




以下是 GreptimeDB 中的一个错误示例:
0: Foo error, at src/common/catalog/src/error.rs:80:10
1: Bar error, at src/common/function/src/error.rs:90:10
2: Root cause, invalid table name, at src/common/catalog/src/error.rs:100:10
pub enum Result<T, E> {
/// Contains the success value
Ok(T),
/// Contains the error value
Err(E),
}
本篇博客分享了我们在像 GreptimeDB 这样相对复杂的系统中组织复杂错误类型的经验,从定义错误类型,到如何将错误呈现给最终用户。这样的系统由多个组件组成,每个组件都有自己的错误定义。
Rust 标准库的不少错误类型都实现了 std::error::Error trait,例如 std::io::Error 和 std::fmt::Error 等。但是,复杂的 Rust 项目通常会自己定义若干个错误类型。这是因为项目需要表达自己的错误信息,或者需要将多个来源的错误聚合成为同一个错误枚举类型。
由于 std::error::Error trait 并不复杂,手动实现自定义错误类型就相对简单。然而,随着错误枚举变种的增加,处理大量模板代码将变得非常困难。
目前,有一些广泛使用的工具箱可以帮助处理自定义错误类型。例如,著名 Rust 魔法师 dtolnay 开发的 thiserror[1] 和 anyhow[2] 就是 Rust 错误处理生态当中的早期实践。其中 thiserror 主要用于库,而 anyhow 主要用于终端应用。这一规则也适用于大多数情况。
但对于像 GreptimeDB 这样的项目,我们将整个工作空间划分为几个单独的子包,并且需要为每个包定义一个错误类型,又希望在组合操作不同错误类型时有简洁的开发者体验。thiserror 和 anyhow 都不容易实现这一点。
因此,我们选择了另一个包 snafu[3] 来构建我们的错误系统。它类似于 thiserror 和 anyhow 的组合。thiserror 提供了一个方便的宏来定义自定义错误类型,包括显示、源和一些上下文字段。anyhow 提供了一个 Context trait,可以轻松地从一个底层错误转换为另一个带有新上下文的错误。snafu 既提供了自定义错误类型的过程宏工具,也提供了一系列 context 辅助方法来构造带有上下文的错误实例。
thiserror 主要实现了错误类型的 std::convert::From[4] trait,这样你就可以轻松地使用 ? 来传递你接收到的错误。这也意味着你不能定义两个来自同一来源的错误变种。假设程序正在进行一些 I/O 操作,使用 thiserror 定义的错误无法区分错误是在写入还是读取时生成的。这也是我们不使用 thiserror 的一个重要原因:类型中的上下文模糊不清。
设计目标
enum Error{
ReadSocket(hyper::Error),
DecodeMessage(serde_json::Error),
Operation(GreptimeError),
EncodeMessage(serde_json::Error),
WriteSocket(hyper::Error),
}
当发生错误时,一个可能得错误信息是:DecodeMessage(serde_json: invalid character at 1)。但是,在某个具体组件的逻辑里,可能有超过 10 个地方进行消息解码,每次解码都可能抛出解码错误!我们如何确定在哪一步发现了无效内容呢?很明显,仅仅依靠 Root Cause 是不足以断定的。
因此,尽管 Root Cause 告诉了我们发生了什么错误,但是如果我们想了解这个错误发生的具体位置,以及应该如何处理这个错误,我们就需要错误信息暴露更多的细节上下文。
比如,以下是一个 GreptimeDB 错误日志的示例:
Failed to handle protocol
0: Failed to handle incoming content, query: blabla, at src/protocol/handler.rs:89:22
1: Failed to reading next message at queue 5 of 10, at src/protocol/loop.rs:254:14
2: Failed to decode `01010001001010001` to ProtocolHeader, at src/protocol/codec.rs:90:14
3: serde_json(invalid character at position 1)
一个好的错误报告不仅能说明错误的根因,更重要的是,处理错误的人能够从错误中获取到什么信息。上面这个错误报告的模式,我们称之为错误堆栈。错误堆栈报告了错误发生的关键轨迹。这非常直观,而且你大概在其他地方,例如 Backtrace 的使用中,看到过类似的形式。
上面的日志准确全面地报告了错误发生的情况,包括用户最终看到的错误到失败的根本原因。此外,还有每个错误堆栈中错误实例确切的行号和列号。可以看到,这个错误是“来自查询 'blabla',第五个包的头部已损坏”。这很可能是无效的用户输入,并且我们可能不需要在服务器端处理它。
这个示例显示了一个错误需要包含的关键信息:
根本原因:告诉我们发生了什么;
完整的上下文堆栈:用于调试或确定错误发生的位置;
从用户的角度看发生了什么:决定了我们是否需要向用户公开展示错误。
很多时候,只要我们使用的库或函数使用了正确实现的错误类型,如同前文展示的 DecodeMessage 示例,根本原因是清晰的。但是,只有 Root Cause 很多时候不足以让用户处理接收到的错误信息。
这里是一个来自 Databricks 所作的 Delta Lake 的示例[5],佐证了我们关于错误堆栈必要性的观点。
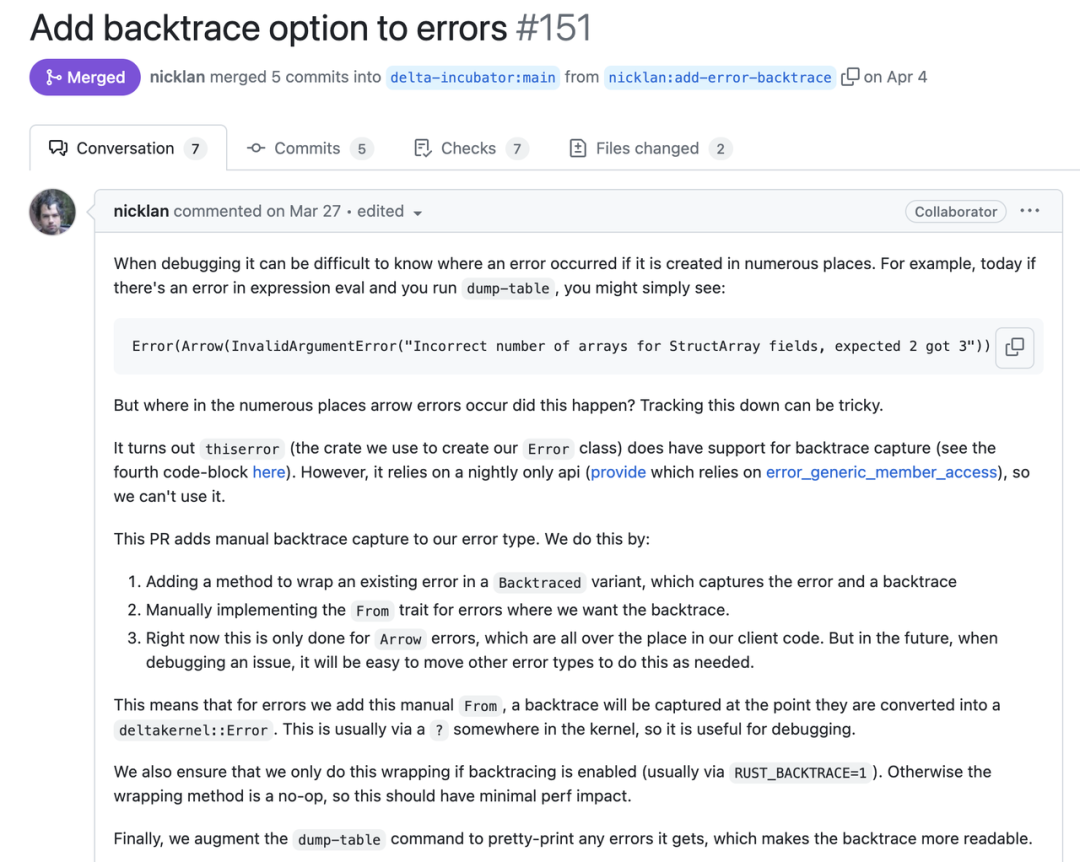
(Delta Lake 示例图)
在接下来的部分中,我们将关注上下文堆栈和展示错误的方式,并介绍我们是如何实现这些功能的。
标准库 Backtrace
回到 DecodeMessage 的例子。现在我们知道了错误发生的 Root Cause 是 DecodeMessage(serde_json: invalid character at 1),但是,我们不清楚这个错误发生在哪一步:是解码 Header 时发生的?还是解码 Body 时发生的?
一个自然的想法是获取错误发生时的 Backtrace。.unwrap() 是第一个能想到的选择:当错误发生时,它将打印调用的 Backtrace(当然,这是一个坏的实践)。.unwrap() 使用的标准库 Backtrace 提供了完整的调用堆栈以及行号。然后,你会逐层检查源代码,跳过许多无关的系统调用堆栈、运行时堆栈和标准库堆栈,最终将看到错误相关的应用层代码。
如今的 Rust 生态中,许多库也提供在错误构建时捕获 Backtrace 的能力。然而,即使标准库 Backtrace 可以解决功能问题,它在实际运行中也会大量消耗 CPU(#1261[6])和内存(#1273[7])资源,从而推高 Backtrace 的使用成本。
捕获 Backtrace 会大大减慢程序的运行速度,因为它需要遍历调用堆栈并翻译指针。同时,为了能够翻译堆栈指针,程序需要在二进制文件中包含大量的 debuginfo,导致编译产物显著体积增加。在 GreptimeDB 中,使用这一策略将导致最终二进制文件大小增加 700MB 以上(比没有调试信息时的 170MB 增加了 4 倍)。
而且,捕获的标准库 Backtrace 中包含许多噪音,因为系统无法区分代码是来自标准库、第三方异步运行时还是我们的代码库。
标准库 Backtrace 跟我们最终实现的错误堆栈方案之间还有一个区别。标准库 Backtrace 告诉我们如何回到错误发生的位置,但是这个位置是由标准库提供的,应用没有办法更好的展示错误传播的逻辑轨迹。而错误堆栈则展示了错误是如何传播的。
async fn handle_request(req: Request) -> Result<Output> {
let msg = decode_msg(&req.msg).context(DecodeMessage)?; // propagate error with new stack and context
verify_msg(&msg)?; // pass error to the caller directly
process_msg(msg).await? // pass error to the caller directly
}
async fn decode_msg(msg: &RawMessage) -> Result<Message> {
serde_json::from_slice(&msg).context(SerdeJson) // propagate error with new stack and context
}
1: <alloc::boxed::Box<F,A> as core::ops::function::Fn<Args>>::call
at /rustc/3f28fe133475ec5faf3413b556bf3cfb0d51336c/library/alloc/src/boxed.rs:2029:9
std::panicking::rust_panic_with_hook
at /rustc/3f28fe133475ec5faf3413b556bf3cfb0d51336c/library/std/src/panicking.rs:783:13
... many lines for std's internal traces
22: tokio::runtime::task::raw::RawTask::poll
at /home/wayne/.cargo/registry/src/index.crates.io-6f17d22bba15001f/tokio-1.35.1/src/runtime/task/raw.rs:201:18
... many lines for tokio's internal traces
32: std::thread::Builder::spawn_unchecked_::{{closure}}::{{closure}}
at /rustc/3f28fe133475ec5faf3413b556bf3cfb0d51336c/library/std/src/thread/mod.rs:529:17
... many lines for std's internal traces
可以看到,这包括了大量你不关心的代码路径,例如标准库、tokio 运行时和系统调用等堆栈。
我们实现的错误堆栈方案,只在显式调用 .context 添加上下文时包含参数提供的上一层错误的堆栈。
对于其他复杂处理逻辑,如批处理,如果其中某一步产生了错误,这个错误可能不会立即传播,而是暂时保留。错误堆栈方案中的虚拟堆栈可以合并这些错误上下文,而标准库 Backtrace 在错误生成时立即捕获的。这导致后者的信息可能残缺不全。例如,标准库 Backtrace 将捕获 map-reduce 逻辑的中间步骤。但虚拟堆栈可以支持我们将捕获时间推迟到 reduce 之后。这样,你就有了更多关于整个任务的信息。
虚拟用户堆栈
0: Failed to handle incoming content, query: blabla, at src/protocol/handler.rs:89:22
1: Failed to reading next message at queue 5 of 10, at src/protocol/loop.rs:254:14
2: Failed to decode `01010001001010001` to ProtocolHeader, at src/protocol/codec.rs:90:14
3: serde_json(invalid character at position 1)
堆栈层由 3 部分组成:[STACK_NUM]: [MSG], at [FILE_LOCATION]
Stack num 代表堆栈的编号。更小的数字意味着更外层的错误,这个数字从 0 开始计数;
Message 对应与某一层相关的消息。这是调用错误的 std::fmt::Display[8] 实现获得的。开发者可以在这里附加有用的上下文,如查询字符串或循环计数器;
File location 是错误生成(以及传播,对于中间错误层而言)的位置。Rust 提供了 file![9]、line![10] 和 column![11] 宏来帮助获取这些信息。我们展示它的方式也是经过考虑的,大多数编辑器可以直接跳转到对应的位置。
在实践中,我们使用 snafu::Location[12] 来收集代码位置。因此,每个位置都能精准指向错误构建的地方。通过这一链条,我们知道这个错误是如何生成并传播到最上层的。
#[derive(Snafu)]
pub enum Error {
#[snafu(display("General catalog error: "))] // <-- the `Display` impl derive
Catalog {
location: Location, // <-- the `location`
source: catalog::error::Error, // <-- inner cause
}
}
pub trait StackError: std::error::Error {
fn debug_fmt(&self, layer: usize, buf: &mut Vec<String>);
fn next(&self) -> Option<&dyn StackError>;
fn last(&self) -> &dyn StackError where Self: Sized { ... }
}
stack_trace_debug 过程宏主要做两件事:
生成实现 StackError[15] 的代码;
基于 debug_fmt() 实现 std::fmt::Debug[16]。
顺带一提,我们已经在 GreptimeDB 的所有错误中添加了 Location 和 display。这是实践错误堆栈方法论所需的必要劳动时间。
过程宏的实现要点
错误是一个单向链表,像洋葱一样从外层到内层。因此,我们可以在最外层捕获一个错误并逐层深入。
我们在这里需要处理的一个棘手问题是如何区分系统内部错误和外部错误,因为外部错误并不总是带有堆栈信息,实际上将成为错误堆栈的最内层。
内部错误都实现了同一个特性 ErrorExt [17],可以用作标记。但是依赖实现 ErrorExt trait 进行判断,需要重复调用 downcast 测试,这会明显提高错误处理花费的时间。所以,我们选择简单地为通过命名来区分内外部错误。
#[derive(Snafu)]
#[stack_trace_debug]
pub enum Error {
#[snafu(display("Failed to deserialize value"))]
ValueDeserialize {
#[snafu(source)]
error: serde_json::error::Error, // <-- external source
location: Location,
},
#[snafu(display("Table engine not found: {}", engine_name))]
TableEngineNotFound {
engine_name: String,
location: Location,
source: table::error::Error, // <-- internal source
}
}
StackError::debug_fmt[19] 方法用于渲染错误堆栈。它会在生成的代码中递归调用。每层错误都会向可变缓冲区写入自己的调试消息。内容将包含从 #[snafu(display)]属性捕获的错误描述、像 TableEngineNotFound 这样的变体类型和来自枚举的位置。
鉴于我们已经以这种方式定义了我们的错误类型,采用堆栈错误不需要太多工作,只需向每种错误类型添加属性宏 #[stack_trace_debug] 即可。
向终端用户展示错误
到目前为止,我们已经完成了大部分工作。这是关于如何向用户展示错误的最后一部分。
不同于系统开发者,用户可能不关心行号甚至是堆栈。那么,什么信息对终端用户有帮助呢?
Failed to handle protocol
0: Failed to handle incoming content, query: blabla, at src/protocol/handler.rs:89:22
1: Failed to reading next message at queue 5 of 10, at src/protocol/loop.rs:254:14
2: Failed to decode `01010001001010001` to ProtocolHeader, at src/protocol/codec.rs:90:14
3: serde_json(invalid character at position 1)
让我们组合一下刚才挑选的部分。最终呈现给用户的错误消息是:
Failed to handle protocol - Failed to decode `01010001001010001` to ProtocolHeader (serde_json(invalid character at position 1))
我们的经验是,最内层的错误的消息可能很有用,因为它更接近真正出错的地方。最外层错误的类别通常更准确,因为它来自于错误展示给用户的地方。简而言之,我们提出的错误消息方案是:
KIND - REASON ([EXTERNAL CAUSE])
综上所述,错误堆栈或说虚拟用户堆栈可以非常好的解决复杂 Rust 项目中错误处理的问题。相比于标准库的 Backtrace,错误堆栈更精确,成本更低。
那么,错误堆栈实际的成本到底有多少呢?
错误堆栈方案的运行时开销,只需要格式化打印每层错误的原因和位置。
编译产物体积方案,错误堆栈方案更体现出优势。GreptimeDB 的二进制里,调试符号占用约 700MB。作为比较,剥离后的二进制文件大小约为 170MB,.rodata 部分大小为 016a2225(~22.6M),.text 部分占用 06ad7511(~106.8M)。
移除所有错误堆栈需要的 Location 信息,可以将 .rodata 大小减少到 0169b225(仍约 22.6M,变化非常小)大小仍是约 170MB。而移除所有 #[snafu(display)] 可以将 .rodata 大小减少到 01690225(~22.5M)并将整体二进制文件大小减少了 0.1MB。
在这篇文章中,我们展示了如何实现 stack_trace_debug[13] 过程宏。通过使用 stack_trace_debug,我们可以组装出一个低开销但功能强大的错误堆栈。此外,我们还可以方便地遍历错误链,从而使用不同的方案为不同的目的呈现错误。
这个宏目前只在 GreptimeDB 中采用,我们正在尝试将它重构得更通用,以适用于不同项目的用例。如果生态能够广泛采用这个模式,那么不同库之间可以级联的打印虚拟用户堆栈,整个错误处理的体验会更好。
此外,最新版本的标准库为 std::error::Error 定义了一个暂不稳定的 API provide[21] 来获取结构中的字段。我们或许可以在重构堆栈跟踪工具利用这个 API 来简化编码。
Reference:
[1] https://docs.rs/thiserror/latest/thiserror/
[2] https://docs.rs/anyhow/latest/anyhow/
[3] https://docs.rs/snafu/latest/snafu/
[4] https://doc.rust-lang.org/std/convert/trait.From.html
[5] https://github.com/delta-incubator/delta-kernel-rs/pull/151
[6] https://github.com/GreptimeTeam/greptimedb/pull/1261
[7] https://github.com/GreptimeTeam/greptimedb/pull/1273
[8] https://doc.rust-lang.org/std/fmt/trait.Display.html
[9] https://doc.rust-lang.org/std/macro.file.html
[10] https://doc.rust-lang.org/std/macro.line.html
[11] https://doc.rust-lang.org/std/macro.column.html
[12] https://docs.rs/snafu/0.8.2/snafu/struct.Location.html
[13] https://greptimedb.rs/common_macro/attr.stack_trace_debug.html
[14] https://greptimedb.rs/common_error/ext/trait.StackError.html
[15] https://greptimedb.rs/common_error/ext/trait.StackError.html
[16] https://doc.rust-lang.org/std/fmt/trait.Debug.html
[17] https://greptimedb.rs/common_error/ext/trait.ErrorExt.html
[18] https://greptimedb.rs/common_error/ext/trait.StackError.html#tymethod.next
[19] https://greptimedb.rs/common_error/ext/trait.StackError.html#tymethod.debug_fmt
[20] https://greptimedb.rs/common_error/ext/trait.StackError.html#method.last
[21] https://doc.rust-lang.org/std/error/trait.Error.html#method.provide
关于 Greptime
Greptime 格睿科技专注于为物联网(如智慧能源、智能汽车等)及可观测等产生大量时序数据的领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前主要有以下三款产品:
GreptimeDB 是一款用 Rust 语言编写的开源时序数据库,具有云原生、无限水平扩展、高性能和融合分析等特点,帮助企业实时读写、处理和分析时序数据的同时,降低长期存储的成本。我们提供 GreptimeDB 企业版,支持更多企业特性和定制化服务,如有需要欢迎联系我们:15310923206(同微信)。
GreptimeCloud 是一款全托管的云上数据库即服务(DBaaS)解决方案,基于开源时序数据库 GreptimeDB 打造,能够高效支持可观测、物联网、金融等领域的应用。用户可以通过内置的可观测性解决方案 GreptimeAI 全面掌握 LLM 应用的成本、性能、流量和安全等情况。
车云一体解决方案 是一款深入车企实际业务场景的时序数据库解决方案,解决了企业车辆数据呈几何倍数增长后的实际业务痛点。多模态车端数据库结合云端 GreptimeDB 企业版帮助车企极大降低流量、计算和存储成本,并帮助提升数据实时性和业务洞察能力。

Star us on GitHub Now:
https://github.com/GreptimeTeam/greptimedb
官网:https://greptime.cn/
文档:https://docs.greptime.cn/
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime/
往期精彩文章:



👇 点击下方阅读原文,立即体验 GreptimeDB!
