





王健
YMatrix 售前负责人

逐渐成熟的中国数仓市场
在谈到中国数仓的发展时,我们必须提到一些关键企业,它们在技术引入和推广方面扮演了至关重要的角色,推动了整个行业的迅速成长。中国数仓市场最早由 Teradata 推动,1997年 Teradata 进入中国市场,迅速占据了中国金融市场约 50% 的份额。它凭借其强大的技术实力和市场经验,在中国市场取得了显著的成功。2014年,Teradata 在中国区的营收达到了 27 亿美元,展示了其在数据仓库领域的巨大影响力。然而,由于本地化支持不足、国产化浪潮的兴起以及技术创新停滞,Teradata 在 2023 年退出了中国市场。这一退出标志着一个时代的结束,同时也为本土数据仓库解决方案提供了发展的契机。


下一代数仓是什么
目前,数仓方案主要分为两种:传统 Hadoop 方案和基于 Greenplum 方案。
一、传统的数仓方案
Hadoop 方案
Hadoop 方案由多个组件组成,每个组件对应特定的功能模块。例如:
HDFS(Hadoop 分布式文件系统):用于存储文件,类似于存储系统。
Hive:将文件转换为表,通过 SQL 查询和展示结果。
Spark:进行批处理,生成 DWD(数据仓库详细层)或 DIS(数据集成服务)。
Flink:用于实时数据链路展示和分析。
HBase:进行高频数据检查。
MySQL/PG:用于实时报表展示。
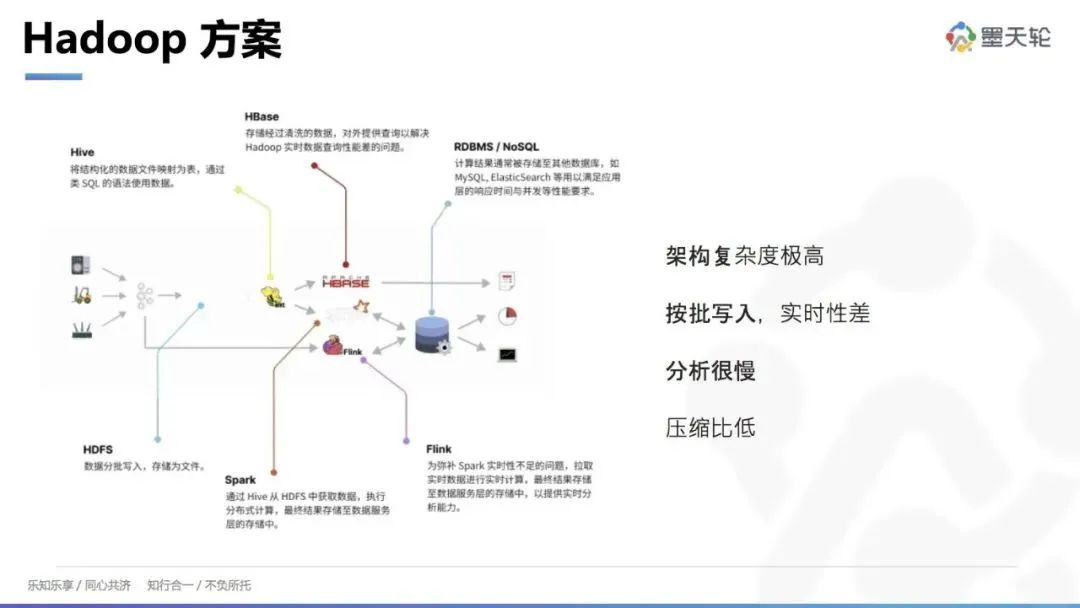
图2 传统 Hadoop 方案
这种方案的问题在于架构复杂、数据链路长,每个环节如果出现问题都会影响上下游,变更和调整也会带来很大的影响。此外,Hadoop 方案主要按批次写入,尽管引入 Flink 可以实现实时写入,但整体架构依然复杂,查询性能不佳,数据存储压缩比低。
基于 Greenplum 方案
Greenplum 方案更多地利用云端关系数据库数据,通过定期(如T+1)将数据抽取过来,进行扩围、聚集和清洗,然后将数据导入 MySQL 或 PG 中进行数据展示。这种方案支持 T+1 的分析,适应了对数据时效性要求越来越高的需求。数据的新鲜度决定了其价值,用户更关注当前数据而非历史数据。
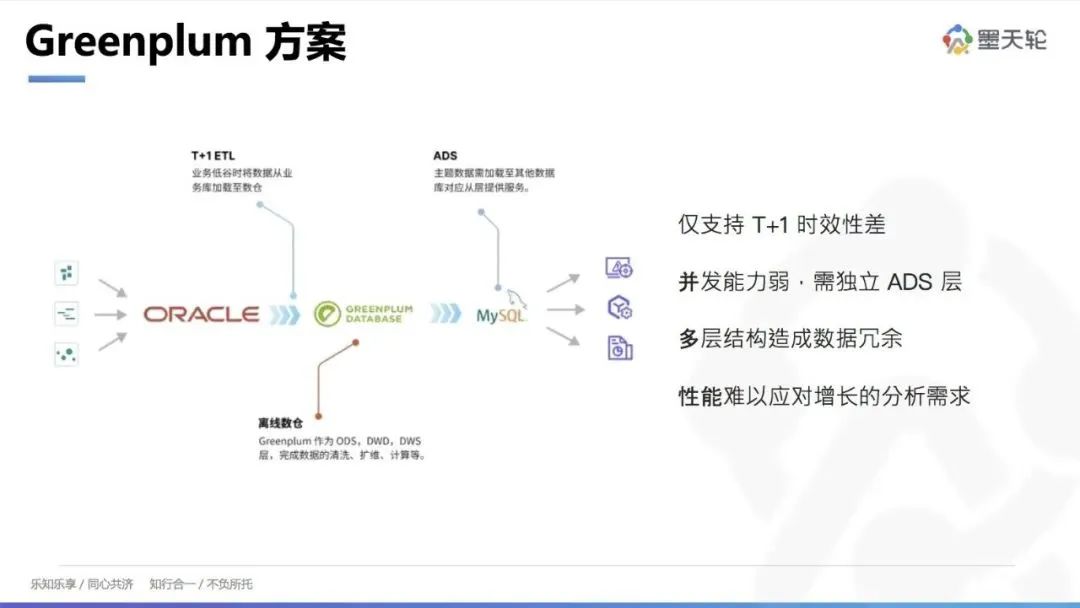
图3 基于 Greenplum 方案
Greenplum 方案的不足在于并发能力较弱,更新和删除操作效率低,需要独立的 ADS 服务来进行数据报告展示。此外,多层架构导致数据冗余,扩容不友好,需要停机,不利于应对大规模数据增长需求。
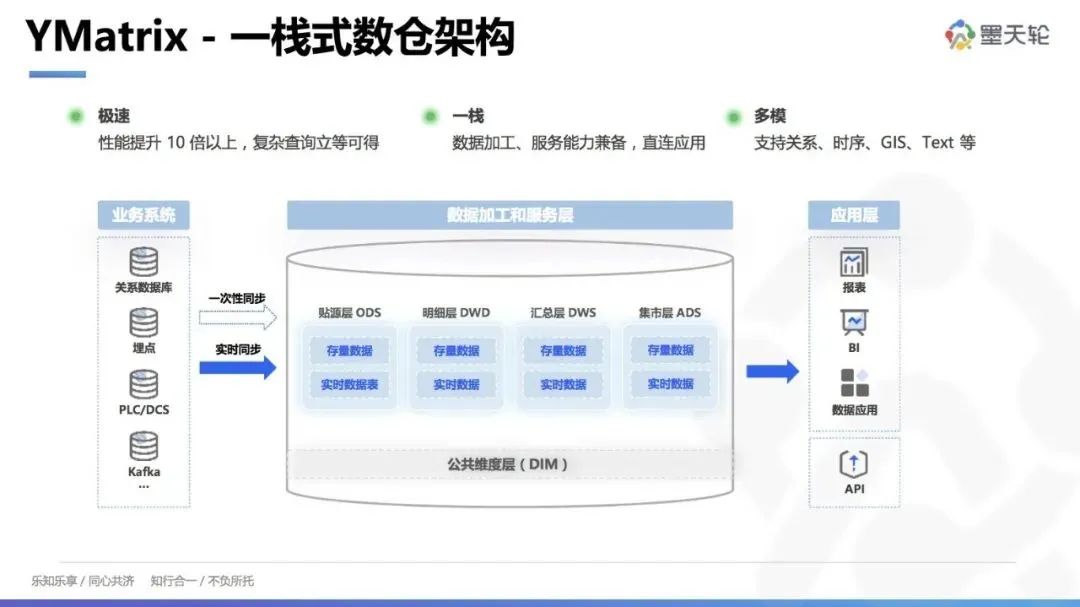
二、一栈式数仓架构
因此,下一代数仓需要适应现代数据处理的复杂环境和多样化需求,推动企业在数据时代的快速发展。YMatrix 的一栈式数据仓库架构具有多项功能和优化,提供了显著的性能提升和稳定的扩展性。
在数据加工方面,YMatrix 与 Greenplum(GP)完全兼容,并在向量化处理和行业标准方面进行了多项优化,大幅提升了整体性能。对于复杂计算任务,我们通过 PR Python 在库内进行机器学习分析,显著提高了数据处理和分析的效率。YMatrix 架构具有良好的并发处理能力,在单表查询或 TPCP 测试中,它的性能可以达到单机 PostgreSQL 的水平,保持高并发情况下的稳定性能。我们的一栈式架构支持不停机扩容,所有数据节点能够自动故障切换,解决了 Greenplum 无法自动切换的问题,提升了系统的高可用性和稳定性。
三、 MatrixGate 数据高速实时入仓
在现代数据仓库架构中,高速实时入仓能力至关重要。YMatrix 一栈式数据仓库架构通过创新的组件和技术,实现了高效的数据写入和处理。
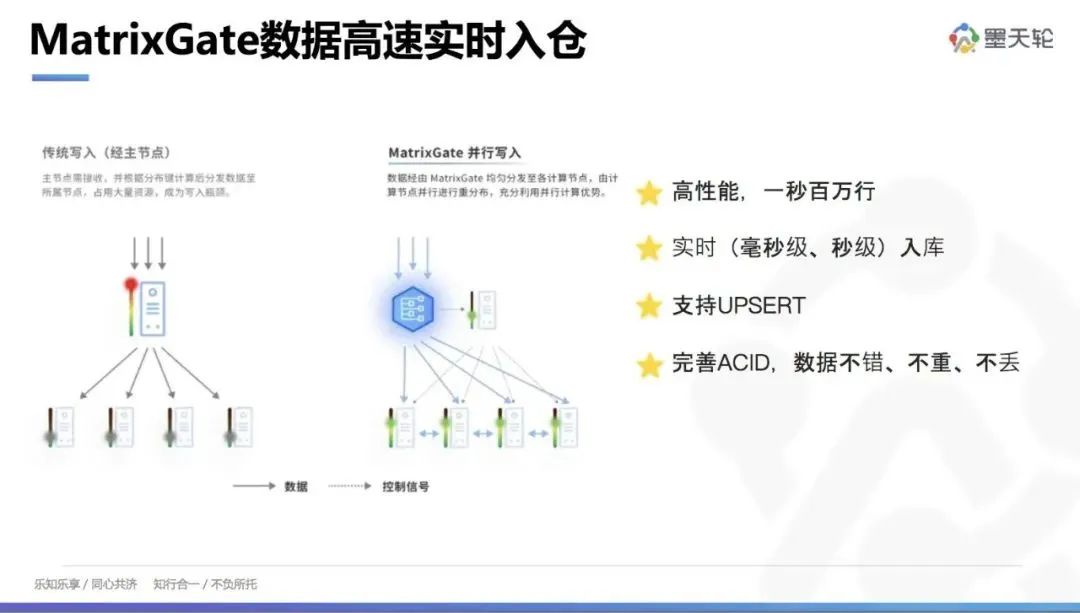
YMatrix 在存储引擎方面进行了一些重要的优化,以解决 Greenplum(GP)常见的仅适合大批量数据导入、操作效率低下等问题。
YMatrix 引入了行列混存(Hybrid Row-Column Storage)的概念。在我们的表格内,部分数据按列存储,但整行数据能够在数据块内定位,避免了查询单行数据时需要读取大量数据文件的问题。此外,我们对数据块进行有序排序(Sorted Columns),通过指定排序字段,使数据块内的数据有序,从而提高压缩比和检索效率。
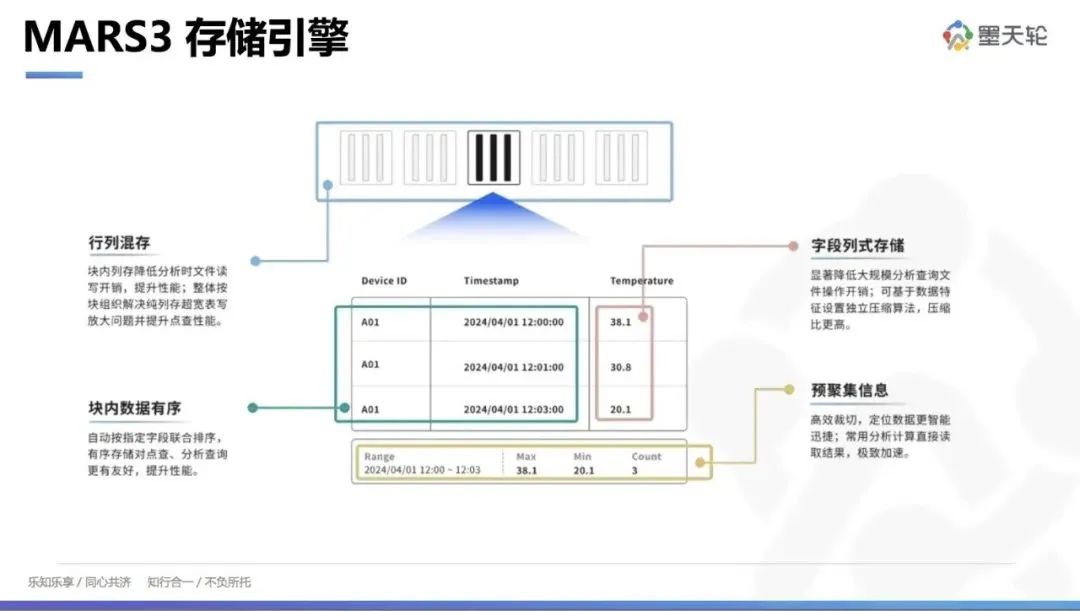
图6 MARS3 存储引擎示意图
五、 MXVector 向量化计算引擎
在讲到向量化引擎时,我们先了解下标量化与向量化的区别。标量化需要多次指令周期来计算例如 a 加 b 等于 c,而向量化则利用 CPU 的指令集,在单个指令周期内处理多个数据输入,例如同时计算三组 a 加三组 b,直接得出三组 c,显著提升了性能效率,通常达到指数级的提升。
通过引入 MXVector 向量化计算引擎,我们在查询性能优化方面取得了显著成效。对于一个带有复杂条件的查询,关闭向量化时可能需要 5 秒钟完成,但开启向量化后,仅需 30 毫秒即可完成,性能提升效果非常明显。

图7 MXVector 向量化计算引擎示意图
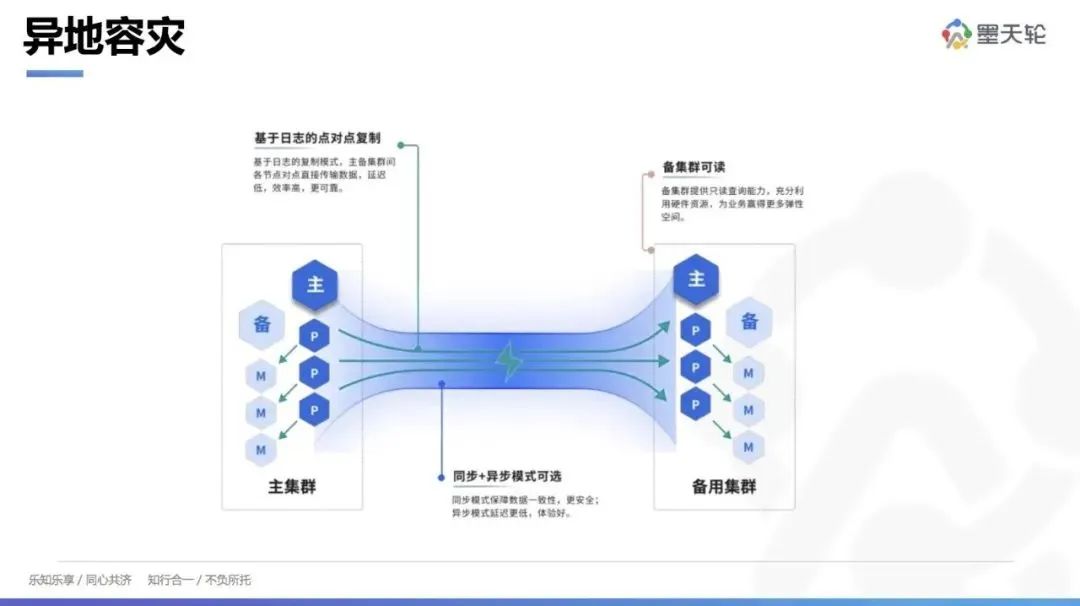
六、 异地容灾
此外,针对金融级客户,尤其是对高可用性要求极为关键的客户群体,YMatrix 提供了先进的异地容灾解决方案。作为首个引入这项技术的提供商,YMatrix 能够支持两套 1x 集群之间的数据同步,客户可以选择同步或异步模式,以满足不同业务需求。不仅如此,基于我们强大的读取能力,确保即使在灾难恢复模式下,客户也能够无缝访问和处理数据。

Greenplum 迁移
最后和大家来分享一下 YMatrix 的金融替换案例,我们在某国有大行进行了 Greenplum 4.3 版本的替换,实现了重要的滚动迁移,取得了显著的成果。
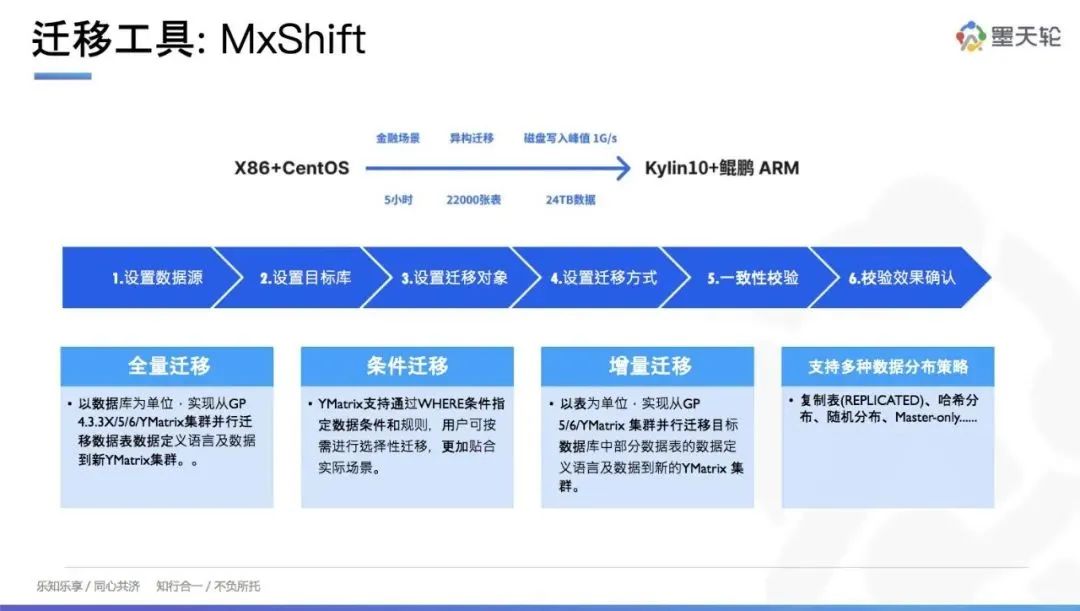
图9 从 Greenplum 迁移到 YMatrix 过程
在具体迁移过程中,原架构使用的是 x86+3 通道服务器,迁移到鲲鹏信号体系后,节点数量从 32 台减少到 10 台。整个迁移过程耗时 5 小时,迁移了 2 万多张表和 24TB 据。在分布式写入方面,我们充分利用了系统性能,达到了满负载写入。此外,我们还支持条件筛选、数据分布策略调整、数据一致性校验以及结果确认。此次迁移显著提升了系统的性能和稳定性,为金融行业提供了可靠的数据处理解决方案。如果大家 YMatrix产品感兴趣,欢迎添加小助手。
我今天的分享就到这里,谢谢大家!
感谢你的阅读,YMatrix 期待与志同道合的你一起同行。





