





2023 年,我们一共发布了 132 篇文章,其中包括了 69 篇原创技术文章。
微信公众号每天的推送是不是让你看得眼花缭乱?
是不是因此错过了一些关于 Greptime 的消息?
或者你是不是刚开始关注和认识数据库这类信息呢?
没关系,课代表帮你抄好作业啦!(看下面👇)
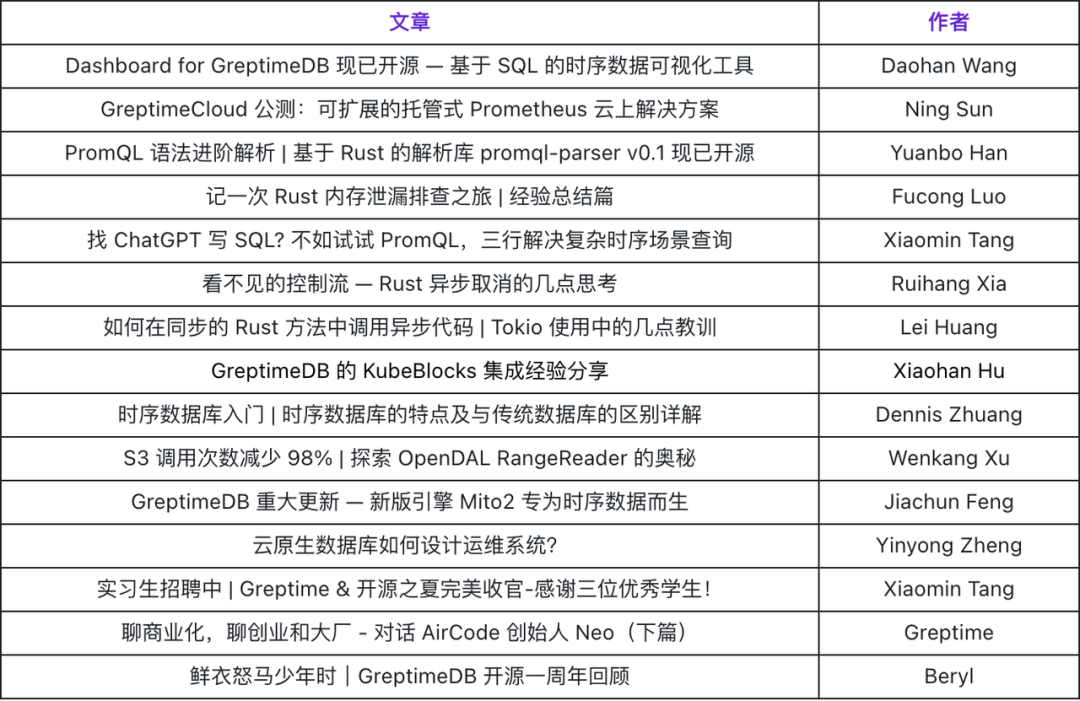
根据对读者的历史阅读浏览量统计,我们整理出了一份「Greptime 年度好文清单」,一起来回顾一下 2023 年 Greptime 文章高阅读量 TOP 15 榜单(官网还有英文榜单哦,喜欢英语技术文章的朋友不要错过哦),挑选你喜欢 or 你感兴趣的文章阅读吧~

01
随着近年来智能汽车以及 IoT 设备的发展,时序数据的采集变得更为普遍,但是如何展示和使用这些数据,还有很大的探索空间。业务方可能会有自己的数据仓库或者其他终端来展示和使用数据,不过也有相当一部分数据库的用户,并不擅长开发前端界面。我们作为数据库的开发者,理应提供一个开箱即用的控制台,让数据的价值更好地发挥出来。
在这次发布中,我们为之前依赖开源 Prometheus 进行应用监控和分析的用户,引入了一种托管式 Prometheus 解决方案。此外,我们也对 GreptimeCloud 服务的不同层级进行了增强,使其能够适应更多元的场景,从而满足更广大的用户需求。
我们在其他推文中简单介绍了 PromQL 的基本概念, 通过几个例子展示了 PromQL 和 SQL 的主要差别,推荐初学者先读一下上文,对 PromQL 有个大概的了解。本文会更深入地谈一谈 PromQL 是如何处理和计算数据的。
大型项目几乎不可能只通过看代码就能找到内存泄漏的地方,所以我们首先要对程序的内存用量做统计分析。幸运的是,GreptimeDB 使用的 jemalloc 自带 heap profiling,我们也支持了导出 jemalloc 的 profile dump 文件。于是我们在 GreptimeDB 的 Frontend 节点内存达到 300MB 和 800MB 时,分别 dump 出了其内存 profile 文件,再用 jemalloc 自带的 jeprof 分析两者内存差异(--base 参数),最后用火焰图显示出来。
可能大家都听过 Kubernetes,Borg 可以说是 K8s 的前身,所以 Borg 对应了 Kubernetes, Borgmon 对应了 Prometheus,而 PromQL 就起源于当年的 Borgmon 查询语言,现在看来 PromQL 从出生就带上来云原生可观测的基因。
我们首先描述一个简化的场景:在一个长时间运行的测试中存在元信息损坏的问题,有一个应该单调递增的序列号出现了重复。序列号的更新逻辑非常简单:从一个原子变量中读取当前值,然后通过异步 I/O 方法 persist_number() 将新值写入文件里,最后更新这个原子变量。整个流程都是串行化的(file 是一个独占引用)。
在做 GreptimeDB 项目的时候,我们遇到一个关于在同步 Rust 方法中调用异步代码的问题。经过一系列故障排查后,我们弄清了问题的原委,这大大加深了对异步 Rust 的理解,希望能给被相似问题困扰的 Rust 开发者一些启发。我们的整个项目是基于 Tokio 这个异步 Rust runtime 的,它将协作式的任务运行和调度方便地封装在 .await 调用中,非常简洁优雅。但是这样也让不熟悉 Tokio 底层原理的用户一不小心就掉入到坑里。
现如今,构建数据基础设施在 K8s 上变得越来越流行,这其中最棘手的障碍莫过于:与云提供商集成的困难、缺乏可靠的 Operators 以及陡峭的 K8s 学习曲线。KubeBlocks 提供了一个开源选择,既可以帮助应用开发者和平台工程师为各种数据基础设施配置更多丰富的功能与服务,又可以帮助非 K8s 专业人士快速地搭建全栈、生产级的数据基础设施。GreptimeDB 集成 KubeBlocks,不仅获得了更加方便、快捷的集群部署方式,而且还可以享受到 KubeBlocks 提供的扩缩容、监控、备份与恢复等强大的集群管理能力。
在过去的几年里,物联网(IoT)的日益普及和对实时数据的需求导致时序数据库(TSDB)的采用量大幅增长。根据 DB-Engines 的排名,TSDB 的普及率超过了其他任何类型的数据库,仅次于 Graph DBMS。
从 v0.3 到 v0.4,Greptime 团队主要项目中,共有来自 6 个国家和地区的 42 位贡献者,累计合并了 726 个 PRs,涉及到 7659 个文件修改,包含了 271 个功能优化,163 个修复,107 个重构以及大量测试。另外,我们还发布了 C++, Erlang 和 JS SDK, 官方目前已经支持了 Golang/Java/Rust/C++/Erlang/JS 6 种语言。社区方面,我们也迎来了一位新的 Committer: Niwaka。
greptimedb-operator 项目的成熟度依赖于我们对 GreptimeDB 运维经验的不断积累和总结。我们只有在更多真实的场景中运维 GreptimeDB 集群,才能够持续不断地将运维经验沉淀成代码融入 greptimedb-operator 中。因此,greptimedb-operator 未来的开发重点将聚焦于功能的完善和整体质量的提升,持续基于 GreptimeDB 的最新特性来丰富 greptimedb-operator 的能力。
GreptimeDB 作为开源之夏的首次参与者,收获颇丰,我们的三个项目均圆满结项。每一个项目不仅是技术的挑战,更是团队合作与个人成长的见证。项目中的参与者逐渐作为实习生转化为团队的新鲜血液,我们希望通过开源之夏&Greptime 的项目平台帮助同学完成从校园理论到社会实践的平稳过渡,希望他们不仅学习开源文化,还能了解开源社区的运作方式。
前端工程师是一个非常活跃,同时充满创造性的群体。如何既能让 JS 工程师发挥这个创造性的特长,同时又不必操心运行环境与服务器配置,做到所写即所得,所得即所需?他们需要这样一个平台,可以直接提供函数运行环境、数据库和文件存储,以及在线的编辑、日常的运维。这就是 AirCode.io。
很难想象没有开源的世界会是什么样子,非要举个例子的话,就好比菜谱不再公开,那所有人都只能自研,说不好连麻婆豆腐都需要远赴蜀地才能品上一品。正因为开源,我们得以共享珍贵的的食谱,所以也愿意将自研的食谱无私贡献出去。
2023 年,我们不断更迭技术的版本,输出优质的内容,拉近与社区的距离;而我们也会把这份初心带入 2024 年,希望文字继续传递我们对技术的热忱和对社区的友好。
如果你也对 GreptimeDB 感兴趣,欢迎在 GitHub 上 Star 我们(点击 阅读原文 迅速跳转)。如有任何关于技术和社区的想法、建议和分享,欢迎通过微信小助手联系我们(下方贴心附上二维码 ❤️),一起共创美好技术社区。

关于 Greptime
Greptime 格睿科技于 2022 年创立,目前正在完善和打造时序数据库GreptimeDB,格睿云 GreptimeCloud 和可观测工具 GreptimeAI 这三款产品。
GreptimeDB 是一款用 Rust 语言编写的时序数据库,具有分布式、开源、云原生、兼容性强等特点,帮助企业实时读写、处理和分析时序数据的同时,降低长期存储的成本。
GreptimeCloud 基于开源的 GreptimeDB,为用户提供全托管的 DBaaS,能够与可观测性、物联网等领域结合的应用产品结合。利用云提供软件和服务,可以达到快速的自助开通和交付,标准化的运维支持,和更好的资源弹性。
GreptimeAI 是为 LLM 应用量身定制的可观测性解决方案,开发者可以通过该方案全面、深入地了解应用的成本、性能、流量和安全情况,在保证低成本和高性能的同时提供高效可靠的分析能力,同时保留了时序数据库的灵活性。
GreptimeCloud 已正式公测,欢迎关注公众号或官网了解最新动态!
官网:https://greptime.cn/
GitHub: https://github.com/GreptimeTeam/greptimedb
文档:https://docs.greptime.cn/
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime/
往期精彩文章:



GreptimeDB 提供 Enterprise 企业版服务,如有需要请联系 info@greptime.com 或添加小助手微信(微信号:greptime).
👇 点击下方阅读原文,立即体验 GreptimeDB!
