




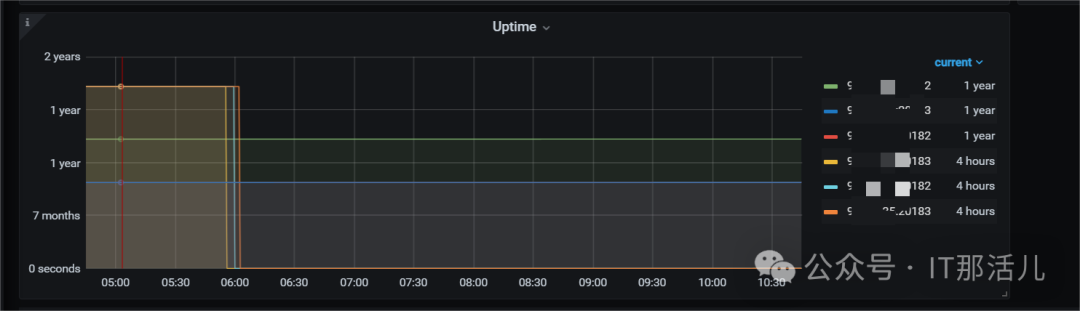
2024-03-04 06:01开始系统数据库集群收到多条告警,经查看发现是3个tikv实例陆续报错重启触发告警,每个实例从down到完成重启,耗时约1分钟左右,重启完成后集群正常运行,3个tikv实例报错信息相同。
2.1 发现问题
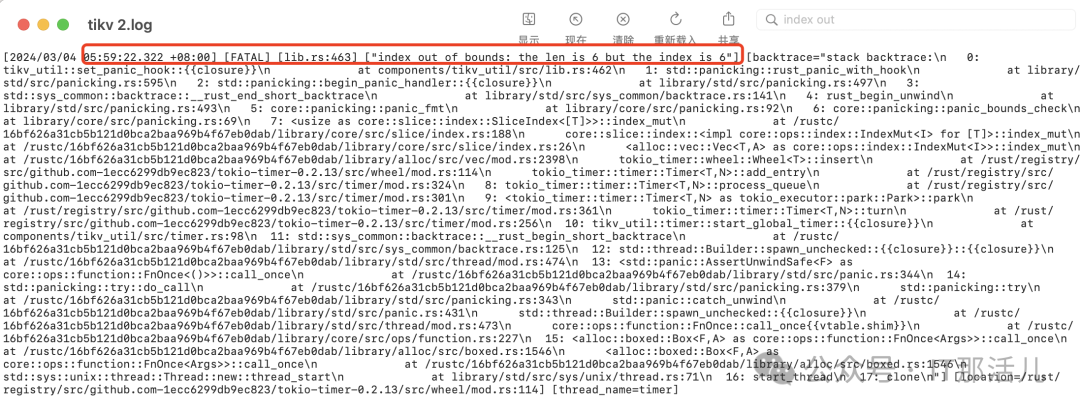
tikv组件依赖tokio_timer库存在bug,进程运行超过2^36ms,约795天,会出现“index out of bounds”错误,后续版本已修复该问题。
与监控数据对比,重启的3台tikv实例运行时间均为2年; tikv当前版本为v5.1.2,不在fix版本中(fix version: 5.0.7, 5.1.5, 5.2.4, 5.3.1, 5.4.1, 6.0.0及以后) tikv报错信息、堆栈日志与该bug完全一致,故障现象也一致。
本次事故后需确认使用TiDB集群版本,排查可能会出现故障的集群。
方案1:定期重启
本文作者:王润枫(上海新炬中北团队)
本文来源:“IT那活儿”公众号

文章转载自IT那活儿,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
