




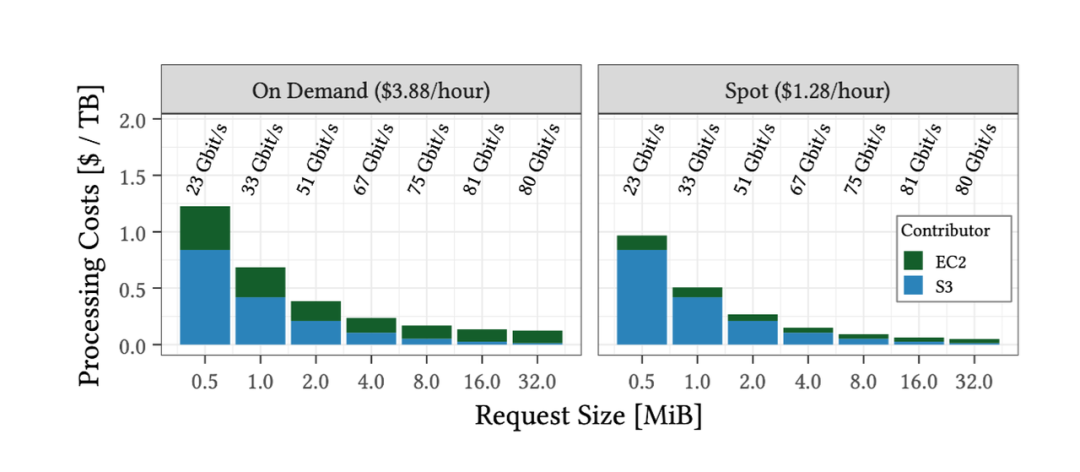
AWS S3 每 TB 存储成本为 23 美元每月,同时可以实现 11 个 9 的可用性。需要注意的是,最终费用还取决于调用的 API 次数以及跨 Region 的流量费用; 访问 S3 的带宽可达到 200 Gbps,这取决于实例的带宽。在原文的 Introduce section 中为 100 Gbps,但后文提到在 AWS C7 系列机型上,这一带宽可以跑满 200 Gbps。
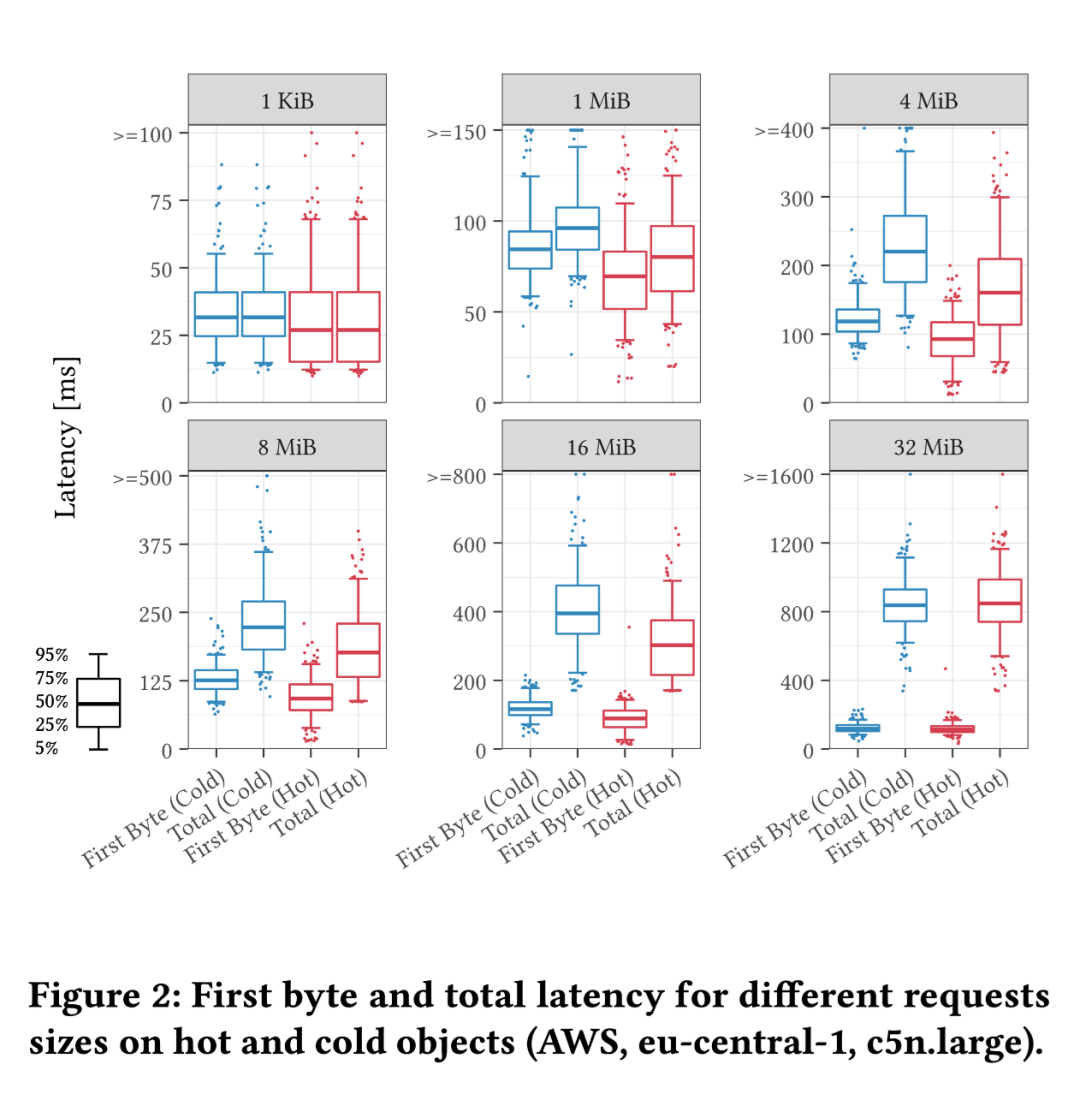
在小请求中,首字节延迟(First byte latency)是决定性的影响因素; 对于大请求,从 8 MiB 到 32 MiB 的实验显示,延迟随着文件大小呈线性增长,最终达到了单个请求的带宽限制; 在热数据方面,我们使用第一次请求和第二十次请求分别代表请求冷热数据的场景。在请求热数据的情境中,延迟通常更低。
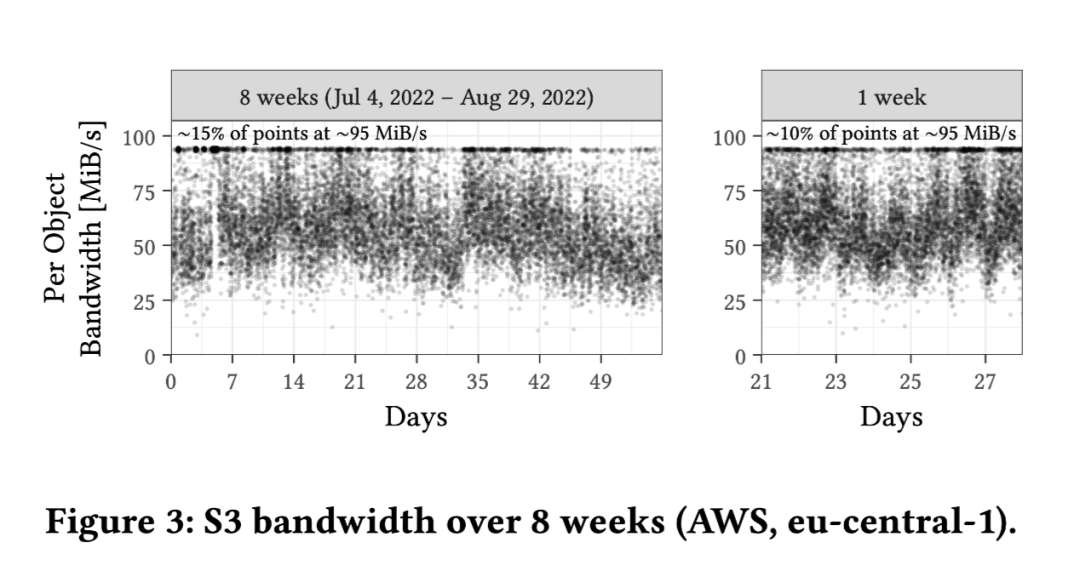
对象带宽存在较大的变化,范围从约 25 到 95 MiB/s 不等。 有相当数量的数据点(15%)位于最大值(~95 MiB/s) 中位数性能稳定在 55-60 MiB/s。 周末性能较高
2.1.2 不同云厂家的延迟
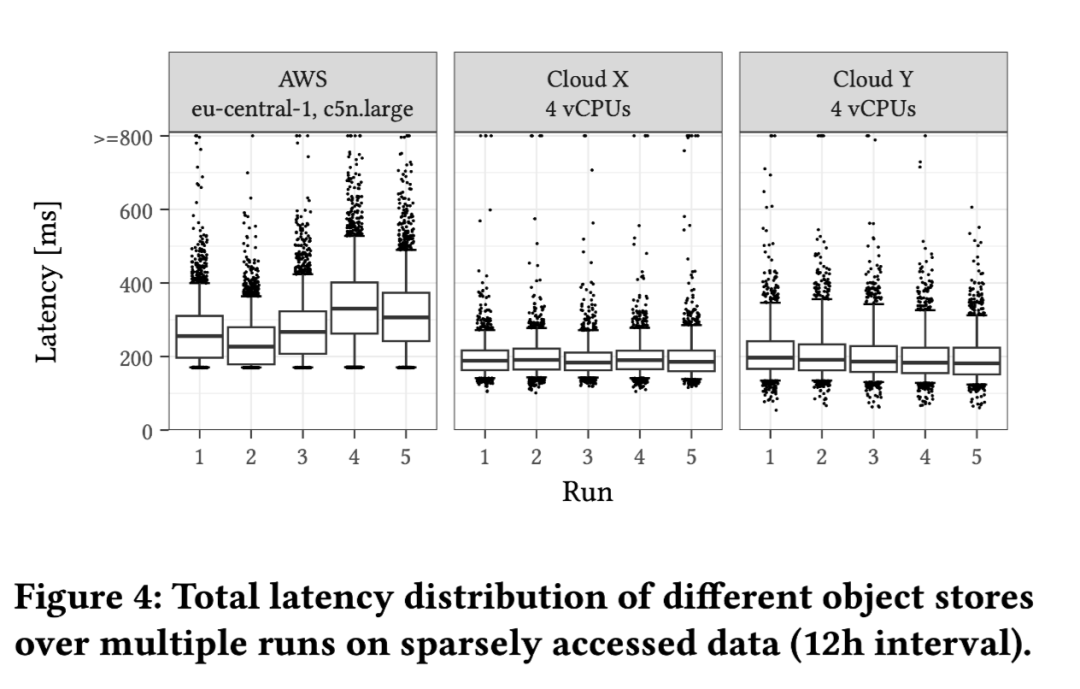
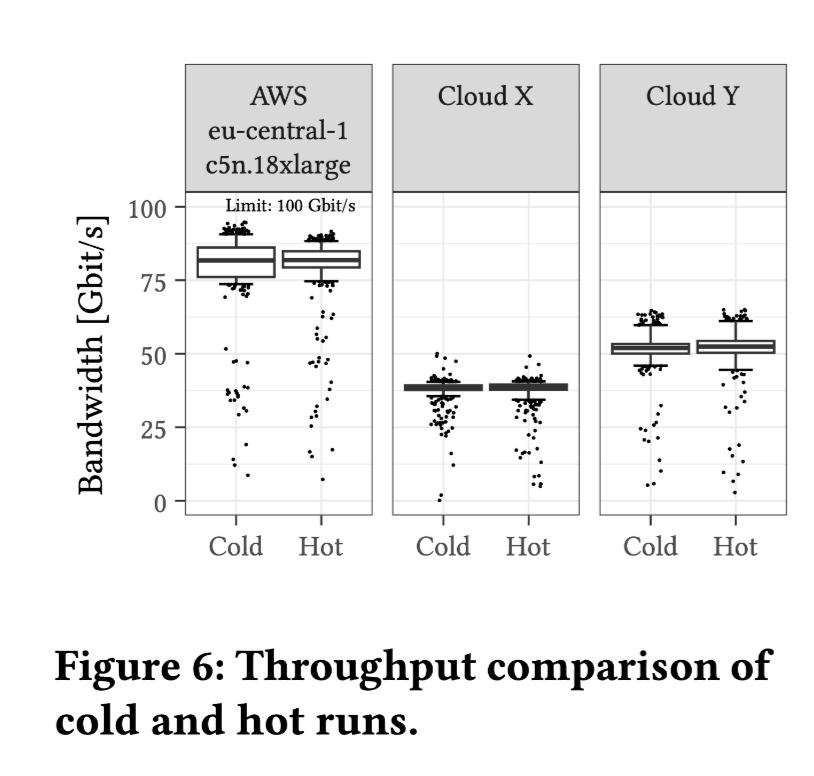
单个文件 16 MiB,256 个并行请求,达到最大吞吐量(100 Gbps) 随地域(Region)波动 AWS 75 Gbps (以下均为中位数) Cloud X 40Gbps Cloud Y 50Gbps 冷热数据差别不大
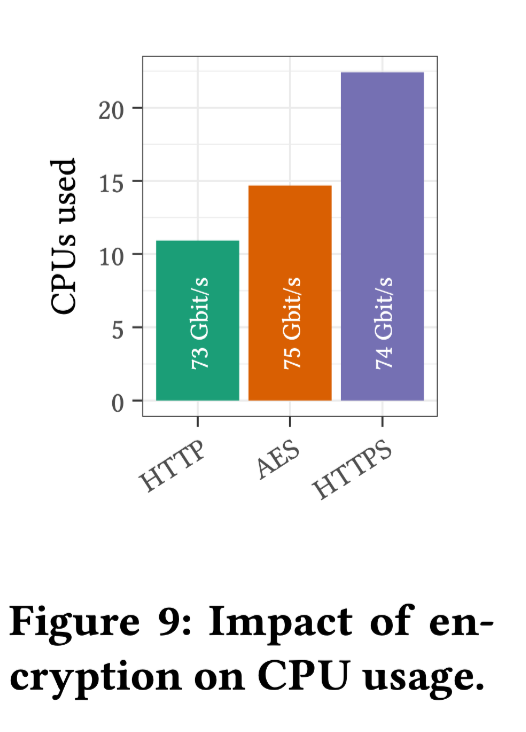
HTTPS 需要 HTTP 2 倍 CPU 资源 AES 只需要增加 30% CPU 资源
在 AWS,所有区域之间的流量,甚至在可用区之间的所有流量都由网络基础设施自动加密。在同一个位置(Location)内,由于 VPC 的隔离,没有其他用户能够拦截 EC2 实例和 S3 网关之间的流量,因此使用 HTTPS 是多余的。
在经过 600 毫秒后,只有不到 5% 的对象尚未被成功下载; 第一个字节的延迟超过 200 毫秒的对象也不到 5%。
基于上述经验值,可以考虑对那些超过一定延迟阈值的请求进行重新下载的尝试。
在研究中,作者注意到单个请求的带宽类似于访问 HDD 上的数据。为了充分利用网络带宽,需要大量并发请求。对于分析型工作负载而言,8-16 MiB 范围内的请求是具有成本效益的。他们设计了一个模型,用于预测达到给定吞吐目标所需的请求数量。
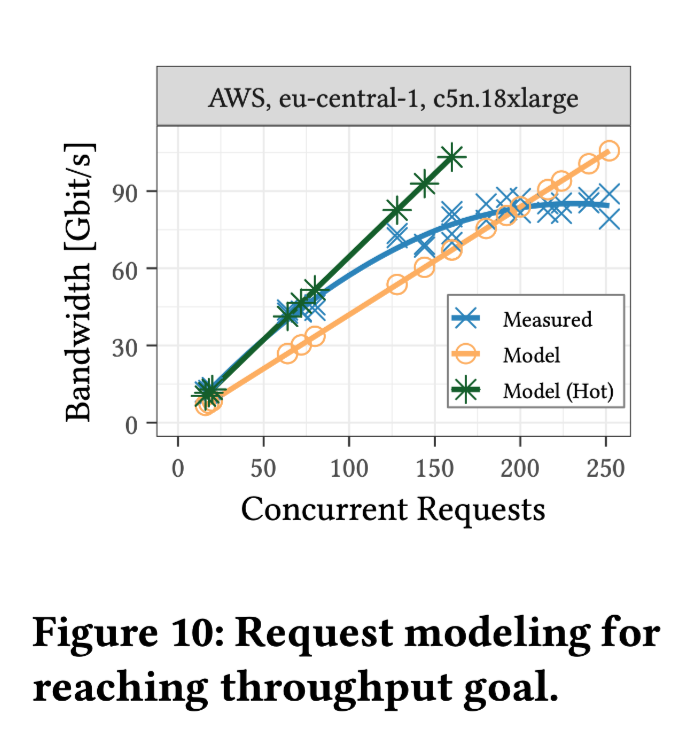
实验使用的计算实例(Instance)总带宽:100 Gbps,图中 Model(Hot)为之前实验中 25 分位(p25)延迟。
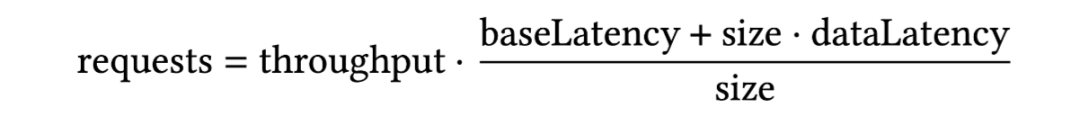
baseLatency 的中位数约为 30 ms (Figure 2:1 KiB 试验得出);
dataLatency 的中位数约为 20 ms/MiB,Cloud X 和 Cloud Y 更低 (12–15 ms/MiB) (Figure 2:16 MiB 中位数 - 基本延迟);
S3 跑满 100 Gbps 需要 200-250 个并发请求;
数十几毫秒的访问延迟和单个对象的带宽约为 50 MiB/s,对象存储应该是基于 HDD 的(意味着以 ∼80 Gbps 从 S3 读取相当于同时访问约 100 个 HDD)。
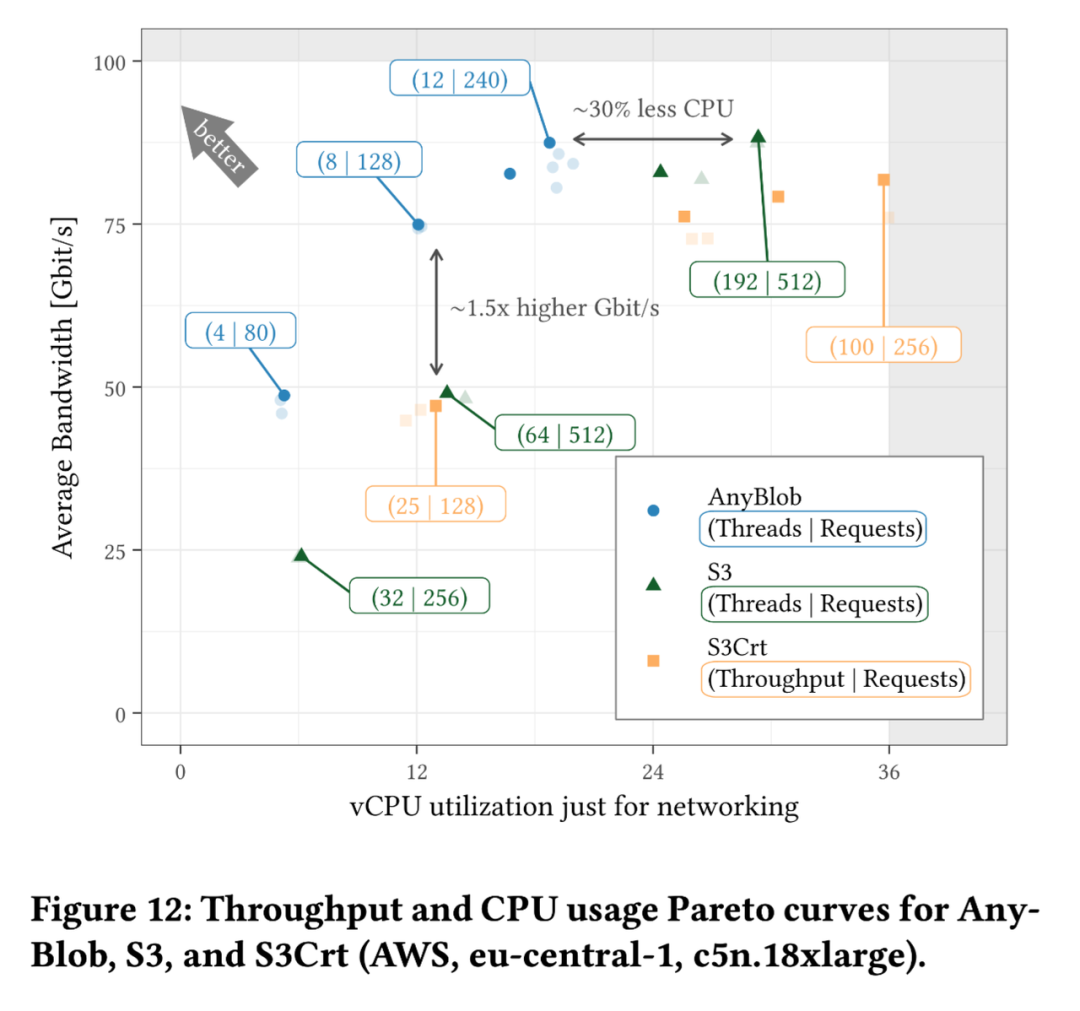
1. 缓存多个 Endpoint 的 IPs:将多个 Endpoint 的 IP 地址缓存,并通过调度请求到这些 IPs,基于统计信息更换那些性能明显下降的端点。
3. MTU 发现策略:通过对目标节点 IP 进行 ping,并设置 Payload 数据大于 1500 字节且 DNF(do not fragment),以确定是否支持更大的 MTU。

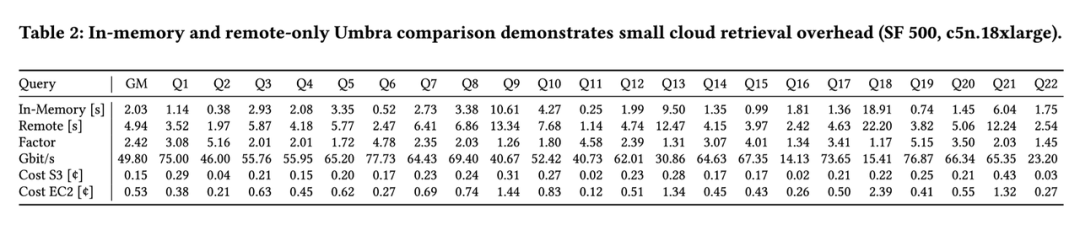
2. 计算密集型的代表:Q 9, 18,其特点是 In-Memory 和 Remote 之间的性能差异非常小。
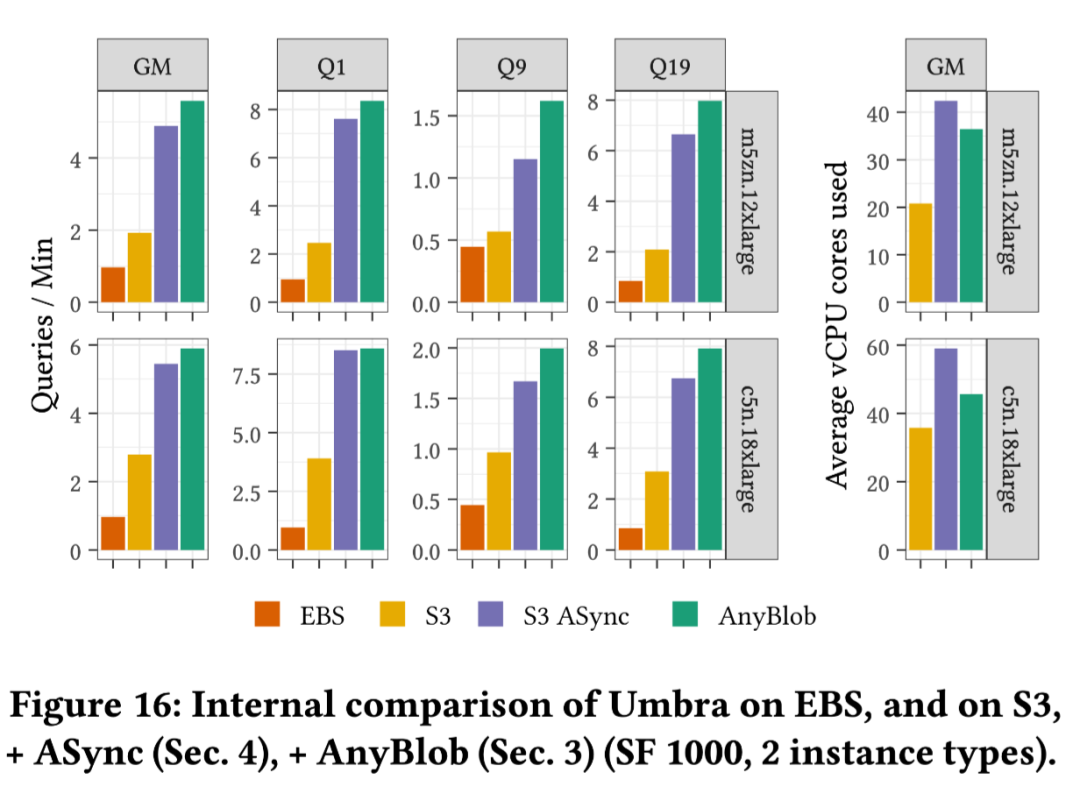
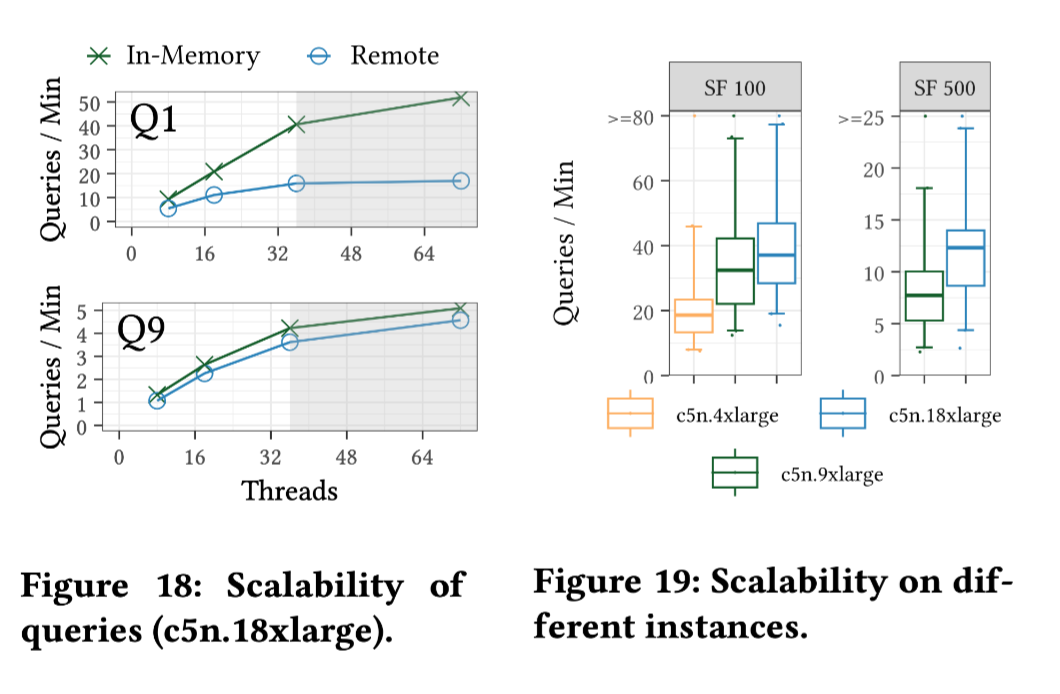
2. 计算密集型(Q9),性能随着核心数量的增加而提高,远程 Umbra 版本的吞吐量几乎与内存版本相同。
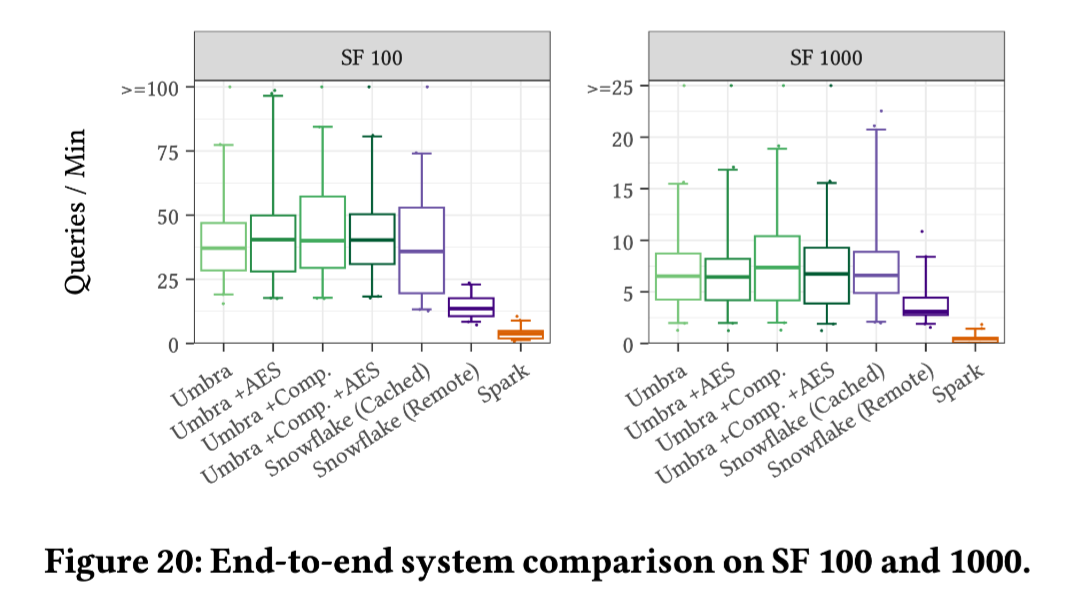
实验参数:比例因子(SF)为 100(∼100 GiB)和 1,000(∼1 TiB 的数据)
实验中用到的 Snowflake 为 large size,而 Umbra 使用了 EC2 的 c5d.18xlarge 实例,并且没有启用缓存。
总的来说,这个对比可能存在一些不够严谨的地方,比如没有提供 Snowflake 组更多的信息:
对于 L size Snowflake,可能存在超售限流的情况;
Snowflake 组购买的可能是 Standard 丐版,这也可能影响实验结果。
不过另一个侧面也说明了:Benchmark marketing 的核心技术可能是统计学魔法 🧙(把没有击中缓存的那次查询藏到 p99 之后)。换句话说,单个查询跑 10 遍和跑 100 遍的 Benchmarking 优化工作量或许不在一个数量级🥹。
https://instances.vantage.sh/aws/ec2/c5d.18xlarge
https://www.snowflake.com/legal-files/CreditConsumptionTable.pdf
对象存储的一些特征 最佳文件大小 是否开启 HTTPS 云存储数据请求模型 基于统计信息调度查询和下载线程和任务 慢请求的经验值 MTU 巨型帧
在即将推出的下一个版本 GreptimeDB 0.7.0 中,我们对查询进行了大量的优化,其中也包括了在对象存储上的查询优化。在部分场景下,查询耗时已经接近于本地存储的水平。敬请期待试用,并欢迎提出任何形式的建议和讨论。

关于 Greptime



