





作为一个玩了15年Oracle数据库的老司机,之前总觉得Oracle跑OLAP也没什么问题,实在不擅长还有一体机加持。因此之前很少去研究关注OLAP领域的一些分析型数据库。
在当今数据驱动的时代,实时数据处理和分析能力成为了企业竞争力的关键。今天偶然看到关于StarRocks的文章,因此就简单了解了一下。我发现StartRocks作为新一代开源 MPP 数据库,正以其卓越的性能和广泛的应用场景,从全球数据技术巨头手中抢夺市场份额。
我特意去看了下StartRocks的Github,好家伙!短短2年的时间,居然有超过8300个Star,1700+ Fork以及 350+Contributors,不得不说其发展非常的迅速。
StarRocks的架构是怎么样的?
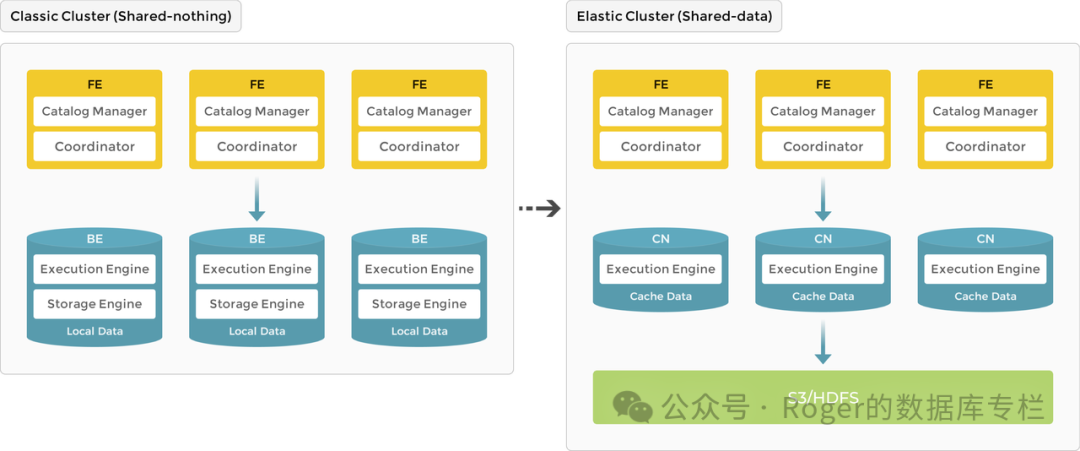
从其官方文章介绍来看,在3.0版本之前是存算一体架构,从3.0版本开始引入了存算分离模式。
对于存算一体和存算分离,我相信大家都比较了解了。顾名思义,存算一体就是指 BE同时负责数据存储和计算,至于其优势就是提供了极致的查询性能,效率极高。
其3.0 版本引入存算分离架构,数据存储功能从原来的 BE 中抽离,BE 节点升级为无状态的 CN 节点。数据可持久存储在远端对象存储或 HDFS 上,CN 本地磁盘只用于缓存热数据来加速查询。存算分离架构下支持动态增删计算节点,实现秒级的扩缩容能力。
大致的架构演进如下:
StarRocks的技术优势和特点
这里我简单总结并归纳一下,大概有如下几点:
1、极致的速度
StarRocks 采用了原生向量化执行引擎,通过向量化技术充分利用 CPU 的并行计算能力,实现了亚秒级查询返回。此外,StarRocks 还结合了列式存储、智能物化视图和 CBO 查询优化器等多种加速手段,使得其性能相较于传统数据库提升了 5-10 倍。
我通过查阅相关文档,我看从文档中提到其TPCH是16s、TPC-DS 是174s(注意这是利用非常一般的云环境)。单纯的从这个数据来看,我觉得还是比较惊人的。
2、全场景、统一分析
StarRocks适用于各种数据分析场景,包括 OLAP 多维分析、实时数据仓库、高并发查询和统一分析等。无论是对于需要快速响应的实时数据,还是对于需要深度挖掘的历史数据,StarRocks 都能提供高效、准确的分析结果。
除了以上技术特性,StarRocks 也具备一个轻量级数据分析解决方案的多个优势:
• 灵活的数据建模:
StarRocks 支持各种数据建模方法,包括平面表、星型模式和雪花模式。
• 实时数据分析:
StarRocks 高效支持实时数据提取和分析,延迟极低,并发性高。
• 与 MySQL 的兼容:
StarRocks 与 MySQL 线路兼容,允许现有的 MySQL 应用程序无需修改代码即可使用其分析解决方案。
• 支持多种数据源:
StarRocks 可以直接分析存储在数据湖中的数据,无需数据迁移,并支持 Apache Iceberg、Apache Hudi、Apache Hive 和 Delta Lake 等各种开放表格式。
从其网站的相关技术文章的介绍来看,StarRocks的应用场景还是蛮多的。
应用场景广泛,用户遍布国内外
StarRocks 的应用灵活性和场景适应性极强。例如,在金融行业,StarRocks 能够处理大规模的交易数据,为风险管理和市场分析提供实时支持。在互联网和零售领域,它能够快速分析用户行为,帮助企业优化广告营销和促销策略。
其次StarRocks 的多维数据模型和实时处理能力,使其成为许多企业数据平台的核心组件。海外市场,在 2023 年 Databricks 的峰会上,StarRocks 也在 DataBricks CEO 的演讲中被提及,受到了业界的高度关注。
StarRocks 正在成为替换传统大数据组件的新选择
据悉,StarRocks 正在利用自身独特的高性能低成本优势,逐渐在全球范围内替换传统数据库。例如,在替换 Hbase 方面,StarRocks 作为新型分析引擎提供了更高效的数据压缩、更快的查询速度和更低的运维成本,成为 Airbnb(爱彼迎)、Pinterest(视觉发现平台和搜索引擎)、Demandbase( B2B 营销技术公司)、米哈游、腾讯游戏等大型企业的实时数据引擎的新选择。这种替换不仅提高了数据处理的效率,也为企业节省了大量的时间和资源。
那么StarRocks有哪些典型的应用案例呢?
我特意查了下,在互联网应用场景相对多一些,简单罗列了几个耳熟能详的应用案例:
StarRocks落地实践典型案例
1、腾讯游戏
腾讯游戏公共数据平台部原始架构复杂、数据一致性难以保证、离线计算造成数据极速膨胀,带来存储压力等问题。为实现存算分离、数据分层与查询性能优化,腾讯游戏选择 StarRocks 作为构建新的湖仓一体化的核心组件,并实现如下收益。
性能提升:数据读取性能提升了约 6 倍,通过 Agg 下推优化减少了不必要的数据传输。
资源管理:通过 K8s 的 HPA 机制,实现了 CN 节点的自动扩容和缩容,提高了资源管理的灵活性和效率。数据处理能力:支持大规模和高并发的数据处理需求,例如某头部游戏业务每天新增约 50TB 数据,支持 200 个并发查询,查询 P90 耗时为 2 秒。
2、Airbnb
在过去,Airbnb 使用 Druid 和 Presto 查询 Hive 表,但面临数据变更不敏感、数据加工成本高昂等问题。传统数据处理流程中,工程师需要将数据通过 ETL 转换为宽表并存储,分析师在此基础上进一步处理,这导致开发分散和效率低下。
Airbnb 通过 StarRocks 构建了统一的指标平台 Minerva,该平台支持 A/B 测试和多种数据使用场景,帮助 Airbnb 解决了查询性能、效率以及成本问题。
a)通过物化视图,减少物化视图的数量,服务更多查询类型,减少多表 Join 的需求。同时通过视图裁剪、生成列和物化视图,简化数据管理,提升数据性能,且支持派生指标的生成。b) 开发周期缩短:指标开发周期和流程显著缩短,从 3.5 天减少到 1.5 天。
c) 查询速度加快:大部分查询能够在 1 秒内完成,即使是涉及两年数据的多表 Join 查询,也能在 7-8 秒内得到结果。
3、小红书
以 Spark 为核心的数仓架构在处理大规模数据回刷方面已取得进展,但在资源和时间消耗上仍面临挑战。为了突破这些限制,小红书数据仓库团队通过对比选型,将 StarRocks 融入到离线处理流程,替换掉部分 Spark 处理的任务,并优化较为耗时的 Cube 计算,大幅度提高了数据的执行效率。
经过改造的离线处理链路,可以有效降低任务资源消耗,提前数据产出时间。作业执行时间从小时级压缩至分钟级,计算资源使用量降低了 90% 以上,日数据产出时间提前了 1.5 小时,回刷时间减少了 90%,回刷成本降低了 99% 以上。例如在回刷 2022 年和 2023 年的数据时,基于 StarRocks 的链路相比基于 Spark 的链路,成本从上百万元降低到几千元,回刷时间从一个月缩短到几天。
从相关介绍来看,除了上面的一些典型案例,比如其他一些比较知名的企业也都在用,例如滴滴、Shopee、Trip等等。由此不难看出StarRocks 作为一种新型MPP架构,正逐渐兼容并替换过去传统大数据组件如 Hadoop 等中的分析计算引擎,帮企业实现一份数据源高效快速地支撑多种分析应用。
在数据库领域中,StarRocks正以其独特的优势挑战传统数据库的主导地位,逐步成为企业数据平台的新选择。随着企业对实时数据处理和分析需求的不断增长,StarRocks有望进一步巩固其市场地位,并在全球范围内实现更广泛的应用。
希望国产MPP数据库厂商发展的越来越好,等这段时间忙完,我一定要动手实测一把StarRocks!
参考:
1、https://github.com/StarRocks
2、https://docs.mirrorship.cn/zh/docs/benchmarking/TPC-H_Benchmarking/
3、https://www.starrocks.io/blog/benchmark-test
