




前言
昨天晚上,在刷董老师公众号的时候,刷到了有关物化视图的文章,其中有这么一段文字:
💡如果在物化视图定义的查询语句中指定了 ORDER BY 子句,刷新物化视图数据时不会保证数据仍然按照指定顺序进行存储。
💡虽然物化视图定义中的查询语句支持 ORDER BY 子句,但是不推荐使用。如果想要以指定顺序显示数据,应该在查询数据时明确指定排序字段,而不应该依赖表中的数据存储顺序。
简而言之,如果要使用物化视图的话,最好在定义的时候不使用 ORDER BY 子句,因为在刷新的时候,无法保证数据仍然有序。这不,又了解到一个新知识,之前也不曾关注过。
翻了一下官方文档,也确实有这么一段说明:
If there is an
ORDER BYclause in the materialized view's defining query, the original contents of the materialized view will be ordered that way; butREFRESH MATERIALIZED VIEWdoes not guarantee to preserve that ordering.
验证
复现一下,随机插入 10 条数据
postgres=# create table t1(id int);
CREATE TABLE
postgres=# insert into t1 select n from generate_series(10,50) as n order by random() limit 10;
INSERT 0 10
postgres=# select * from t1;
id
----
24
27
36
16
49
30
28
50
35
29
(10 rows)
再新建一个物化视图,同时指定 ORDER BY
postgres=# create materialized view mt1 as select * from t1 order by id;
SELECT 10
postgres=# select * from mt1;
id
----
16
24
27
28
29
30
35
36
49
50
(10 rows)
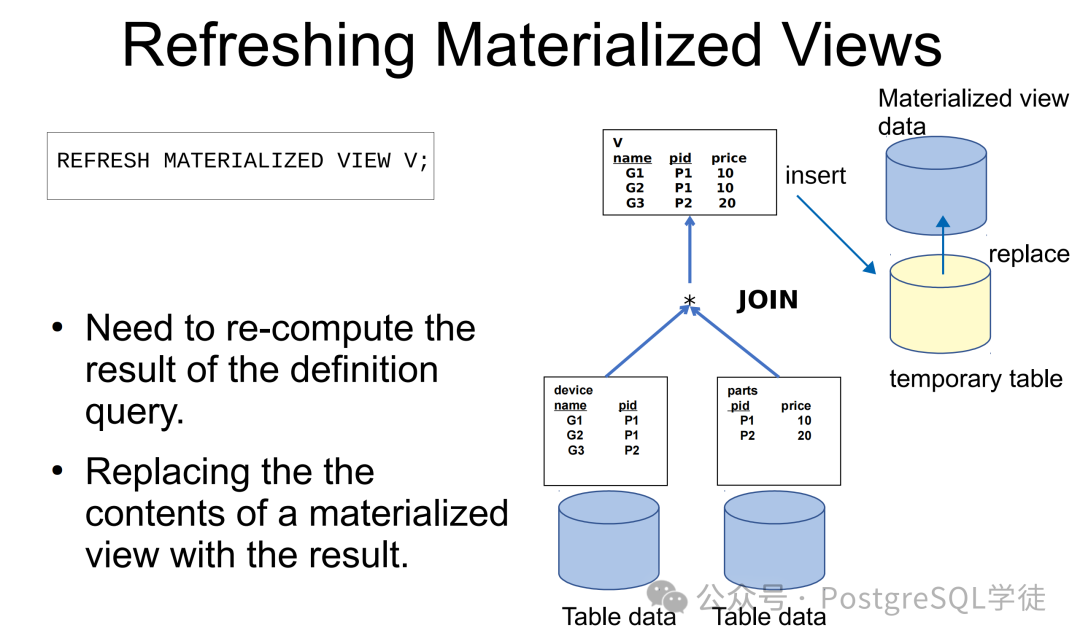
现在,数据如预期一样,有序存储。那么让我们刷新一下,截止 17,刷新只有两种方式:
不带有 concurrently,刷新会阻塞相应对象上的任何操作 带有 concurrently,允许读取 (只允许读取,其他写入行为不行),但是需要唯一索引,不能是表达式索引或者是部分索引
让我们分别试验一下
postgres=# insert into t1 select n from generate_series(100,300) as n order by random() limit 20;
INSERT 0 20
postgres=# refresh materialized view mt1;
REFRESH MATERIALIZED VIEW
postgres=# select * from mt1;
id
-----
16
24
27
28
29
30
35
36
49
50
101
110
113
114
116
126
159
162
174
181
196
201
210
215
244
267
271
277
278
282
(30 rows)
后面经过多次插入和刷新,发现不带有 concurrently 的刷新方式,可以保证物化视图中数据的有序性。不难理解,我之前在物化视图会膨胀吗文章中也有所提及,不带有 concurrently 的方式,每次会去取全量快照,取可见的数据 (所以不存在死元组),相当于每次都重新查一下,自然可以保证数据的有序性。
那么我们再看看生产中更为常见的方式,带有 concurrently 的方式刷:
postgres=# truncate table t1;
TRUNCATE TABLE
postgres=# insert into t1 select n from generate_series(10,50) as n order by random() limit 10;
INSERT 0 10
postgres=# create materialized view mt1 as select * from t1 order by id;
SELECT 10
postgres=# create unique index on mt1(id);
CREATE INDEX
第一次数据还是有序的,然后使用 concurrently 刷新
postgres=# insert into t1 select n from generate_series(100,300) as n order by random() limit 20;
INSERT 0 20
postgres=# refresh materialized view concurrently mt1;
REFRESH MATERIALIZED VIEW
postgres=# select * from t1;
id
-----
43
18
26
29
13
12
32
48
25
17
246
208
174
250
154
185
132
272
221
227
119
294
172
143
131
192
212
298
105
293
(30 rows)
这次,可以很明显地看到,数据已经无序了!其原理其实也不难理解,如果带有 concurrently,那么刷新会用到临时表,与老版本进行全外连接,生成"差值",并且新老版本之间不能有重复值,因此这也说明了为什么需要唯一索引,可以看到,这种方式实际上借助了临时表的插入和删除,与老版本一行一行进行比较,然后更新老版本。
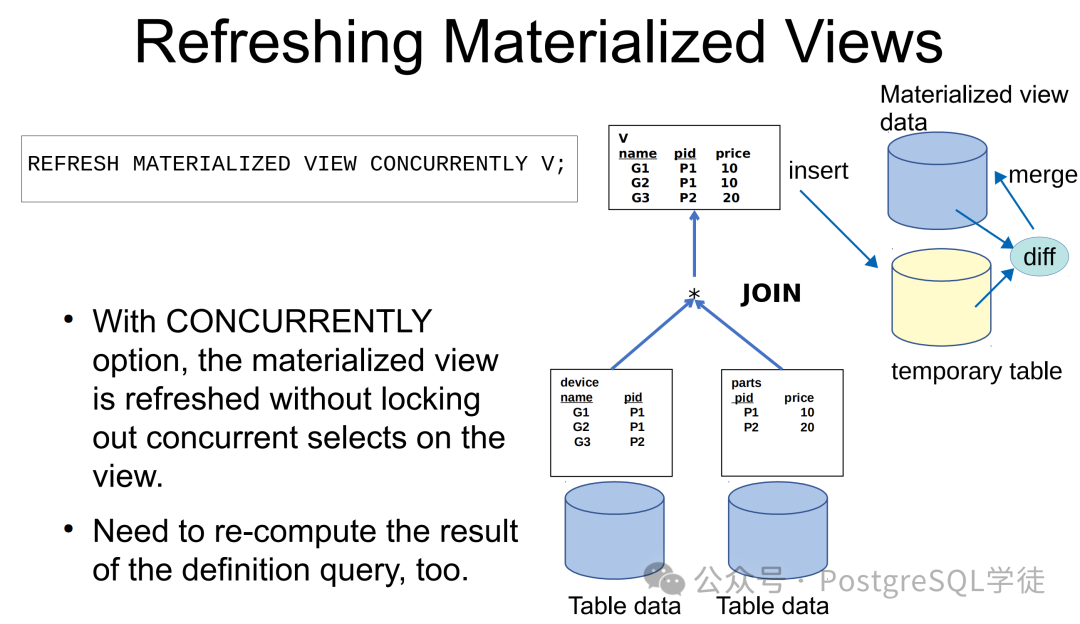
所以,这种方式就无法再去保证数据的有序性了,当然你说在其中某个阶段,再去做一个 order by 不就行了?确实如此,但是这样,我想无疑就会使得 concurrently 的效率再进一步大打折扣 (貌似有点牵强?)。关于这块的细节,读者可以参考 refresh_by_match_merge(),代码逻辑还是比较清晰的
resetStringInfo(&querybuf);
appendStringInfo(&querybuf,
"SELECT newdata.*::%s FROM %s newdata "
"WHERE newdata.* IS NOT NULL AND EXISTS "
"(SELECT 1 FROM %s newdata2 WHERE newdata2.* IS NOT NULL "
"AND newdata2.* OPERATOR(pg_catalog.*=) newdata.* "
"AND newdata2.ctid OPERATOR(pg_catalog.<>) "
"newdata.ctid)",
tempname, tempname, tempname);
if (SPI_execute(querybuf.data, false, 1) != SPI_OK_SELECT)
elog(ERROR, "SPI_exec failed: %s", querybuf.data);
...
appendStringInfo(&querybuf,
"CREATE TEMP TABLE %s AS "
"SELECT mv.ctid AS tid, newdata.*::%s AS newdata "
"FROM %s mv FULL JOIN %s newdata ON (",
diffname, tempname, matviewname, tempname);
小结
物化视图是我们在优化 SQL 的时候一个利器,它是预先生成的数据,像 join/filter 等都已经提前做好,并且你也可以收集其统计信息,但是坏处就是 refresh all-or-nothing,另外你要做查询的时候你得知道它的数据不是最新的,毕竟是 instantly stale。截止最新版的 17,也还没有实现增量刷新,pg_ivm 的限制一大坨,比如不支持分区表就大大限制了其使用场景。

其次,concurrently 在便利了使用的同时,也引入了一些弊端,比如无法保证数据的有序性,也会导致膨胀等等,因此,要时刻谨记物化视图的这些缺陷。另外,也再次提醒我们,如果我们需要明确的顺序,应该明确指定 ORDER BY,虽然数据的有序性可能会以某种方式自然发生,比如 CLUSTER,基于某列顺序加载等等,但是 CLUSTER 无法保证增量数据的顺序,加载之后的更新等等都会破坏数据的有序性。
参考
《PostgreSQL开发指南》第 32 篇 物化视图
