





👆 立即咨询 TiDB 企业版 👆
TiDB Vector Search 公测
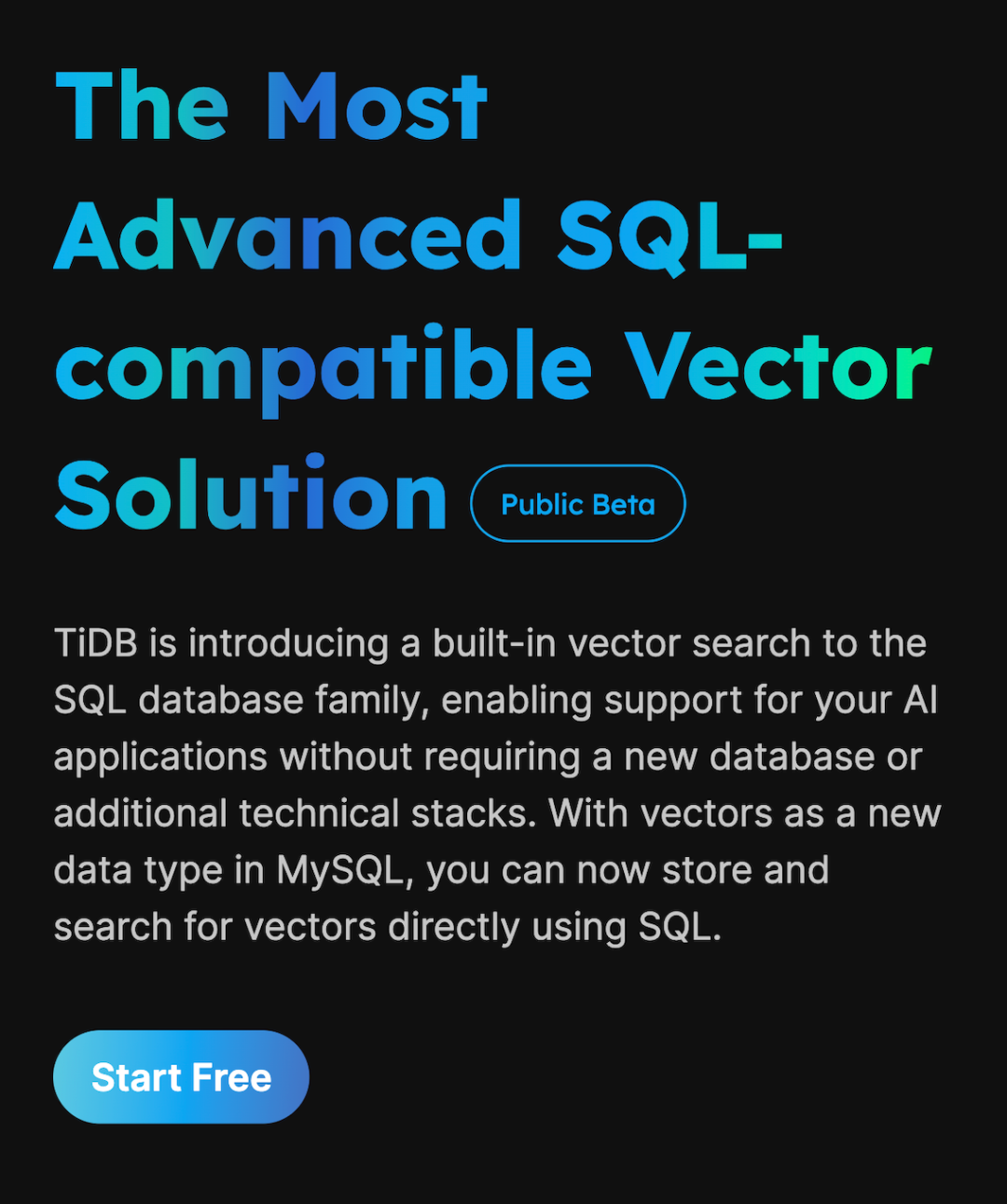
让 TiDB 来支持你的 AI 应用开发吧!
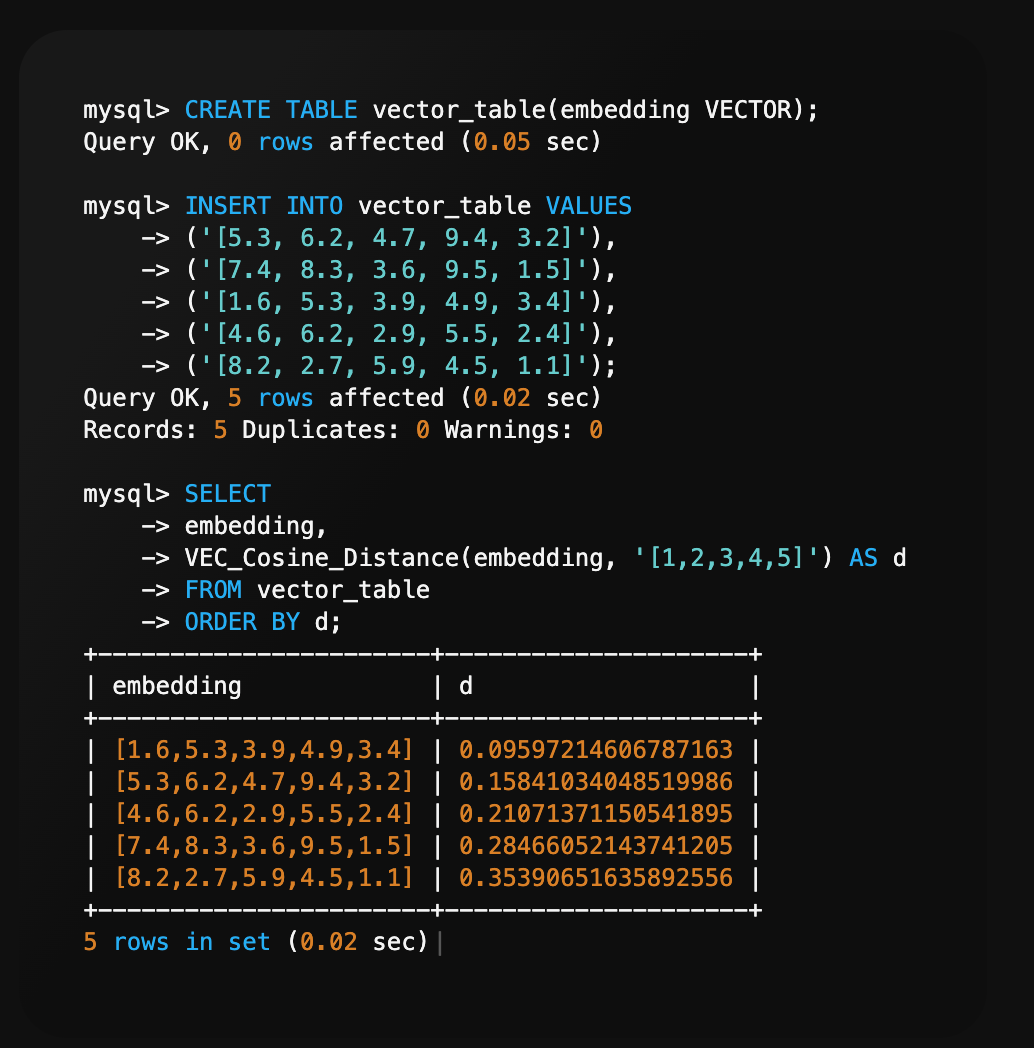

左右滑动,查看更多
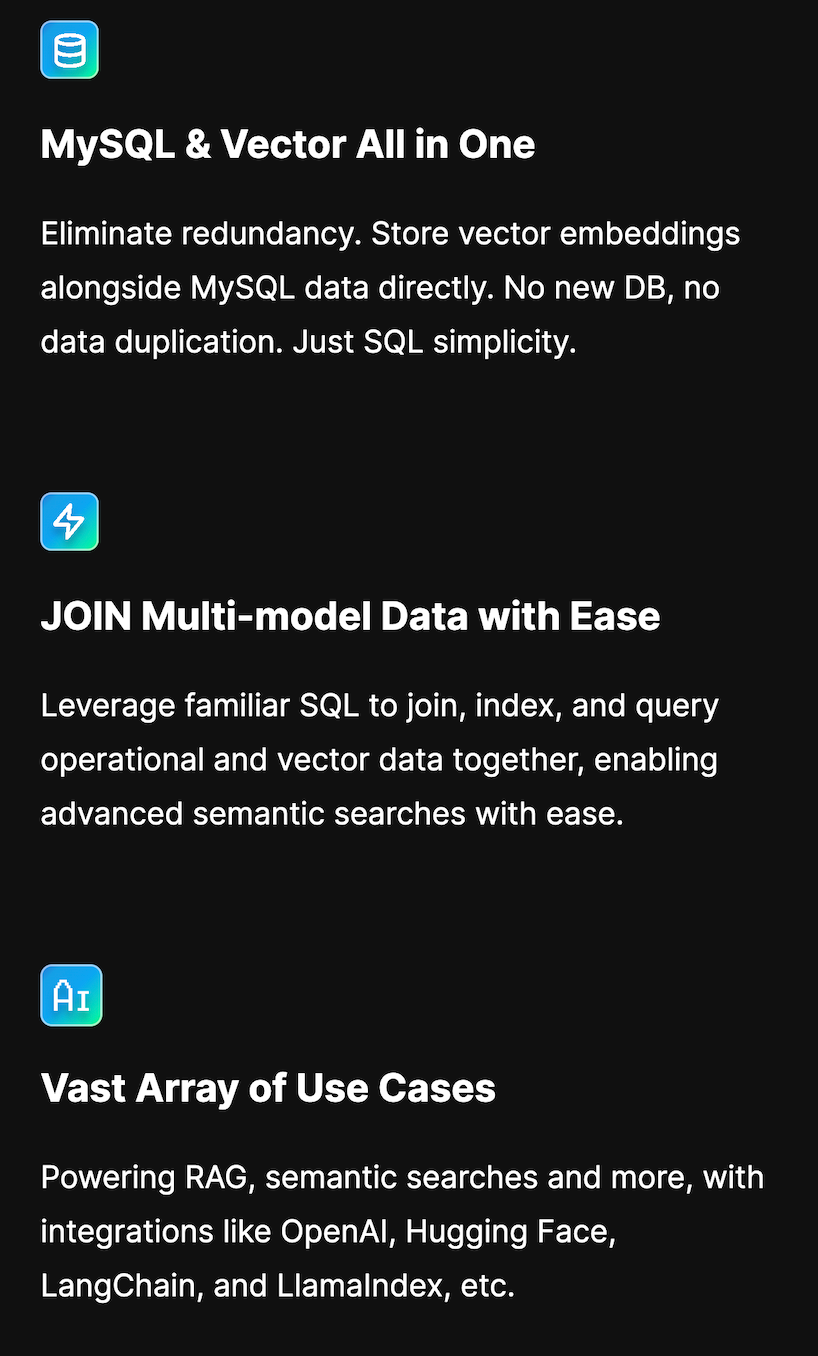
TiDB Vector Search 以其内置的向量搜索功能,让 AI 应用开发直接在 TiDB 中无缝进行,无需额外数据库或技术栈。无论是语义搜索、推荐系统还是图像识别,TiDB 都能精准捕捉数据背后的深层含义,提供高效、智能的搜索体验。
现在就加入我们,体验 TiDB Vector Search 的强大功能:
⚫ 动态可扩展性:轻松处理数十亿向量数据,性能不打折。
⚫ 统一数据库:HTAP 支持与向量存储的完美结合。
⚫ SQL 兼容:熟悉的 SQL 环境,简化操作与查询。
立即注册 TiDB Serverless,开启你的向量搜索体验:https://www.pingcap.com/ai

快来看看 TiDB 社区的小伙伴们如何使用 TiDB Vector Search 构建自己的 AI Agent 和“以图搜图”的 AI 应用吧!
01
Dify + TiDB Vector,
快速构建你的 AI Agent
引言
目前 TiDB Vector 的功能已经推出,开源了 tidb-vector-python ,并在两个 AI Agent 引擎中支持了它,具体可以看 LangChain 和 LlamaIndex 的文档。然而,这两个开源框架对于非开发者还是略有难度和学习成本,本文介绍了如何通过 Dify 快速使用 TiDB Vector 搭建 AI Agent。
前期准备
⚫ 创建 TiDB Vector
目前如果想使用 TiDB Vector 功能暂时还需要申请,预计会很快公测。申请地址是 https://tidb.cloud/ai,申请通过后会收到体验邀请的邮件,收到邮件后就可以登录 TiDB Cloud 来体验了。
⚫ 部署 Dify
Dify 是一个开源的 LLM 应用开发平台,通过简洁的界面用户可以进行模型管理、搭建 RAG 和 Agent 等,除此之外 Dify 也提供了可观测功能,具体可以看官方文档。
作为个人使用 Dify 有两种方式:云服务和自托管社区版。
Dify 云服务中默认使用的向量数据库是 weaviate ,所以如果想要将向量库切换成 TiDB Vector,需要是用社区开源版进行自托管。
基于 Dify 创建 Agent
我们先复习一下用向量库增强大模型 (RAG) 的流程:
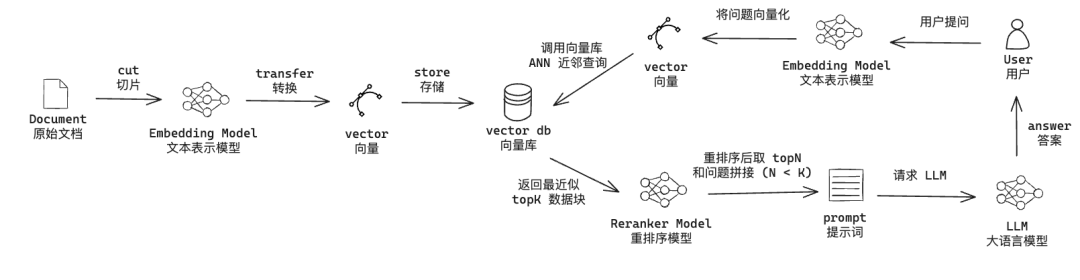
上面这张图主要分为左右两部分:
左半部分是用户上传文档到向量库右半部分是用户使用向量库的数据增加大模型能力用户提出问题将用户的问题通过 Embedding 模型向量化以问题向量化作为查询节点,对向量库进行 ANN 查询,返回 TopK 个近邻节点将 用户问题和 TopK 节点的数据传递给 Reranker 模型进行重排序,并选择重排后的 TopN (N < K)将问题和 TopN 节点的内容拼接成 prompt 作为大模型的上下文调用大模型。
访问 http://localhost ,选择知识库,上传文件并创建。然后进入知识库设置,配置 Embedding 和 Reranker 模型。
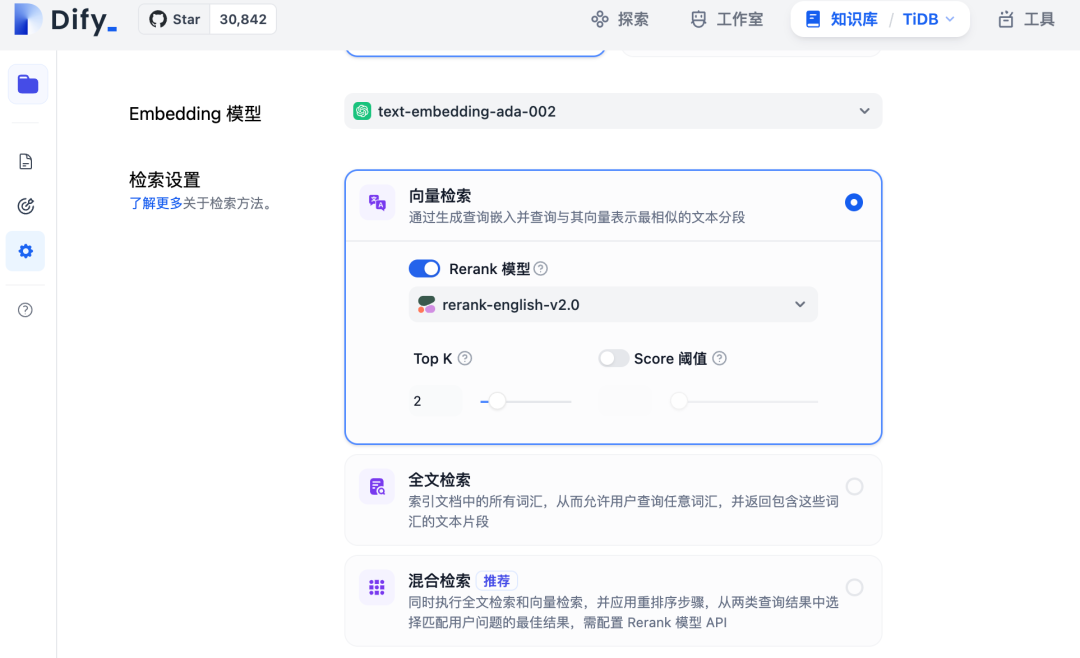
配置知识库设置并上传文件后,我们就可以创建 Agent 了。
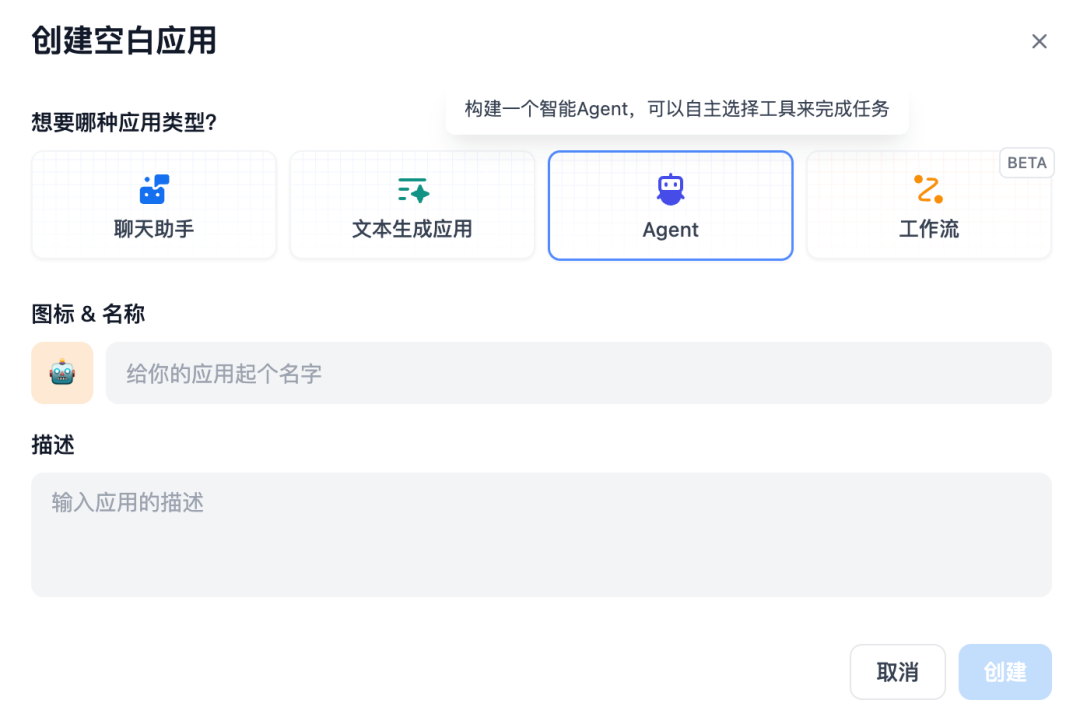
在「工作室」中选择创建空白应用,选择 Agent 并设置图标、名称和描述信息。
进入 Agent 详情后,在上下文中添加我们刚刚创建的知识库。除了知识库之外,我们还可以设置大模型人设、工具等等。此处不作过多赘述,详情请移至官方文档。
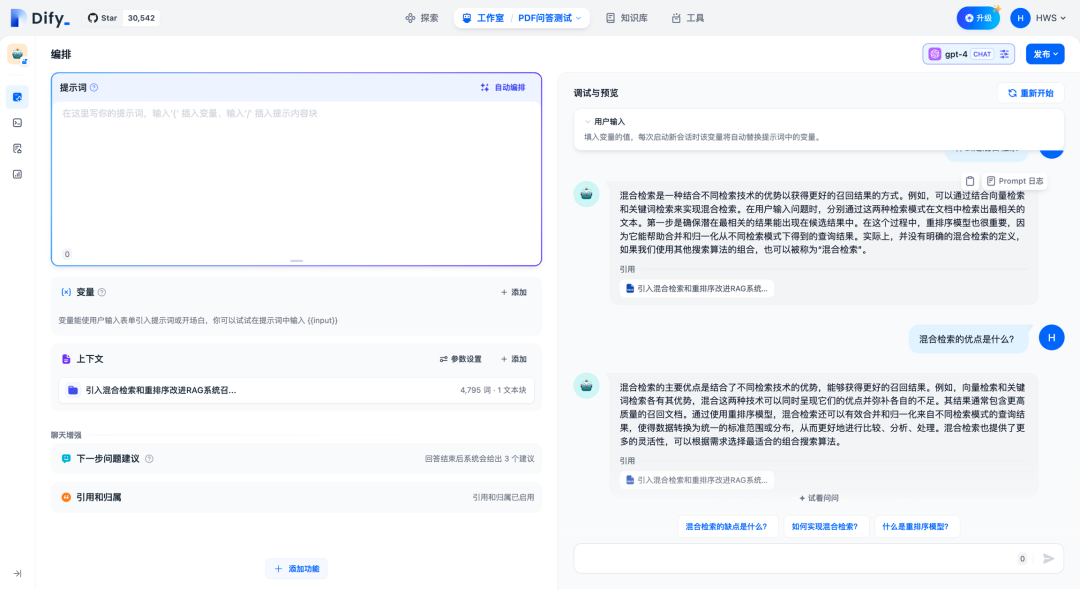
完成上面这些操作后,我们已经基于 TiDB Vector 创建好了 Agent。
如果想要在别的平台或者网站使用,可以点击右上角的「发布」。目前 Dify 支持通过 script、iframe 或者 api 接口调用的方式使用 Agent。
点击此处丨查看原文
02
TiDB Vector 太香啦:
以图搜图初体验!
创建 TiDB Veceor 实例
TiDB Serverless 提供了免费试用额度,对于测试用途绰绰有余,只需要注册一个 TiDB Cloud 账号即可。
创建 TiDB Vector 实例和普通的 TiDB 实例并没有太大区别,在创建集群页面可以看到加入了如下开关:
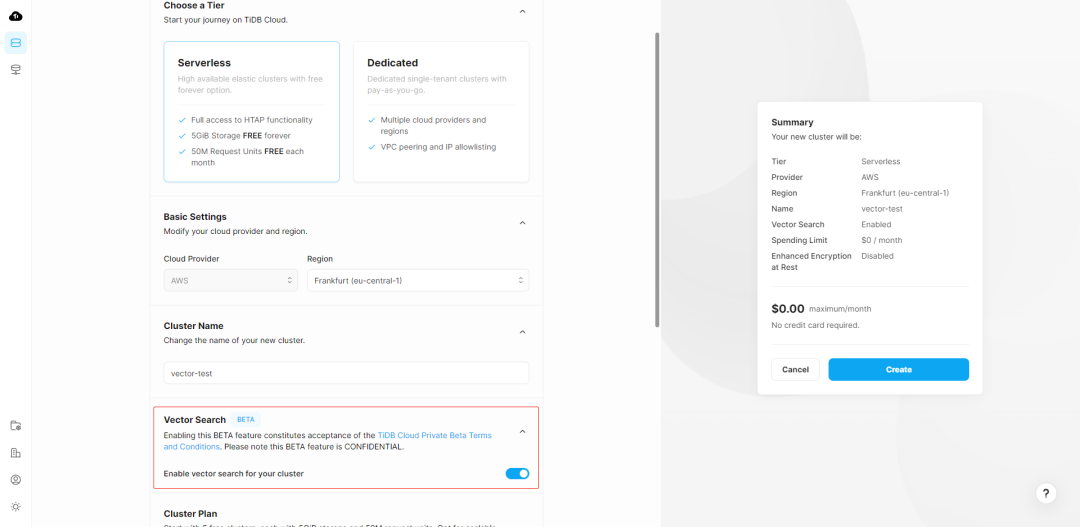
不过要注意的是目前 TiDB Vector 只在部分区域开放,大家可以根据实际情况选择。
这里只需要填一个集群名称就可以开始创建,创建成功后的样子如下所示:
关于向量的那些事
⚫ 一些基础概念
向量:是由浮点数组成的数组,其长度即维度决定了其在多维空间中的精确度,例如RGB的颜色表现法。
embedding:中文翻译叫嵌入,是把非结构化数据(文本、语音、图片、视频等)通过一系列算法加工变成向量的过程。
向量检索:计算两个向量之间的相似度。
⚫ 向量检索原理
向量检索通过余弦相似度和欧式距离计算,从二维到n维坐标系,应用勾股定理和余弦公式,逐维扩展计算方法。
第一个 TiDB AI 应用:
以图搜图
借助前面介绍的理论知识,一个以图搜图的流程应该是这样子:

⚫ 使用向量索引优化
向量索引通过 ANN 算法如 HNSW 优化性能,降低全量搜索的 CPU 消耗,TiDB Vector 目前已支持此算法。
未来展望
传统关系型数据库难以搜索非结构化数据,哪怕是号称无所不能的 PostgreSQL 在向量插件的加持下也没有获得太多关注,TiDB Vector 的出现顺应了AI时代多样化的应用需求和丰富的技术生态。
不可忽视的是,传统数据库集成向量化的能力已经是大势所趋,哪怕是 Redis 这样的产品也拥有了向量能力。前有专门的向量数据库阻击,后有各种传统数据库追赶,这注定是一个惨烈的赛道,希望 TiDB 能深度打磨产品,突围成功。
期待的功能:更多的索引类型、GPU 加速等。
当然了,最大的愿望必须是 TiDB On-Premises 中能尽快看到 Vector 的身影。
给 TiDB 点赞!
点击此处丨查看原文
👇 立即咨询 TiDB 企业版 👇
