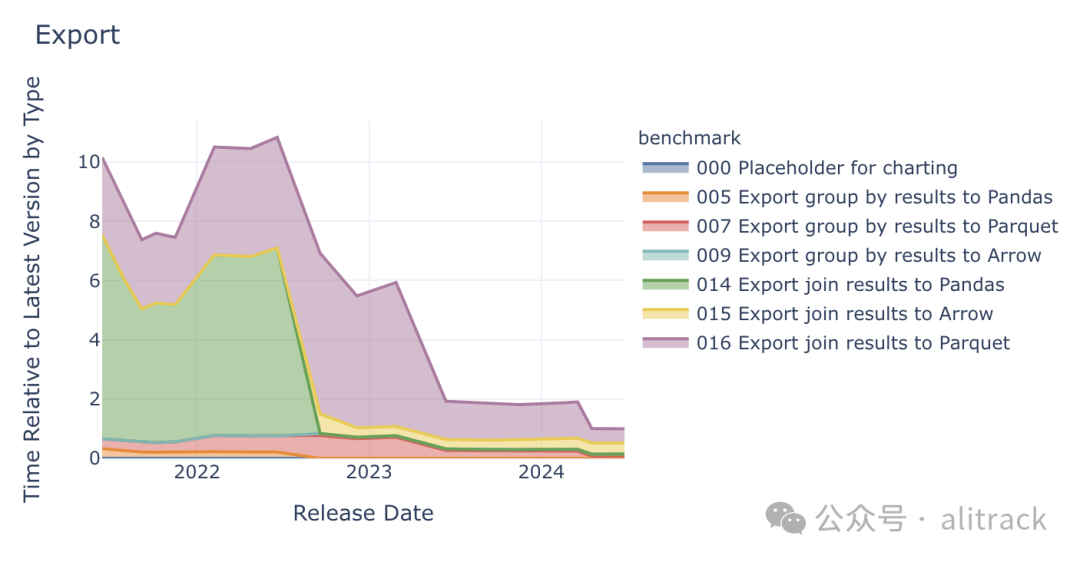
在许多情况下,DuckDB 并不是数据处理流程的最后一步,因此数据导出性能至关重要。DuckDB 的数据导出速度提升了 10 倍! 直到最近,DuckDB 的数据格式还不支持向后兼容,因此推荐的长期数据存储格式是 Parquet。Parquet 格式对于与其他系统(尤其是数据湖)的互操作性也至关重要。DuckDB 非常适合作为数据工作流引擎,因此将数据导出到其他内存数据格式也是一种常见的应用场景。
在 2022 年 9 月发布的 0.5.1 版本中,DuckDB 的数据导出性能得到了显著提升,这主要得益于将默认的内存导出格式从 Pandas 切换到了 Apache Arrow。DuckDB 的底层数据类型与 Arrow 非常相似,因此数据传输速度非常快。
在整个基准测试过程中,Parquet 的导出性能提升了 4-5 倍,其中 0.8.1 版本(2023 年 6 月)和 0.10.2 版本(2024 年 4 月)的改进最为显著。0.8.1 版本引入了 Parquet 并行写入[11] 功能,同时保留了数据的插入顺序。
0.10.2 版本的改进则更加细微。在导出具有高基数的字符串列时,DuckDB 会根据字典编码是否能够有效减小文件大小来决定是否使用字典压缩。从 0.10.2 版本开始,DuckDB 会在将一部分值插入字典后就测试压缩率[12],而不是在所有值都添加到字典之后才进行测试。这避免了对高基数列进行不必要的字典压缩操作,因为对于这类列,字典压缩通常不会带来明显的效率提升。
Apache Arrow、Pandas 和 Parquet 的导出性能比较
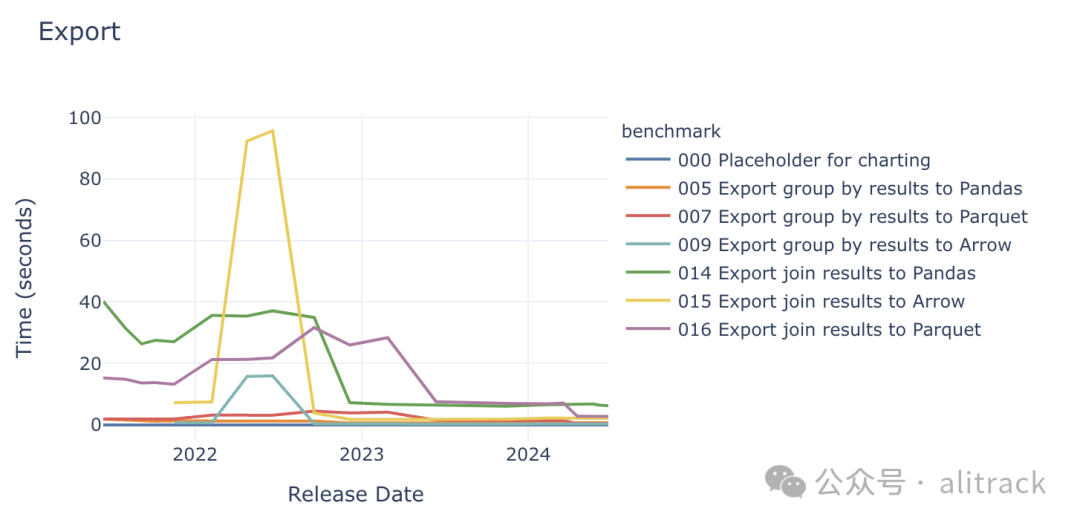
该图展示了三种数据格式在整个测试周期内的导出性能变化趋势(而不是仅仅比较 Pandas 和 Arrow)。通过该图,我们可以清晰地看到 Apache Arrow 的性能何时超越 Pandas。
在整个基准测试过程中,Pandas 的导出性能有了显著提高。然而,Apache Arrow 是一种效率更高的数据格式,因此目前 DuckDB 首选 Arrow 作为内存导出格式。有趣的是,DuckDB 的 Parquet 导出功能现在非常高效,以至于将数据写入持久化的 Parquet 文件比写入内存中的 Pandas 数据帧还要快!Parquet 的导出性能甚至可以与 Apache Arrow 媲美。
扫描其他数据格式的性能
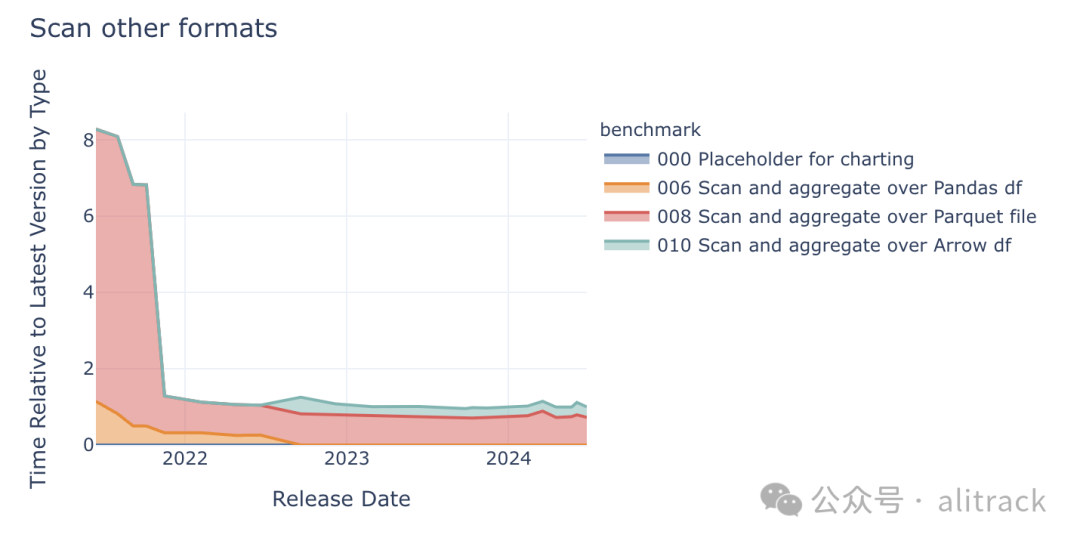
在某些应用场景中,DuckDB 不需要将原始数据存储在数据库中,而只需要读取和分析数据。这使得 DuckDB 可以无缝地集成到其他数据处理流程中。该基准测试用于评估 DuckDB 扫描和聚合不同数据格式的速度。
为了便于比较不同版本之间的性能差异,我们如前所述,在 0.5.1 版本中将默认的内存数据格式从 Pandas 切换到了 Arrow。DuckDB 在此类工作负载中的速度提升了八倍以上,而且完成这些操作所需的绝对时间非常短。DuckDB 非常适合处理此类任务!
Apache Arrow、Pandas 和 Parquet 的扫描性能比较
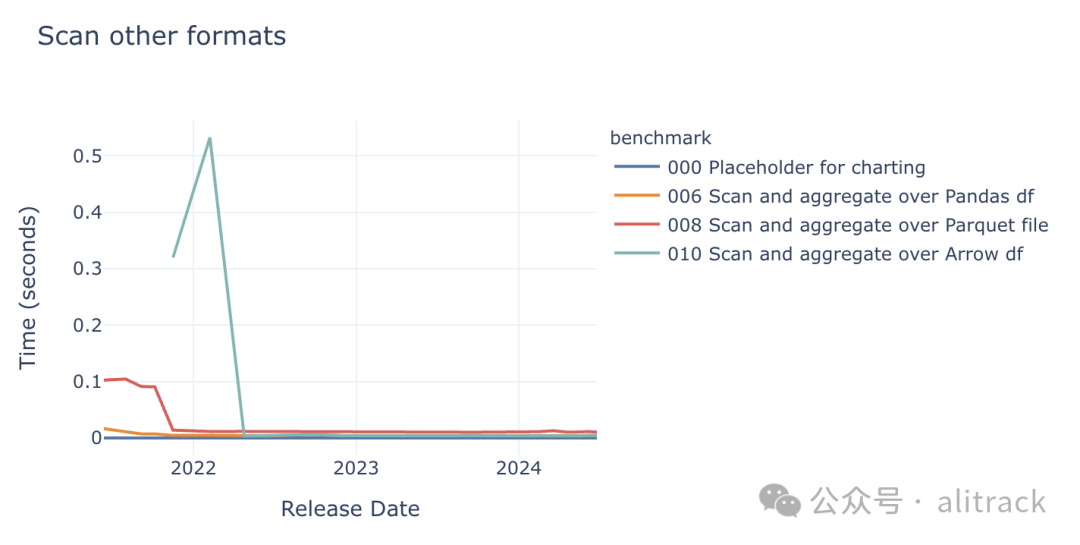
我们再次对三种数据格式在整个测试周期内的扫描性能进行了比较。
在扫描数据时,Apache Arrow 和 Pandas 的性能较为接近。因此,尽管 Arrow 在数据导出方面表现更出色,但 DuckDB 仍然能够以相当的速度读取 Pandas 数据。然而,由于 Arrow 和 Pandas 数据都存储在内存中,因此它们的扫描速度比 Parquet 快 2-3 倍。不过,从绝对时间上看,完成这些操作所需的时间在整个基准测试中只占很小的比例,因此其他操作才是影响 DuckDB 整体性能的决定性因素。
规模测试
分析大于内存的数据是 DuckDB 的一项强大功能,它使得 DuckDB 能够处理比以往更大规模的数据分析任务。
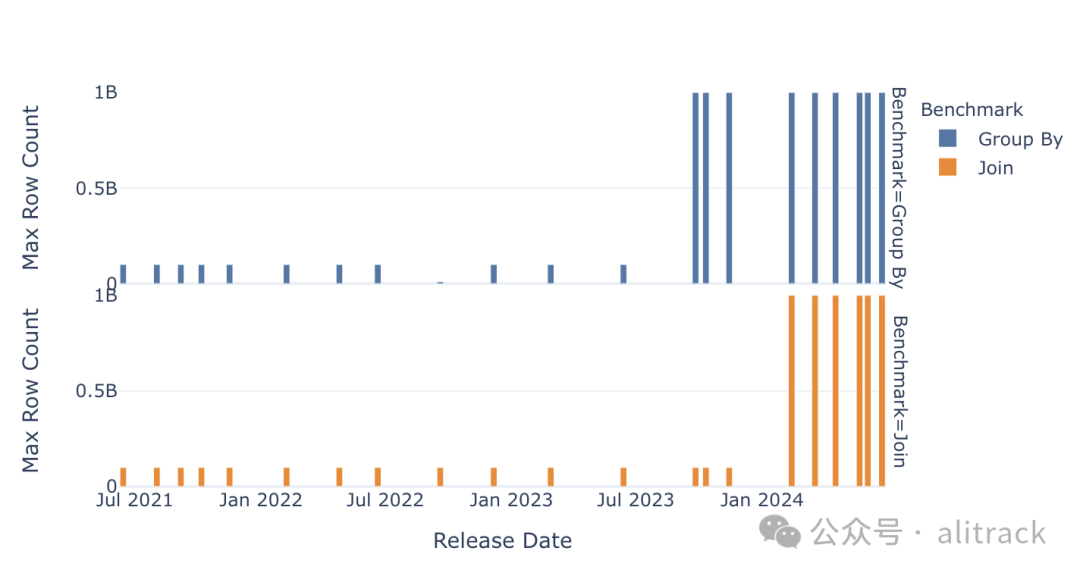
在 2023 年 9 月发布的 0.9.0 版本中,DuckDB 对哈希聚合操作进行了增强,以支持处理核心外(大于内存)的中间结果[13]。有关该算法的详细信息和一些基准测试结果,请参阅 这篇博客文章。这项改进使得 DuckDB 能够在仅有 16GB RAM 的 MacBook Pro 上聚合 10 亿行数据(大小为 50GB),即使分组依据中包含大量的唯一组。这意味着 DuckDB 的聚合处理能力在三年内提升了至少 10 倍。
自 2022 年 12 月发布的 0.6.1 版本以来,DuckDB 的哈希连接运算符已经支持大于内存的连接操作。然而,受限于基准测试的数据规模和测试硬件的内存容量(16GB RAM),旧版本的 DuckDB 仍然无法完成这项基准测试。在 2024 年 2 月发布的 0.10.0 版本中,DuckDB 对内存管理系统进行了重大升级[14],以支持多个需要大量内存的并发操作。0.10.0 版本的博客文章[15] 对此功能进行了更详细的介绍。
得益于这些改进,DuckDB 0.10.0 版本能够处理远大于内存的数据计算任务,即使中间计算结果也非常庞大。DuckDB 支持所有常见的数据操作运算符,包括排序、聚合、连接和窗口函数。在未来的工作中,我们将继续探索 DuckDB 核心外计算的性能极限,包括测试窗口函数的性能以及处理更大规模的数据集。
硬件性能的演进
DuckDB 在相同硬件上的性能得到了显著提升,与此同时,硬件性能也在快速发展。
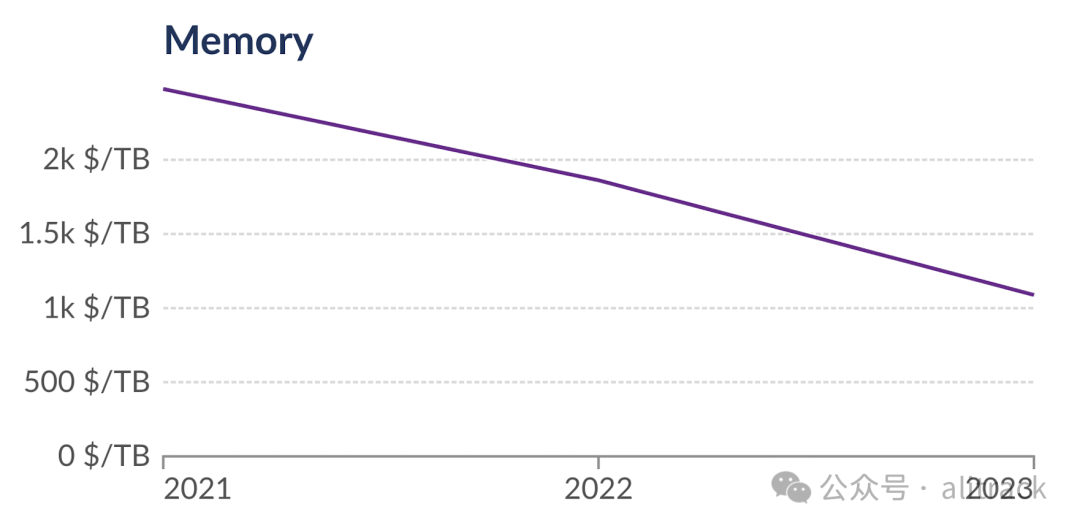
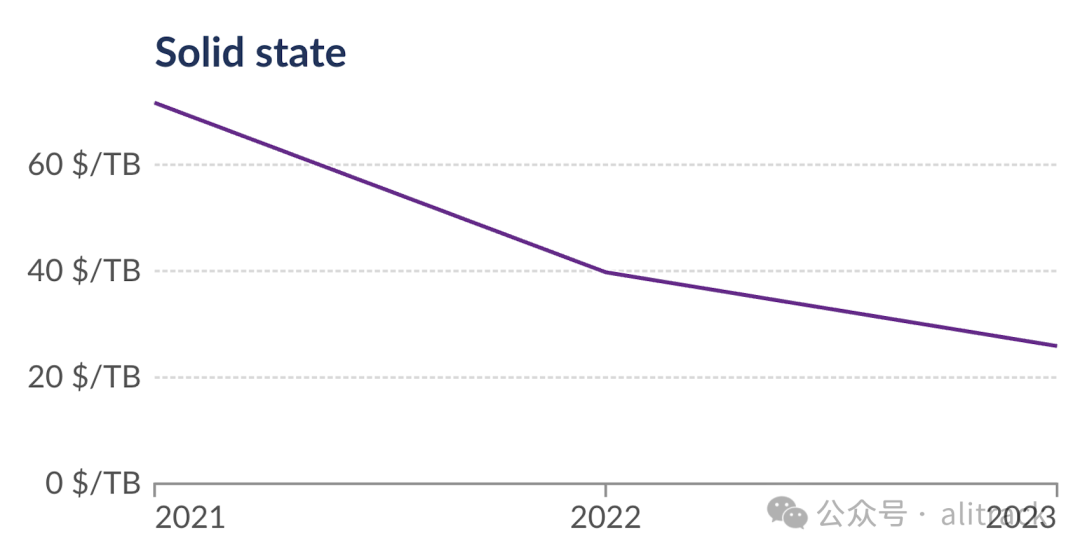
数据来源:Our World in Data[16]
从 2021 年到 2023 年,RAM 的价格下降了 2.2 倍,SSD 存储器的价格下降了 2.7 倍。得益于 DuckDB 的性能提升和硬件价格的下降,在短短三年内,单台计算机能够处理的数据分析规模已经提升了数十倍!
分析基准测试结果
我们提供了一个包含所有基准测试结果的 DuckDB 1.0 数据库文件,您可以从 duckdb_perf_over_time.duckdb[17] 下载。任何支持 httpfs
扩展的 DuckDB 客户端都可以读取该文件。
您甚至可以使用 DuckDB Wasm Web shell **直接在浏览器中查询该文件[18]**(预先填充了查询语句并自动执行):
LOAD httpfs;
ATTACH 'https://blobs.duckdb.org/data/duckdb_perf_over_time.duckdb' AS performance_results;
USE performance_results;
该文件包含两个表:benchmark_results
和 scale_benchmark_results
。欢迎您下载并分析这些数据,如果您有任何有趣的发现,请与我们分享!
总结
总而言之,DuckDB 不仅功能越来越丰富,而且速度也越来越快!在短短三年内,DuckDB 的整体性能提升了 14 倍!
然而,查询性能只是 DuckDB 优势的一部分。DuckDB 支持功能齐全的 SQL 方言(包括高性能窗口函数),能够处理各种类型的工作负载,并且应用范围还在不断扩大。此外,数据导入、CSV 解析和数据导出等关键工作负载的性能也得到了显著提升。DuckDB 致力于为开发者提供最佳的数据处理体验!
最后,DuckDB 现在支持所有运算符的外部计算(即处理大于内存的数据),包括排序、聚合、连接和窗口函数。这意味着您现在可以使用现有的计算资源处理比以前大 10 倍甚至更多 的数据集!
如果您已经读到这里,欢迎加入 DuckDB 社区!🦆 加入我们的 Discord 服务器[19],分享您的宝贵意见和建议!
附录
基准测试设计
H2O.ai 基准测试
本文使用 H2O.ai 基准测试来评估 DuckDB 在连接和分组查询方面的性能随时间的变化趋势。
每个 H2O.ai 查询的结果都会被写入一个持久化的 DuckDB 文件中。与完全在内存中执行查询相比,这种方式需要额外的 I/O 操作(特别是对 SSD 的读写压力),但它可以提高系统的可扩展性,并且是处理大型数据集的常用方法。
为了与 H2O.ai 基准测试保持一致,我们将所有分类类型的列(即基数较低的 VARCHAR 列)都转换成了 ENUM 类型。转换操作的耗时也被计入了基准测试结果中。结果表明,预先将字符串列转换成 ENUM 类型可以有效减少查询的总执行时间。然而,在 2022 年 12 月发布的 0.6.1 版本之前,DuckDB 并不完全支持 ENUM 数据类型,因此早期版本的 DuckDB 无法进行这种转换操作。
Python 客户端
为了评估 DuckDB 与其他数据格式的互操作性,我们在本次测试中选择了 Python 客户端,而不是 H2O.ai 默认使用的 R 语言客户端。不过,为了与 H2O.ai 基准测试保持一致,我们仍然使用 R 语言来生成测试数据。Python 是 DuckDB 最受欢迎的客户端语言,它在数据科学领域应用广泛,也是作者本人最喜欢的编程语言。
数据导出和替换扫描测试
我们在 H2O.ai 基准测试的基础上进行了一些扩展,新增了数据导入和导出测试,以评估 DuckDB 处理不同数据格式的性能,包括 Pandas、Apache Arrow 和 Apache Parquet。我们将连接和分组查询的结果分别导出为这三种格式。
在测试数据导出性能时,我们分别测量了将数据导出为 Pandas 和 Apache Arrow 两种格式的耗时。然而,在汇总最终的性能数据时,我们只选择了当时性能更好的数据格式。这模拟了注重性能的用户行为,因为他们通常不会将数据同时导出为两种格式。在 2022 年 9 月发布的 0.5.1 版本中,DuckDB 在写入和读取 Apache Arrow 格式数据时的性能超越了 Pandas。因此,在 0.2.7 至 0.4.0 版本的测试中,我们使用 Pandas 作为默认的内存数据格式,而在 0.5.1 及以后版本的测试中,我们则选择了 Apache Arrow。
在数据导入方面,我们测试了 DuckDB 在不进行数据导入操作的情况下直接读取不同数据格式的性能,这被称为“替换扫描”。在替换扫描测试中,我们使用 H2O.ai 分组基准测试的最终结果集作为输入数据。对于 5GB 数据规模的测试,该结果集包含 1000 万行数据。在测试过程中,我们只读取一列数据并计算一个聚合值,以便将测试重点放在数据扫描速度上,而不是 DuckDB 的聚合算法或结果输出速度上。我们使用的查询语句如下:
SELECT
sum(v3) AS v3
FROM ⟨数据帧或 Parquet 文件⟩
窗口函数测试
我们还新增了一系列窗口函数测试。窗口函数在实际数据分析场景中应用广泛,并且可以从不同方面对数据库系统进行压力测试。DuckDB 实现了先进的算法,能够快速处理各种复杂的窗口函数。在本次测试中,我们使用连接基准测试中最大的表作为输入数据,并将其数据规模设置为 5GB,以便与其他测试结果进行比较。
与连接和分组操作相比,针对窗口函数的基准测试案例要少得多,我们也无法找到现成的测试套件。因此,我们自行设计了一些测试用例,以涵盖窗口函数的各种应用场景,但这些用例肯定无法覆盖所有情况。如果您有任何建议,欢迎随时提出。我们希望这些测试用例能够为其他数据库系统的性能评估提供参考。
由于窗口函数测试是本次新增的测试项目,因此我们将在本文的附录部分详细列出每个测试用例中使用的窗口函数。
数据规模
在上述测试中,我们只使用了中等规模的测试数据(5GB),主要是因为某些数据导入和导出操作(例如将数据导出为 Pandas 数据帧)需要将所有数据加载到内存中,而我们的测试环境只有一台搭载 16GB RAM 的 MacBook Pro M1。此外,由于早期版本的 DuckDB 性能较低,即使使用中等规模的测试数据,对 21 个 DuckDB 版本进行测试也需要耗费大量时间。
规模测试
只使用 5GB 的测试数据无法回答我们的第二个关键问题:“DuckDB 可以处理什么规模的数据?” 因此,我们还对分组和连接操作进行了更大规模的测试,分别使用 5GB 和 50GB 的数据进行测试(为了避免内存不足的问题,我们没有测试数据导入和导出操作)。在测试过程中,我们发现早期版本的 DuckDB 无法处理 50GB 的数据,而最新版本的 DuckDB 即使在内存受限的笔记本电脑上也能顺利完成测试。在规模测试中,我们关注的不是 DuckDB 的执行速度,而是它能够处理的最大数据量。
性能指标
除规模测试外,所有基准测试都运行了三次,我们使用三次运行结果的中位数作为最终的性能指标。规模测试只运行一次,我们使用“成功”或“失败”来表示 DuckDB 是否能够处理指定规模的数据集。由于早期版本的 DuckDB 在处理大型数据集时可能会出现崩溃等问题,因此我们通过多次运行测试来确定 DuckDB 能够处理的最大数据量。
测试环境
所有测试都在一台搭载 16GB RAM 的 MacBook Pro M1 上进行。在 2024 年,这并不是一台性能出色的计算机。如果您使用性能更强大的硬件,DuckDB 的性能和可扩展性将会得到进一步提升。
DuckDB 版本
我们测试的 DuckDB 版本范围从 0.2.7 到 1.0.0。0.2.7 版本发布于 2021 年 6 月,它是第一个包含 ARM64 架构 Python 客户端的版本,因此我们可以在测试环境中轻松运行该版本。1.0.0 版本是截至本文撰写时(2024 年 6 月)可用的最新版本,我们还提供了一个正在开发的功能分支的预览版本。
默认设置
所有测试都使用 DuckDB 的默认设置。因此,只有当新功能成为默认设置后,我们才能在基准测试中观察到其带来的性能提升。
窗口函数基准测试
每个窗口函数测试用例都使用以下查询语句模板,只是 ⟨窗口函数⟩
占位符的内容不同。在测试中,我们使用连接基准测试中最大的表作为输入数据,并将其数据规模设置为 5GB。
DROP TABLE IF EXISTS windowing_results;
CREATE TABLE windowing_results AS
SELECT
id1,
id2,
id3,
v2,
⟨窗口函数⟩
FROM join_benchmark_largest_table;
以下是用于替换 ⟨窗口函数⟩
占位符的具体窗口函数,每个函数都标注了其对应的测试用例编号。我们选择这些窗口函数是为了涵盖尽可能多的应用场景,并测试 DuckDB 窗口函数实现的各个方面。有关 DuckDB 窗口函数语法的详细说明,请参阅 DuckDB 官方文档[20]。如果您发现 DuckDB 的窗口函数测试用例中缺少某些常见的应用场景,请随时向我们反馈!
/* 302 基本窗口函数 */
sum(v2)OVER()AS window_basic
/* 303 排序窗口函数 */
first(v2)OVER(ORDERBY id3)AS first_order_by,
row_number()OVER(ORDERBY id3)AS row_number_order_by
/* 304 计算整个数据集的分位数 */
quantile_cont(v2,[0,0.25,0.50,0.75,1])OVER()
AS quantile_entire_dataset
/* 305 按 id1、id2 和 id3 分组 */
sum(v2)OVER(PARTITIONBY id1)AS sum_by_id1,
sum(v2)OVER(PARTITIONBY id2)AS sum_by_id2,
sum(v2)OVER(PARTITIONBY id3)AS sum_by_id3
/* 306 按 id2 分组并按 id3 排序 */
first(v2)OVER
(PARTITIONBY id2 ORDERBY id3)AS first_by_id2_ordered_by_id3
/* 307 前导和滞后函数 */
first(v2)OVER
(ORDERBY id3 ROWSBETWEEN1 PRECEDING AND1 PRECEDING)
AS my_lag,
first(v2)OVER
(ORDERBY id3 ROWSBETWEEN1 FOLLOWING AND1 FOLLOWING)
AS my_lead
/* 308 移动平均线 */
avg(v2)OVER
(ORDERBY id3 ROWSBETWEEN100 PRECEDING ANDCURRENTROW)
AS my_moving_average,
avg(v2)OVER
(ORDERBY id3 ROWSBETWEEN id1 PRECEDING ANDCURRENTROW)
AS my_dynamic_moving_average
/* 309 滚动求和 */
sum(v2)OVER
(ORDERBY id3 ROWSBETWEEN UNBOUNDED PRECEDING ANDCURRENTROW)
AS my_rolling_sum
/* 310 RANGE BETWEEN */
sum(v2)OVER
(ORDERBY v2 RANGEBETWEEN3 PRECEDING ANDCURRENTROW)
AS my_range_between,
sum(v2)OVER
(ORDERBY v2 RANGEBETWEEN id1 PRECEDING ANDCURRENTROW)
AS my_dynamic_range_between
/* 311 按 id2 分组计算分位数 */
quantile_cont(v2,[0,0.25,0.50,0.75,1])
OVER(PARTITIONBY id2)
AS my_quantiles_by_id2
/* 312 按 id2 分组并按 id3 排序,计算前导和滞后值 */
first(v2)OVER
(PARTITIONBY id2 ORDERBY id3 ROWSBETWEEN1 PRECEDING AND1 PRECEDING)
AS my_lag_by_id2,
first(v2)OVER
(PARTITIONBY id2 ORDERBY id3 ROWSBETWEEN1 FOLLOWING AND1 FOLLOWING)
AS my_lead_by_id2
/* 313 按 id2 分组并按 id3 排序,计算移动平均线 */
avg(v2)OVER
(PARTITIONBY id2 ORDERBY id3 ROWSBETWEEN100 PRECEDING ANDCURRENTROW)
AS my_moving_average_by_id2,
avg(v2)OVER
(PARTITIONBY id2 ORDERBY id3 ROWSBETWEEN id1 PRECEDING ANDCURRENTROW)
AS my_dynamic_moving_average_by_id2
/* 314 按 id2 分组并按 id3 排序,计算滚动求和 */
sum(v2)OVER
(PARTITIONBY id2 ORDERBY id3 ROWSBETWEEN UNBOUNDED PRECEDING ANDCURRENTROW)
AS my_rolling_sum_by_id2
/* 315 按 id2 分组并按 v2 排序,使用 RANGE BETWEEN 计算滚动求和 */
sum(v2)OVER
(PARTITIONBY id2 ORDERBY v2 RANGEBETWEEN3 PRECEDING ANDCURRENTROW)
AS my_range_between_by_id2,
sum(v2)OVER
(PARTITIONBY id2 ORDERBY v2 RANGEBETWEEN id1 PRECEDING ANDCURRENTROW)
AS my_dynamic_range_between_by_id2
/* 316 按 id2 分组并按 id3 排序,使用 ROWS BETWEEN 计算分位数 */
quantile_cont(v2,[0,0.25,0.50,0.75,1])OVER
(PARTITIONBY id2 ORDERBY id3 ROWSBETWEEN100 PRECEDING ANDCURRENTROW)
AS my_quantiles_by_id2_rows_between
引用链接
[1]
Benchmarking Ourselves over Time at DuckDB: https://duckdb.org/2024/06/26/benchmarks-over-time.html[2]
duckdb_fdw: https://github.com/alitrack/duckdb_fdw[3]
并非易事: https://mytherin.github.io/papers/2018-dbtest.pdf[4]
H2O.ai 基准测试: https://duckdblabs.github.io/db-benchmark/[5]
博客文章: https://duckdb.org/2023/04/14/h2oai.html[6]
文章: https://duckdb.org/2023/11/03/db-benchmark-update.html[7]
Plotly.js: https://plotly.com/javascript/[8]
DuckDB 版本发布日历: https://duckdb.org/docs/dev/release_calendar.html[9]
共计实施了 14 项性能改进: https://github.com/duckdb/duckdb/issues/7809#issuecomment-1679387022[10]
线段树数据结构: https://www.vldb.org/pvldb/vol8/p1058-leis.pdf[11]
Parquet 并行写入: https://github.com/duckdb/duckdb/pull/7375[12]
会在将一部分值插入字典后就测试压缩率: https://github.com/duckdb/duckdb/pull/11461[13]
对哈希聚合操作进行了增强,以支持处理核心外(大于内存)的中间结果: https://github.com/duckdb/duckdb/pull/7931[14]
对内存管理系统进行了重大升级: https://github.com/duckdb/duckdb/pull/10147[15]
0.10.0 版本的博客文章: https://duckdb.org/2024/02/13/announcing-duckdb-0100.html#temporary-memory-manager[16]
Our World in Data: https://ourworldindata.org/grapher/historical-cost-of-computer-memory-and-storage?yScale=linear&time=2021..latest&facet=metric&uniformYAxis=0[17]
duckdb_perf_over_time.duckdb: https://blobs.duckdb.org/data/duckdb_perf_over_time.duckdb[18]
https://shell.duckdb.org/#queries=v0,ATTACH-'https%3A%2F%2Fblobs.duckdb.org%2Fdata%2Fduckdb_perf_over_time.duckdb'-AS-performance_results~,FROM-performance_results.benchmark_results-SELECT-%22DuckDB-Version%22%2C-sum(%22Time-(seconds)%22)%3A%3ADECIMAL(15%2C2)-as-sum_time-GROUP-BY-%22DuckDB-Version%22-ORDER-BY-any_value(%22Release-Date%22)~: https://shell.duckdb.org/#queries=v0,ATTACH-%27https%3A%2F%2Fblobs.duckdb.org%2Fdata%2Fduckdb_perf_over_time.duckdb%27-AS-performance_results~,FROM-performance_results.benchmark_results-SELECT-%22DuckDB-Version%22%2C-sum%28%22Time-%28seconds%29%22%29%3A%3ADECIMAL%2815%2C2%29-as-sum_time-GROUP-BY-%22DuckDB-Version%22-ORDER-BY-any_value%28%22Release-Date%22%29~[19]
加入我们的 Discord 服务器: https://discord.duckdb.org/[20]
DuckDB 官方文档: https://duckdb.org/docs/sql/window_functions.html#syntax
