




关注 GreptimeDB,了解更多技术干货👇
2024 年转眼已快过半,我们 Greptime 团队也在按计划稳步迈向 v1.0 版本的生产发布。今天,我们很高兴地宣布 v0.8 版本已正式上线,该版本引入了 Flow Engine,一个轻量级、面向时序的流计算框架,能够提供持续聚合能力。
从 v0.7 到 v0.8,Greptime 团队取得了显著的进展:共合并了 88 次代码提交,修改了 893 个文件,其中包括 40 项功能增强,20 项错误修复,22 项代码重构,以及大量的测试工作。在此期间,共有 16 位来自社区的个人贡献者提交了 44 次代码贡献。
Tips

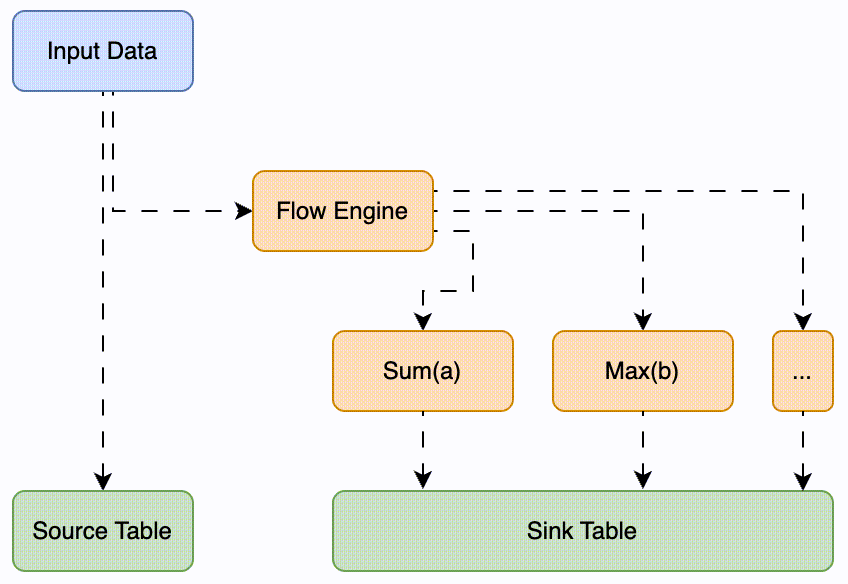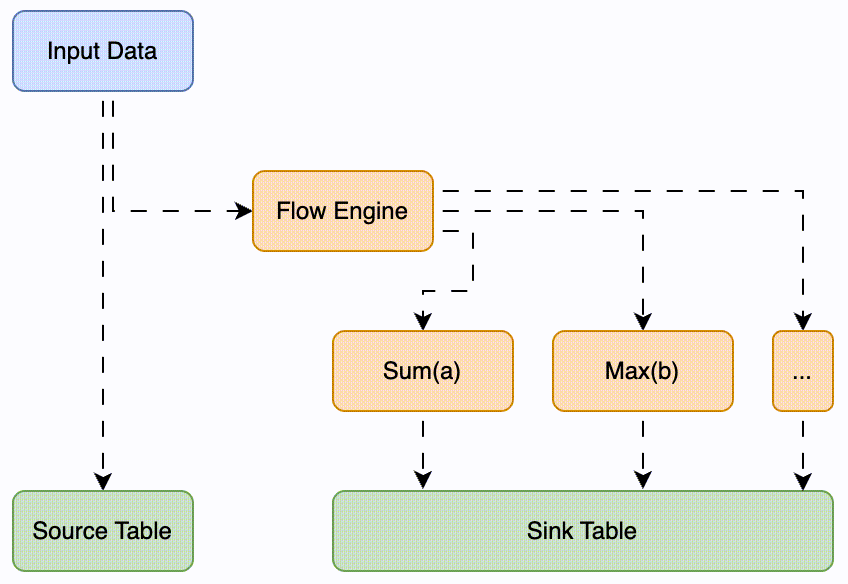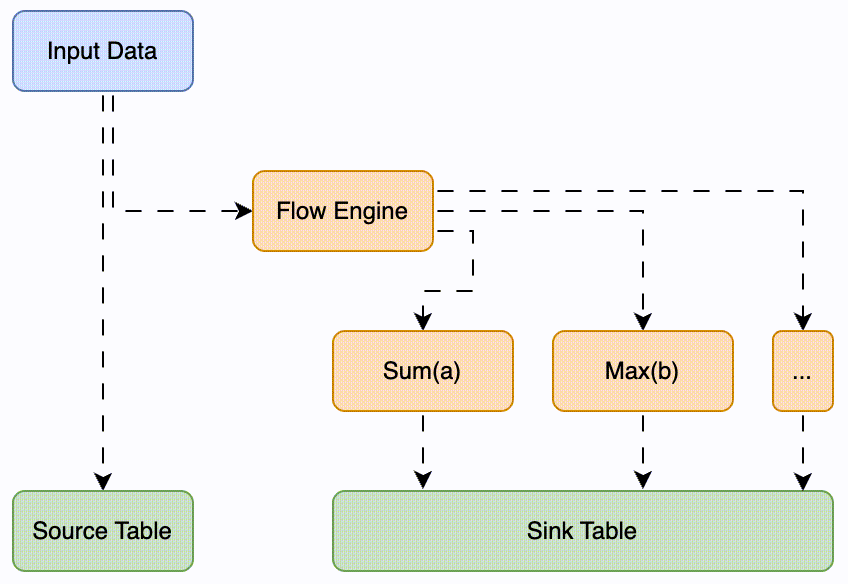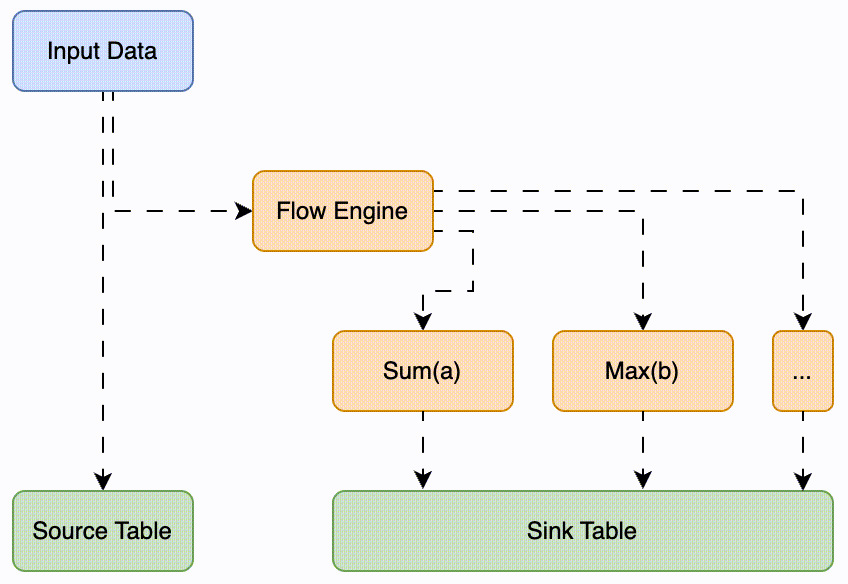
(Flow Engine 工作流程示意图)
CREATE FLOW IF NOT EXISTS my_flow
OUTPUT TO my_sink_table
COMMENT = "My first flow in GreptimeDB"
AS
SELECT count(item)
FROM my_source_table
GROUP BY tumble(time_index, '5 minutes');
持续聚合任务演示
CREATE TABLE numbers_input (
number INT,
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY(number),
TIME INDEX(ts)
);
CREATE TABLE out_num_cnt (
sum_number BIGINT,
start_window TIMESTAMP TIME INDEX,
end_window TIMESTAMP,
update_at TIMESTAMP,
);
CREATE FLOW test_numbers
SINK TO out_num_cnt
AS
SELECT sum(number) FROM numbers_input GROUP BY tumble(ts, '1 second','2024-5-20');
INSERT INTO numbers_input
VALUES
(20,1625097600000),
(22,1625097600500);
SELECT * FROM out_num_cnt;
sum_number | start_window | end_window | update_at
------------+----------------------------+----------------------------+----------------------------
42 | 2021-07-01 00:00:00.000000 | 2021-07-01 00:00:01.000000 | 2024-05-17 08:32:56.026000
(1 row)
1. 支持对列类型的更改
这个特性可以让用户轻松地更改表中列的数据类型,无需重新建表或者手动迁移数据,提高了数据库的灵活性和可维护性。
ALTER TABLE monitor MODIFY COLUMN load_15 STRING;
注意:修改的列不能是 tag(主键)或 time index,并且必须可以为空以确保数据可以安全地转换(转换失败时返回 “NULL”)。
2. 实现了 information_schema 的集群管理信息表(cluster_info)
在 information_schema 中增加了 cluster_info 表。我们可以通过查询 cluster_info 表获取集群的信息。这个功能帮助管理员监控和管理数据库集群的健康状态,及时发现和解决问题。
+---------+-----------+----------------+---------+------------+-------------------------+-------------+-------------+
| peer_id | peer_type | peer_addr | version | git_commit | start_time | uptime | active_time |
+---------+-----------+----------------+---------+------------+-------------------------+-------------+-------------+
| 1 | DATANODE | 127.0.0.1:4101 | 0.7.2 | 86ab3d9 | 2024-04-30T06:40:04.791 | 4s 478ms | 1s 467ms |
| 2 | DATANODE | 127.0.0.1:4102 | 0.7.2 | 86ab3d9 | 2024-04-30T06:40:06.098 | 3s 171ms | 162ms |
| 3 | DATANODE | 127.0.0.1:4103 | 0.7.2 | 86ab3d9 | 2024-04-30T06:40:07.425 | 1s 844ms | 1s 839ms |
| -1 | FRONTEND | 127.0.0.1:4001 | 0.7.2 | 86ab3d9 | 2024-04-30T06:40:08.815 | 454ms | 47ms |
| -1 | METASRV | 127.0.0.1:3002 | 0.7.2 | 86ab3d9 | 2024-04-30T06:39:03.290 | 1m 5s 677ms | |
+---------+-----------+----------------+---------+------------+-------------------------+-------------+-------------+
3. 支持 Append-only 表
用户可以在建表时通过设置 append 模式(create table ... engine=mito with('append_mode'='true');)来创建 Append-only 模式的表,Append-only 表只支持插入,不支持删除和更新,插入的数据也不会去重,因此可以更方便地存储重复的数据。
4. 支持 DROP DATABASE 语句
DROP DATABASE 语句可以快速删除一个 database 实例下的所有表和资源。
6. 新的表分区方式和分区语法
考虑到未来自动分区、重新分区等需要频繁变更分区的需求,我们开始开发一种新的分区语法。使用方式可参考官方中文文档:
https://docs.greptime.cn/contributor-guide/frontend/table-sharding
例如:分析 count(*) 的单步耗时
explain analyze SELECT count(*) FROM system_metrics;
+-------+------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| stage | node | plan |
+-------+------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| 0 | 0 | MergeScanExec: peers=[4402341478400(1025, 0), ] metrics=[output_rows: 1, ready_time: 6352264, finish_time: 7509279,] |
| | | |
| 1 | 0 | AggregateExec: mode=Final, gby=[], aggr=[COUNT(greptime.public.system_metrics.ts)] metrics=[output_rows: 1, elapsed_compute: 108029, ] |
| | | CoalescePartitionsExec metrics=[output_rows: 32, elapsed_compute: 83055, ] |
| | | AggregateExec: mode=Partial, gby=[], aggr=[COUNT(greptime.public.system_metrics.ts)] metrics=[output_rows: 32, elapsed_compute: 334913, ] |
| | | RepartitionExec: partitioning=RoundRobinBatch(32), input_partitions=1 metrics=[repart_time: 1, fetch_time: 441565, send_time: 30325, ] |
| | | StreamScanAdapter { stream: "<SendableRecordBatchStream>" } metrics=[output_rows: 3, mem_used: 24, ] |
| | | |
| | | Total rows: 1 |
+-------+------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1. 创建一个全新的 v0.8 集群
2. 关闭旧集群流量入口(停写)
3. 通过 GreptimeDB CLI 升级工具导出表结构和数据
4. 通过 GreptimeDB CLI 升级工具导入数据到新集群
5. 入口流量切换至新集群
详细升级指南请参考:
中文:https://docs.greptime.cn/user-guide/upgrade
英文:https://docs.greptime.com/user-guide/upgrade
我们下一个里程碑在 7 月初,届时将推出 v0.9 版本。这一版本将引入 Log Engine,一个专门的为日志存储和查询优化的存储引擎,会包含全文索引,也可能会与 Flow Engine 进行一定的结合,比如日志内容解析抽取。GreptimeDB 的终态目标是一个融合 Metrics 和 Log 的泛时序数据库。
欢迎大家来到直播间了解我们的版本更新计划,也欢迎各位参与代码贡献或功能、性能的反馈和讨论,让我们携手见证 GreptimeDB 持续的成长与精进。
关于 Greptime
Greptime 格睿科技专注于为物联网(如智慧能源、智能汽车等)及可观测等产生大量时序数据的领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前主要有以下三款产品:
GreptimeDB 是一款用 Rust 语言编写的开源时序数据库,具有云原生、无限水平扩展、高性能和融合分析等特点,帮助企业实时读写、处理和分析时序数据的同时,降低长期存储的成本。我们提供 GreptimeDB 企业版,支持更多企业特性和定制化服务,如有需要欢迎联系我们:15310923206(同微信)。
GreptimeCloud 是一款全托管的云上数据库即服务(DBaaS)解决方案,基于开源时序数据库 GreptimeDB 打造,能够高效支持可观测、物联网、金融等领域的应用。用户可以通过内置的可观测性解决方案 GreptimeAI 全面掌握 LLM 应用的成本、性能、流量和安全等情况。
车云一体解决方案 是一款深入车企实际业务场景的时序数据库解决方案,解决了企业车辆数据呈几何倍数增长后的实际业务痛点。多模态车端数据库结合云端 GreptimeDB 企业版帮助车企极大降低流量、计算和存储成本,并帮助提升数据实时性和业务洞察能力。

Star us on GitHub Now:
https://github.com/GreptimeTeam/greptimedb
官网:https://greptime.cn/
文档:https://docs.greptime.cn/
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime/
往期精彩文章:



👇 点击下方阅读原文,立即体验 GreptimeDB!
