




Procedure 是 GreptimeDB 最近正在开发中的一个新特性,通过引入 Procedure 框架,来帮助记录数据库中多步操作的进度以及对该操作自动进行失败重试,保证其能执行完成。
这篇文章将简单介绍下 Procedure 框架是什么,以及我们实现 Procedure 的方式和未来规划。
为什么需要 Procedure

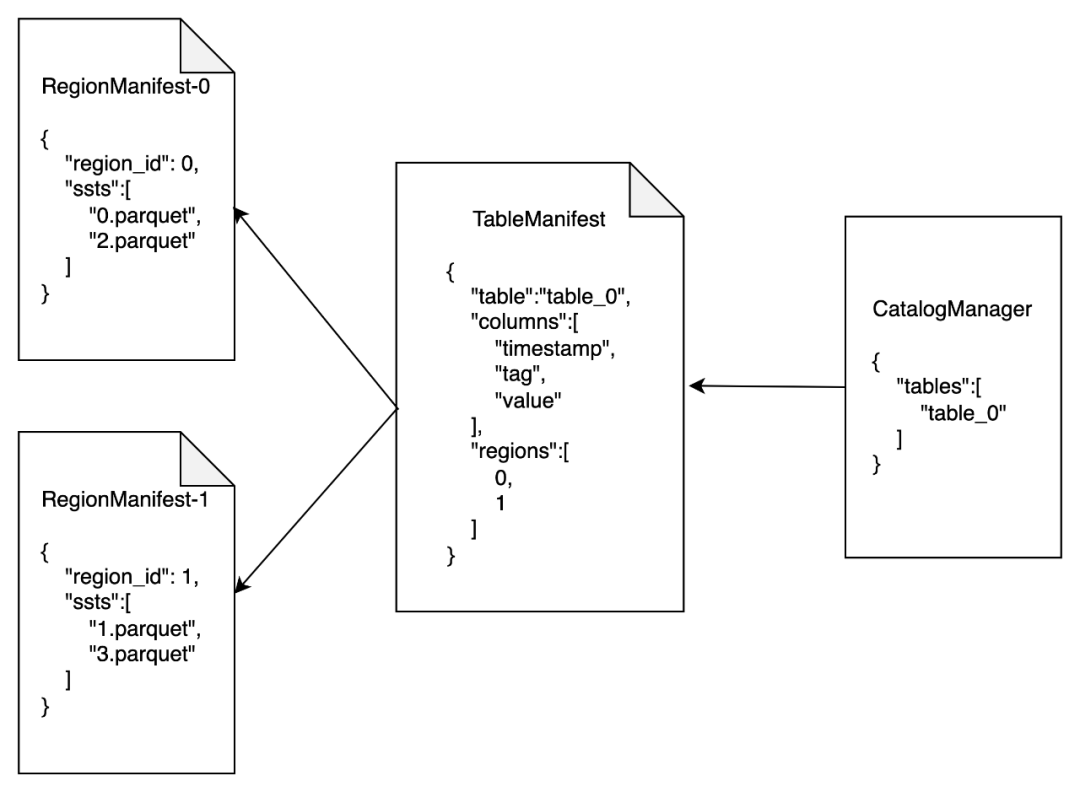
Region。我们使用以下组件记录系统中存在的表和每个表的元数据
CatalogManager负责记录系统中存在的所有表
TableManifest负责记录表的元数据,包括表结构,一张表有多少个
Region等信息
RegionManifest负责记录
Region的元数据,如
Region的结构,包含的数据文件等
CREATE TABLE为例:建表的时候,数据库需要先后执行以下动作
为每个
Region
创建RegionManifest
并持久化Region
的元数据创建
TableManifest
并写入表的元数据往
CatalogManager
中写入表的记录
TableManifest中已经写入了表的元数据,但是
CatalogManager中却没有关于这张表的记录。当然,实际上还存在其他比建表更复杂的情况,比如
DROP TABLE。
Procedure 框架
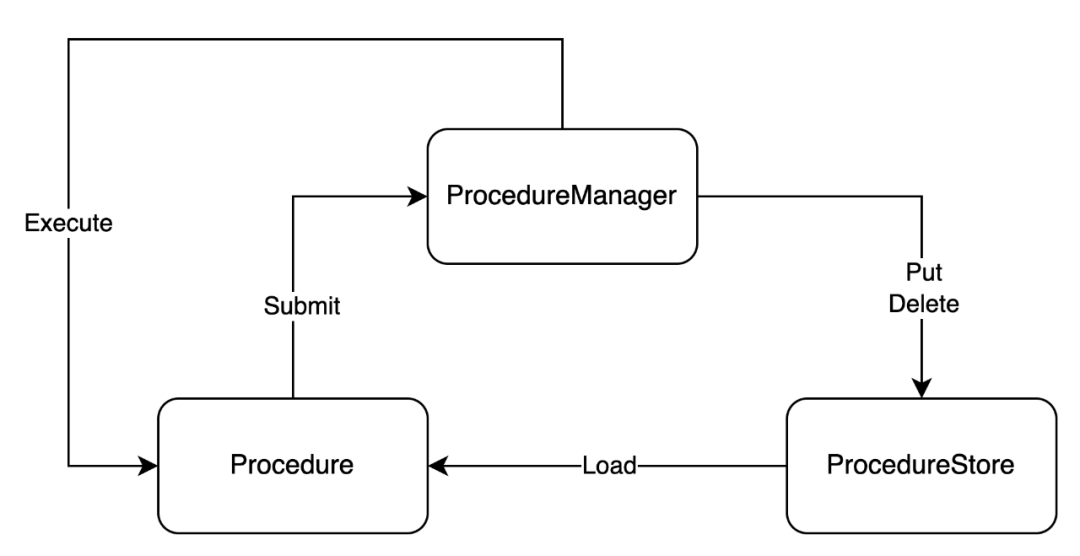
Procedure
ProcedureId标识自身
ProcedureStore
/procedures/{PROCEDURE_ID}_000001.step
/procedures/{PROCEDURE_ID}_000002.step
/procedures/{PROCEDURE_ID}_000003.commit
ProcedureManager
解决建表遇到的问题
Region,创建表,将表注册到
CatalogManager。在每一步里,我们需要注意实现的幂等性。例如如果
Region已经创建好了则无需重复创建。
ProcedureId就是这个菜品的流水号
后续工作
ALTER TABLE和
DROP TABLE等
总结
参考
[2]https://accumulo.apache.org/1.8/accumulo_user_manual.html#_fault_tolerant_executor_fate
[3]https://github.com/GreptimeTeam/greptimedb/blob/0ffa628c22fa1a34e244b33afd6fe85585b8824a/docs/rfcs/2023-01-03-procedure-framework.md
[4]https://github.com/GreptimeTeam/greptimedb/issues/286
[5]https://github.com/GreptimeTeam/greptimedb/pull/836
[6]https://developer.mozilla.org/zh-CN/docs/Glossary/Idempotent
[7]https://docs.greptime.com/developer-guide/meta/overview

关于 Greptime
文章转载自GreptimeDB,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
