




现如今,各行各业的发展都离不开数据,企业对数据库的要求也越来越高。一个理想的高性能数据库需同时满足海量读写需求,拥有强大的分析能力,还要能低成本存储历史数据。在业务中,人们还希望能够低门槛迁移,无缝扩展。
而目前的数据库远未能支持从用户手里大量的数据中挖掘足够多的价值。虽然这样的产品很难得,但不是没有。
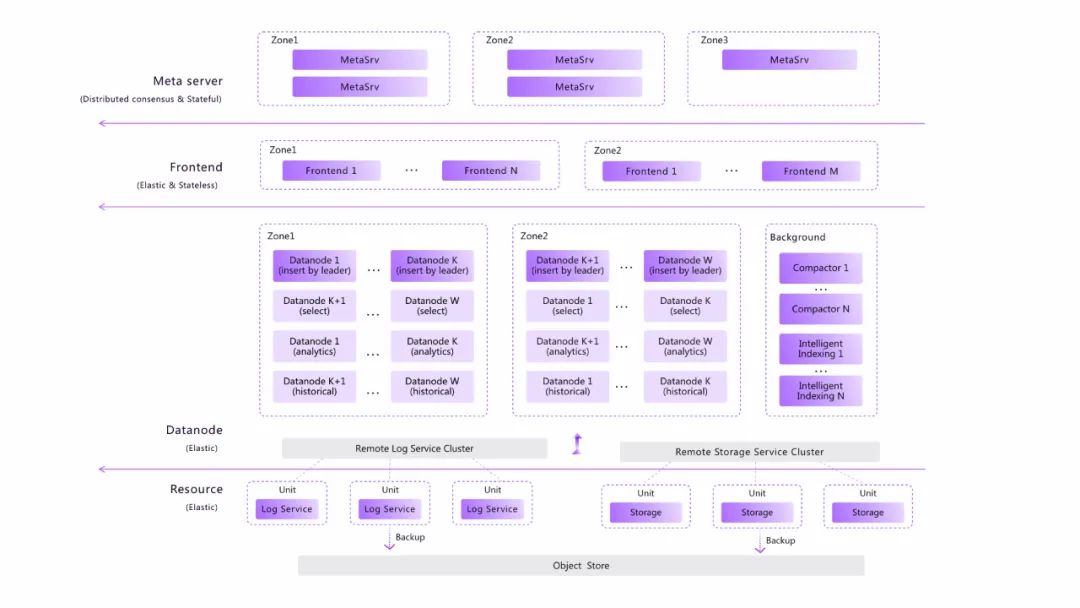
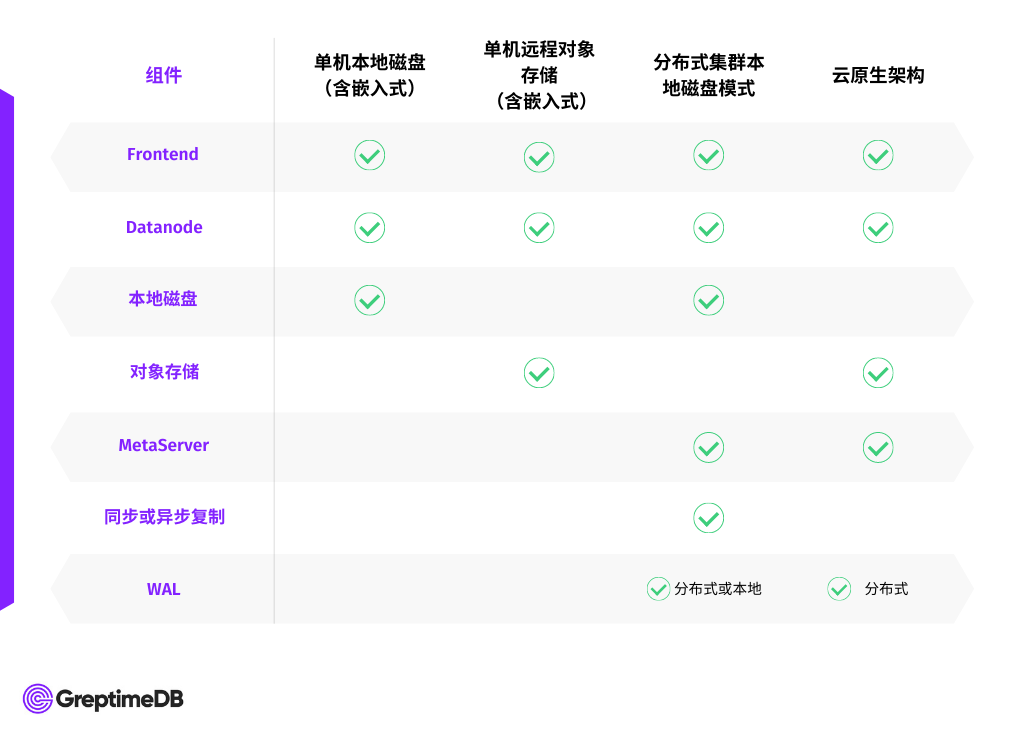
系统概览
CREATE TABLE system_metric {host_or_ip STRING NOT NULL,idc STRING default 'idc0',cpu_util DOUBLE,memory DOUBLE,disk_util DOUBLE,load DOUBLE,ts TIMESTAMP NOT NULL,TIME INDEX(ts),PRIMARY KEY(host_or_ip, idc),};
host_or_ip是采集的单机的 hostname 或者 IP 地址,
idc 列是该机所在的机房,
cpu_util、
memory、
disk_util和
load就是采集的单机指标,
ts是采集的时刻(Unix 时间戳)。这些都跟大家熟悉的表模型非常类似,比较特别的是
TIME INDEX(ts)这个约束,它是用来指定这张表的时间索引列为
ts列。
表名:通常也是指标名,比如这里的
system_metric
。时间索引列:必备项,通过
time index
约束指定,一般用来表示这行数据的产生时间,如例子中的ts
列。指标列(Metric Column):采集的数据指标,一般随时间而变化,比如例子中的
cpu_util
、memory
等 4 个数值列。指标一般是数值,但是也可能是其他类型的数据,比如字符串、地理位置等。GreptimeDB 是一个多值模型(一行数据可以有个多个指标列),而不是类似 OpenTSDB 或者 Prometheus 这样的单值模型。标签列(Tag Column):采集指标上附带的标签,比如例子中的 host_or_ip
和idc
列,一般是对这些指标的某个特征的描述。
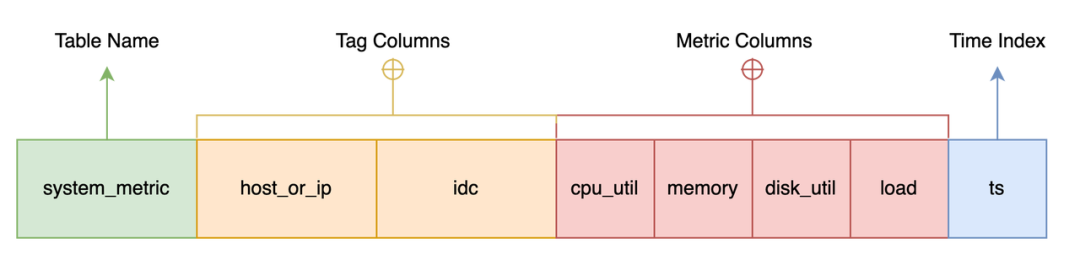
greptime_value列)。

文章转载自GreptimeDB,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
