




DuckDB 处理 450GB 数据实战初体验
作者:João Pedro 原文: My First Billion (of Rows) in DuckDB[1]

引言
人工智能、数据科学和数据工程领域正在飞速发展。每天都有新的工具、新的范式和新的架构涌现,试图解决前人留下的难题。在众多新机遇中,了解如何利用现有工具高效解决问题显得尤为重要。我所说的不仅仅是技术细节,还包括实践中获得的经验,例如使用场景、优缺点、挑战和机遇。
本文将分享我使用 DuckDB 的初体验,并回顾我之前遇到的一个难题——如何处理巴西电子投票箱的日志数据以计算投票时间指标。DuckDB 是一种新兴数据库,可以在个人电脑上本地处理海量数据。正如你将在本文中看到的,这是一个极具挑战性的问题,可以很好地评估数据库的性能和用户体验。
我希望这篇文章能够帮助想要了解更多 DuckDB 信息的人,因为我将涵盖技术方面(例如如何运行程序和计算数据库性能)以及更“软性”的方面(例如编程体验和易用性)。
DuckDB 是一个开源项目,作者与 DuckDB/DuckDB Labs 没有任何关联。本文使用的数据遵循 ODbL[2] 许可。本项目完全免费,无需支付任何服务、数据访问或其他费用。
问题
问题在于如何处理来自电子投票箱日志的记录,以获取有关巴西选民投票时间的统计指标。例如,计算公民投票的平均时间、采集指纹进行身份验证的平均时间等等。这些指标应在多个粒度级别上进行汇总:国家、州、选举区和投票站。
你可能不知道,巴西拥有一个 100% 电子化的投票系统,所有 1 亿多公民在同一天投票,选举结果近乎实时地计算和公布。选票由分布在全国各地的数千个电子投票箱收集。

电子投票箱是一种用于选举的专用微型计算机,具有以下特点:耐用、体积小、重量轻、能源自主和安全性能强 [4[4]]。每个投票箱最多可容纳 500 名选民,之所以选择这个数字,是为了避免在投票站排起长队。
该系统由巴西高等选举法院 (TSE) 管理,TSE 在其开放数据门户[5] [ODbL] 上共享相关数据。日志是文本文件,其中包含投票箱中所有事件的完整列表。
这就是挑战所在。由于日志记录了每一个事件,因此可以从中计算出海量的指标;这是一个丰富的信息宝库。但正是这种丰富性,也使得它们极难处理,因为全国所有记录的总和高达 450GB,这些记录以 TSV 文件的形式存储,包含超过 40 亿行数据。
除了数据量之外,我认为这项工作成为一个良好基准的另一个原因是,为了达到最终目标所需的转换复杂程度各异,从简单的操作(例如 where、group by、order by)到复杂的 SQL 操作(例如窗口函数)都有。
DuckDB
面对如此庞大的数据量,人们可能倾向于使用传统的大数据工具,例如 Apache Spark,并在拥有众多工作节点、数百 GB 内存和数十个 CPU 的集群中处理这些数据。
而 DuckDB 的诞生就是为了挑战这种现状。
正如其创建者所言 ((参见此视频)[6]),它是一个旨在让单台机器也能处理海量数据的数据库。
也就是说,与其寻求复杂的行业解决方案(例如 PySpark)或基于云的解决方案(例如 Google BigQuery),不如使用具有标准 SQL 的本地进程内数据库来完成所需的转换。
简而言之,DuckDB 是一个进程内数据库(在程序中运行,没有独立的进程,类似于 SQLite)、OLAP(针对分析负载进行了优化),它可以处理传统格式的数据(例如 CSV、Parquet),并且针对使用单台机器(无需非常强大的配置)处理大量数据进行了优化。
数据
投票箱的日志是一个单独的 TSV 文件,文件名标准化——XXXXXYYYYZZZZ.csv,由投票箱的位置元数据组成,前 5 位数字是城市代码,接下来的 4 位是选举区(一个州的细分区域),最后 4 位是投票站(投票箱本身)。
巴西有近 500,000 个投票箱,因此有近 500,000 个文件。文件大小取决于该地区选民的数量,从 1 到 500 不等。日志内容如下所示:
| Timestamp | Level | Code | Source | Message |
| 2022-10-02 09:35:17 | INFO | 67305985 | VOTA | Voter was enabled |
| 2022-10-02 09:43:55 | INFO | 67305985 | VOTA | Vote confirmed for [Federal Deputy] |
| 2022-10-02 09:48:39 | INFO | 67305985 | VOTA | Vote confirmed for [State Deputy] |
| 2022-10-02 09:49:10 | INFO | 67305985 | VOTA | Vote confirmed for [Senator] |
| 2022-10-02 09:49:47 | INFO | 67305985 | VOTA | Vote confirmed for [Governor] |
| 2022-10-02 09:50:08 | INFO | 67305985 | VOTA | Vote confirmed for [President] |
| 2022-10-02 09:50:09 | INFO | 67305985 | VOTA | The voter’s vote was computed |
我们希望将这些原始信息转换为有关投票时间的统计指标(例如,每个选民投票需要多长时间?每分钟计算多少张选票?),并按照不同的粒度级别(国家、州、城市)进行汇总。为此,我们将创建一个类似于以下形式的 OLAP 多维数据集[7]:
| State | City | Mean Voting Time (seconds) | Max Votes Computed in 5 Min |
| Null | Null | 50 | 260 |
| São Paulo | São Paulo | 30 | 300 |
| São Paulo | Campinas | 35 | 260 |
| São Paulo | Null | 20 | 260 |
| Rio de Janeiro | Rio de Janeiro | 25 | 360 |
| Minas Gerais | Belo Horizonte | 40 | 180 |
| Bahia | Salvador | 28 | 320 |
| Rio Grande | Porto Alegre | 30 | 300 |
| … | … | … | … |
实现
环境搭建
要运行本项目,你只需要一个安装了 DuckDB 包[8] 的 Python 环境即可。
pip install duckdb
数据转换
在接下来的部分中,我将描述每个转换步骤的目标、DuckDB 如何执行每个步骤、优势、挑战、结果和结论。
数据处理过程分为 4 个步骤:
• 将 TSV 文件转换为 Parquet 格式;
• 过滤和清理数据;
• 隔离投票及其属性;
• 计算 OLAP 多维数据集的指标。
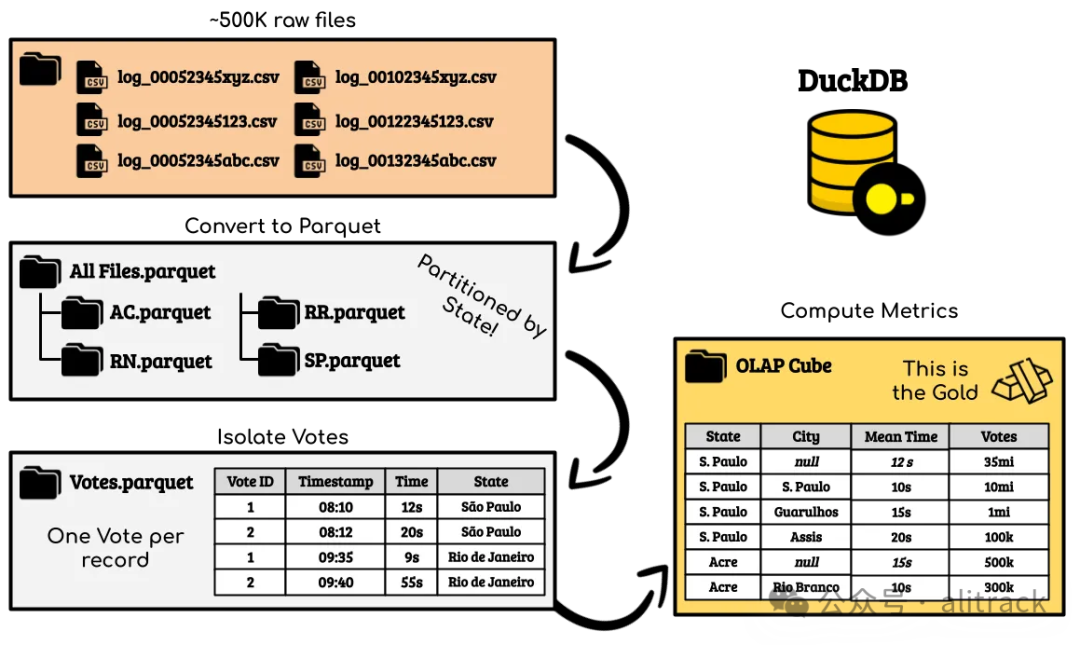
为了避免文章过长,我不会详细解释每个转换步骤的细节。你可以在 GitHub 存储库[9] 中找到所有代码。
将 TSV 文件转换为 Parquet 格式
对于任何想要处理大量数据的人来说,这是一个简单但必不可少的步骤。在 DuckDB 中完成这一步非常容易。
首先,创建一个 DuckDB 会话:
cursor = duckdb.connect("")
在本例中,我们使用空字符串实例化数据库连接器。这样做是为了指示 DuckDB 不要创建自己的数据库文件,而只是与系统文件进行交互。如前所述,DuckDB 是一个数据库,因此它具有创建表、视图等功能,但我们在这里不会深入探讨这些功能。我们将只关注将其用作数据转换引擎。
(💡,译者注,这步也可以省掉,直接使用duckdb.sql
或者duckdb.execute
即可。)
然后定义以下查询:
query = f"""
COPY (
SELECT
*
FROM read_csv('/data/logs/2_{state}/*.csv', filename=True)
) TO '{state}.parquet' (FORMAT 'parquet');
"""
cursor.execute(query)
就是这样!
让我们详细分析一下这个查询:
内部表达式只是一个标准的 SELECT * FROM table
查询,唯一的区别是 DuckDB 可以直接引用文件,而不是引用表。
该查询的结果可以导入到 Pandas DataFrame 中以进行进一步处理,如下所示:
my_df = cursor.execute(query).df()
这使得 DuckDB 和 Pandas 之间可以无缝集成。
外部表达式是一个简单的 COPY ... TO ...
语句,它将内部查询的结果写入文件。
在第一个转换步骤中,我们可以看到 DuckDB 的优势之一——能够使用普通的 SQL 语句与文件交互,而无需进行任何其他配置。上面的查询与我们在标准关系数据库管理系统(例如 PostgreSQL 和 MySQL)中执行的日常操作没有什么不同,唯一的区别是,我们操作的对象不是表,而是文件。
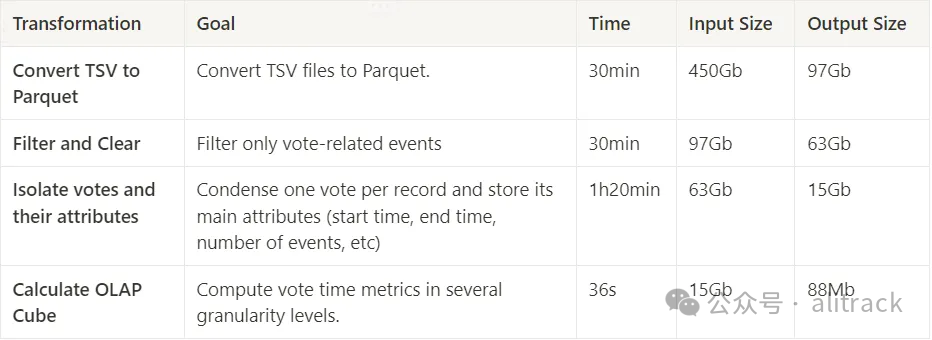
最初,我们有 450GB 的 TSV 文件,经过大约 30 分钟 的处理,我们最终得到了 97GB 的 Parquet 文件。
过滤和清理数据
如前所述,日志记录了投票箱发生的每个事件。此步骤旨在仅过滤与投票相关的事件,例如“选民投票给了总统”、“选民已采集指纹”和“选票已计算”,并且这些事件必须发生在选举日(这一点很重要,因为日志还记录了培训和其他管理操作)。
这是一个简单的查询,但涉及大量的文本和日期操作:
VOTES_DESCRIPTIONS = [
"event_description = 'Aguardando digitação do título'",
"event_description = 'Título digitado pelo mesário'",
"event_description = 'Eleitor foi habilitado'",
"event_description ILIKE 'Voto confirmado par%'",
"event_description = 'O voto do eleitor foi computado'",
]
ACCEPTED_DATES =[
'2022-10-02','2022-10-30',
'2022-10-03','2022-10-31',
]
query = f"""
SELECT
*
FROM (
SELECT
event_timestamp,
event_timestamp::date AS event_date,
event_type,
some_id,
event_system,
event_description,
event_id,
REPLACE(SPLIT_PART(filename, '/', 5), '_new.csv', '') AS filename,
-- 从文件名中提取元数据
SUBSTRING( SPLIT_PART(SPLIT_PART(filename, '/', 5), '-', 2), 1, 5 ) AS city_code,
SUBSTRING( SPLIT_PART(SPLIT_PART(filename, '/', 5), '-', 2), 6, 4 ) AS zone_code,
SUBSTRING( SPLIT_PART(SPLIT_PART(filename, '/', 5), '-', 2), 10, 4 ) AS section_code,
REPLACE(SPLIT_PART(filename, '/', 4), '2_', '') AS uf
FROM
{DATASET}
WHERE 1=1
AND ( {' OR '.join(VOTES_DESCRIPTIONS)} )
) _
WHERE 1=1
AND event_date IN ({', '.join([f"'{date}'" for date in ACCEPTED_DATES])})
"""
在这个查询中,我们可以看到 DuckDB 的另一个优势,即能够读写分区数据。表分区在处理大数据的环境中非常重要,但在单机模式下更为重要,因为我们对输入和输出使用的是同一个磁盘,也就是说,它的负担加倍了,因此任何优化都值得尝试。
最初,我们有 97GB 的数据,经过大约 30 分钟的处理后,我们只剩下 63GB 的 Parquet 文件。
隔离投票及其属性
由于每次投票都由多行数据组成,我们需要将所有信息压缩到一条记录中,以便于计算。这一步的操作比较复杂,因为查询变得更加复杂,而且 DuckDB 无法一次性处理所有数据。
为了解决这个问题,我编写了一个循环来分块增量处理数据:
for state in states:
for date in ACCEPTED_DATES:
for zone_group in ZONE_GROUPS:
query = f"""
COPY
{complex_query_goes_here
.replace('<uf>', state)
.replace('<event_date>', date)
.replace('<zone_id_min>', str(zone_group[0]))
.replace('<zone_id_max>', str(zone_group[1]))
}
TO 'VOTES.parquet'
(FORMAT 'parquet', PARTITION_BY (event_date, uf, zone_group), OVERWRITE_OR_IGNORE 1);
"""
具体的实现细节并不重要,重要的是我们不需要对代码进行太多修改就可以增量构建最终表。由于每个处理的“切片”都代表一个分区,因此通过将 OVERWRITE_OR_IGNORE
参数设置为 1,DuckDB 将自动覆盖该分区中的任何现有数据,如果该分区已存在,则忽略它。
最初,我们有 63GB 的数据,经过大约 1 小时 20 分钟的处理后,我们最终得到了 15GB 的 Parquet 文件。
计算指标并构建 OLAP 多维数据集
这是一个简单的步骤。现在,每个投票都由一条记录表示,我们只需要计算指标即可。
query_metrics = f"""
SELECT
turno, state,
zone_code,
section_code,
COUNT(*) AS total_votes,
COUNT(DISTINCT state || zone_code || section_code) AS total_sections,
SUM(vote_time) AS voting_time_sum,
AVG(vote_time) AS average_voting_time,
MAX(nr_of_votes) AS total_ballot_items_voted,
SUM(nr_of_keys_pressed) AS total_keys_pressed
FROM
source
GROUP BY ROLLUP(turno, state, zone_code, section_code)
"""
由于我们需要在多个粒度级别上计算指标,因此理想的方法是使用 GROUP BY
加上 ROLLUP
。
在这一步中,DuckDB 表现出色:我们从 15GB 的数据开始,仅用了 36 秒就将文件大小减少到 88MB!
这是一个惊人的速度,它在不到一分钟的时间内,将超过 2 亿行数据按照 4 个不同的粒度级别进行了分组,其中最高级别的基数为 2,最低级别的基数约为 200,000!
结果
下表总结了测试结果:
整个流水线的总执行时间约为 2 小时 30 分钟,运行环境为 WSL,配置如下:
16GB DDR4 内存
第 12 代英特尔酷睿 i7 处理器
1TB NVMe 固态硬盘
在这个过程中,我注意到内存使用是一个瓶颈,因为 DuckDB 会不断在磁盘的 .temp/
目录中创建临时文件。此外,我在运行包含窗口函数的查询时遇到了很多问题:它们不仅比预期的执行时间长,而且程序还多次随机崩溃。
尽管如此,我认为最终的性能还是令人满意的,毕竟,我们谈论的是使用一台普通的个人电脑(与计算机集群相比,这台机器并不强大),通过复杂的查询处理了 1/2TB 的数据。
结论
事实上,处理数据有时就像提炼铀。我们从大量的原材料开始,通过一个艰难、耗时且成本高昂的过程(有时甚至会危及生命),最终只提取出一小部分有价值的信息。
言归正传,在我的文章中,我已经探索了许多数据处理方法,讨论了各种工具、技术、数据架构…… 我一直在寻找最佳的解决方案。了解这些知识非常重要,因为它可以帮助我们为正确的工作选择合适的工具。本文的目的正是为了探究 DuckDB 能够解决哪些问题,以及它能提供什么样的体验。
总的来说,这是一次不错的体验。
使用 DuckDB 非常顺利,我几乎不需要进行任何配置,只需使用普通的 SQL 语句导入和操作数据即可。换句话说,对于那些已经了解 SQL 和一些 Python 知识的人来说,DuckDB 几乎没有学习成本。在我看来,这是 DuckDB 的一大优势。它不仅使我的个人电脑能够处理 450GB 的数据,而且实现这一点的成本很低,无论是对环境还是对程序员来说都是如此。
在处理速度方面,考虑到项目的复杂性、450GB 的数据量以及我没有优化数据库参数的事实,2 小时 30 分钟的处理时间是一个不错的结果。特别是考虑到,如果没有 DuckDB,在我的个人电脑上完成这项任务几乎是不可能的,或者说极其复杂的。
DuckDB 的定位介于 Pandas 和 Spark 之间。对于小规模数据,Pandas 在易用性方面可能更有吸引力,特别是对于那些具有一定编程背景的人来说,因为 Pandas 提供了许多内置的转换函数,而这些函数在 SQL 中实现起来可能非常麻烦。Pandas 还可以与许多其他 Python 包无缝集成,包括 DuckDB。对于海量数据,Spark 可能是更好的选择,它具有并行处理、集群等优势。因此,DuckDB 填补了中等到不太大的项目的空白,在这些项目中,使用 Pandas 可能无法胜任,而使用 Spark 又有些大材小用。
DuckDB 扩展了单台机器的处理能力,并为本地数据分析和处理项目带来了新的可能性。毫无疑问,它是一个强大的工具,我将非常乐意将它添加到我的工具箱中。
此外,我希望这篇文章能够帮助你更好地了解 DuckDB。需要说明的是,我不是本文涉及的任何主题的专家,我强烈建议你进行更深入的学习和研究。我的参考资料列在下方,你可以在 GitHub 上找到相关代码。
感谢你的阅读!😉
引用链接
[1]
My First Billion (of Rows) in DuckDB: https://towardsdatascience.com/my-first-billion-of-rows-in-duckdb-11873e5edbb5[2]
ODbL: https://opendatacommons.org/licenses/odbl/[3]
图片来自巴西高等选举法院: https://www.tre-rn.jus.br/comunicacao/noticias/2021/Maio/urna-eletronica-25-anos-100-brasileira-e-admirada-pelo-mundo[4]
4: https://international.tse.jus.br/en/electronic-ballot-box/presentation[5]
开放数据门户: https://dadosabertos.tse.jus.br/[6]
(参见此视频): https://youtu.be/GaHWuQ_cBhA[7]
OLAP 多维数据集: https://en.wikipedia.org/wiki/OLAP_cube[8]
DuckDB 包: https://duckdb.org/docs/guides/python/install.html[9]
GitHub 存储库: https://github.com/jaumpedro214/urna-logs-data-eng
DuckDB实战
