




生产上有个慢sql,update set = (select )结构,需要多次对 (select )部分进行扫描,效率较低,可以尝试改写下
UPDATE EMP_USER A
SET (A.EMP_NAME,
A.EMP_ORG,
A.EMP_MOBILE,
A.EMP_GENDER,
A.EMP_STATE,
A.EMP_POST) =
(SELECT B.EMP_NAME,
B.DEPART1_CODE,
B.EMP_PHONE,
CASE
WHEN B.EMP_GENDER = '01001' THEN
'1'
ELSE
'2'
END AS EMP_GENDER,
CASE
WHEN B.EMP_STATUS = '00900' THEN
'0'
ELSE
'1'
END AS EMP_STATUS,
B.EMP_POST
FROM HR_EMP B
WHERE A.EMP_CODE = B.EMP_CODE
and B.EMP_CODE not in (select d.EMP_CODE
FROM HR_EMP d
group by d.emp_code
having count(1) > 1))
WHERE A.EMP_STATE = '0'
and A.EMP_CODE in (select C.EMP_CODE FROM HR_EMP C)
and A.EMP_CODE not in (select e.EMP_CODE
FROM EMP_USER e
group by e.emp_code
having count(1) > 1);
尝试初次改写:
Merge into EMP_USER A
USING (SELECT B.EMP_NAME,
EMP_CODE,
DEPART1_CODE,
B.EMP_PHONE,
EMP_GENDER,
EMP_STATUS,
EMP_POST
FROM HR_EMP B
WHERE B.EMP_CODE not in (select d.EMP_CODE
FROM HR_EMP d
group by d.emp_code
having count(1) > 1)) x
on (A.EMP_CODE = X.EMP_CODE)
when matched then
update
set A.EMP_NAME = x.EMP_NAME,
A.EMP_ORG = X.DEPART1_CODE,
A.EMP_MOBILE = X.EMP_PHONE,
A.EMP_GENDER =
(case
when x.EMP_GENDER = '01001' THEN
'1'
ELSE
'2'
end),
A.EMP_STATE =
(CASE
WHEN x.EMP_STATUS = '00900' THEN
'0'
ELSE
'1'
end),
A.EMP_POST = X.EMP_POST
WHERE A.EMP_STATE = '0'
and A.EMP_CODE in (select C.EMP_CODE FROM HR_EMP C)
and A.EMP_CODE not in (select e.EMP_CODE
FROM EMP_USER e
group by e.emp_code
having count(1) > 1);
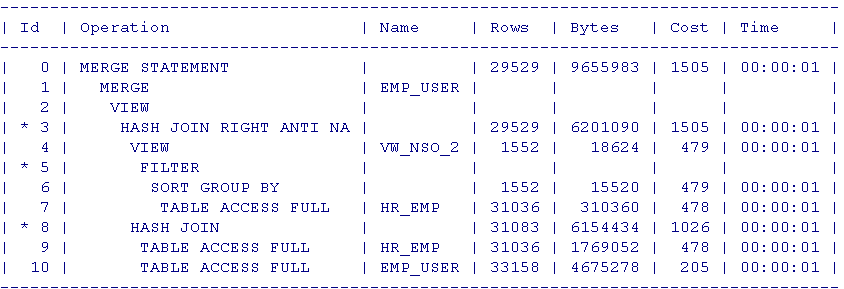
F5查看执行计划也正常,HR_EMP分组后的视图,与HR_EMP及EMP_USER的hash连接的结果集进行 hash join rigth anti na,都是全部扫描cost只有1505,应该不会很慢,生产上,也不能测试,自认为OK了。
上图即为生产上的F5执行计划
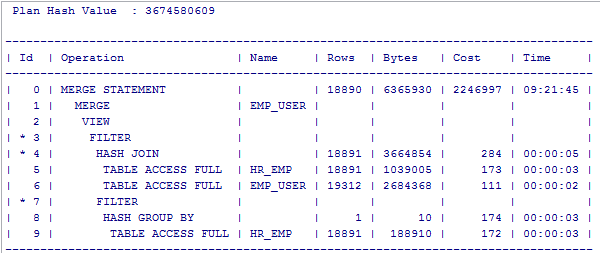
让开发尝试优化了,开发有自己的测试环境,一测,居然还慢了,问到他们的测试环境HR_EMP分组后的视图优化器只有1行,执行计划是:HR_EMP及EMP_USER的hash连接的结果集,与HR_EMP分组后的结果
集进行filter连接,查询HR_EMP分组后count(1)>1确实只有1行。那就继续改写。下图即为测试环境F5的执行计划
此处有时候存在误导, merge into 这最后的where 处的过滤条件,如果都删除了,跟不删除时的plan hash value是一样的,但是执行结果可能是不一样的,需要注意理解里面的过滤条件意义,是否可以真的省略!
WHERE A.EMP_STATE = '0' --主表的过滤条件,不能省略
and A.EMP_CODE in (select C.EMP_CODE FROM HR_EMP C) --主表与using表的关联条件,即 on (A.EMP_CODE = X.EMP_CODE) , 此处是多余的,可以省略
and A.EMP_CODE not in (select e.EMP_CODE --主表的过滤条件,意义是emp_code唯一的才更新,不能省略
FROM EMP_USER e
group by e.emp_code
having count(1) > 1);再次尝试改写
Merge into EMP_USER A
USING (select m.EMP_NAME,
m.EMP_CODE,
m.DEPART1_CODE,
m.EMP_PHONE,
m.EMP_GENDER,
m.EMP_STATUS,
m.EMP_POST
from (select B.EMP_NAME,
EMP_CODE,
DEPART1_CODE,
B.EMP_PHONE,
EMP_GENDER,
EMP_STATUS,
EMP_POST
FROM HR_EMP B) m,
(select e.EMP_CODE
FROM EMP_USER e
group by e.emp_code
having count(1) = 1) n
where m.EMP_CODE = n.EMP_CODE) x
on (A.EMP_CODE = X.EMP_CODE)
when matched then
update
set A.EMP_NAME = x.EMP_NAME,
A.EMP_ORG = X.DEPART1_CODE,
A.EMP_MOBILE = X.EMP_PHONE,
A.EMP_GENDER =
(case
when x.EMP_GENDER = '01001' THEN
'1'
ELSE
'2'
end),
A.EMP_STATE =
(CASE
WHEN x.EMP_STATUS = '00900' THEN
'0'
ELSE
'1'
end),
A.EMP_POST = X.EMP_POST
WHERE A.EMP_STATE = '0';Plan Hash Value : 191111253
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost | Time |
-----------------------------------------------------------------------------------------------
| 0 | MERGE STATEMENT | | 194 | 54902 | 301 | 00:00:05 |
| 1 | MERGE | EMP_USER | | | | |
| 2 | VIEW | | | | | |
| * 3 | HASH JOIN | | 194 | 42874 | 301 | 00:00:05 |
| * 4 | HASH JOIN | | 194 | 15908 | 190 | 00:00:03 |
| 5 | VIEW | | 194 | 5238 | 17 | 00:00:01 |
| * 6 | FILTER | | | | | |
| 7 | SORT GROUP BY | | 194 | 1940 | 17 | 00:00:01 |
| 8 | INDEX FAST FULL SCAN | SYS_EMP_USER_CODE | 19312 | 193120 | 15 | 00:00:01 |
| 9 | TABLE ACCESS FULL | HR_EMP | 18891 | 1039005 | 173 | 00:00:03 |
| 10 | TABLE ACCESS FULL | EMP_USER | 19312 | 2684368 | 111 | 00:00:02 |
-----------------------------------------------------------------------------------------------
在using的临时表 X中,与主表的关联条件是EMP_CODE,而X中有
B.EMP_CODE not in (select d.EMP_CODE
FROM HR_EMP d
group by d.emp_code
having count(1) > 1)
这个过滤条件,与最后的: A.EMP_CODE not in (select e.EMP_CODE
FROM EMP_USER e
group by e.emp_code
having count(1) > 1)
是重复的,所以最后的条件其实也是可以省略的,not in ....having count(1) > 1,对应的条件在本例中就是 in having count(1) = 1 故而进行了如上改写,在测试环境上能够快速执行成功,且与update方式执行结果一致,执行时长秒级以内,原执行时长几百秒。总结:对于update该写merge的改写,在大部分情况下是需要改写的,同时需要注意原update语句后面的where条件是否重复,在merge最后的where 条件中如果有子查询
需要注意此时的执行时长,本例中A.EMP_CODE not in (select e.EMP_CODE FROM EMP_USER e group by e.emp_code having count(1) > 1),在最后的写法上加上该条件的话,执行计划还是Plan Hash Value : 191111253
但是执行时长还是非常长,monitor显示耗时主要在 MERGE STATEMENT 这一步,也就是第 0 步!需要注意此处。以此例记录下,后续待研究
