




上篇主要内容回顾,aurora的几个关键特性:
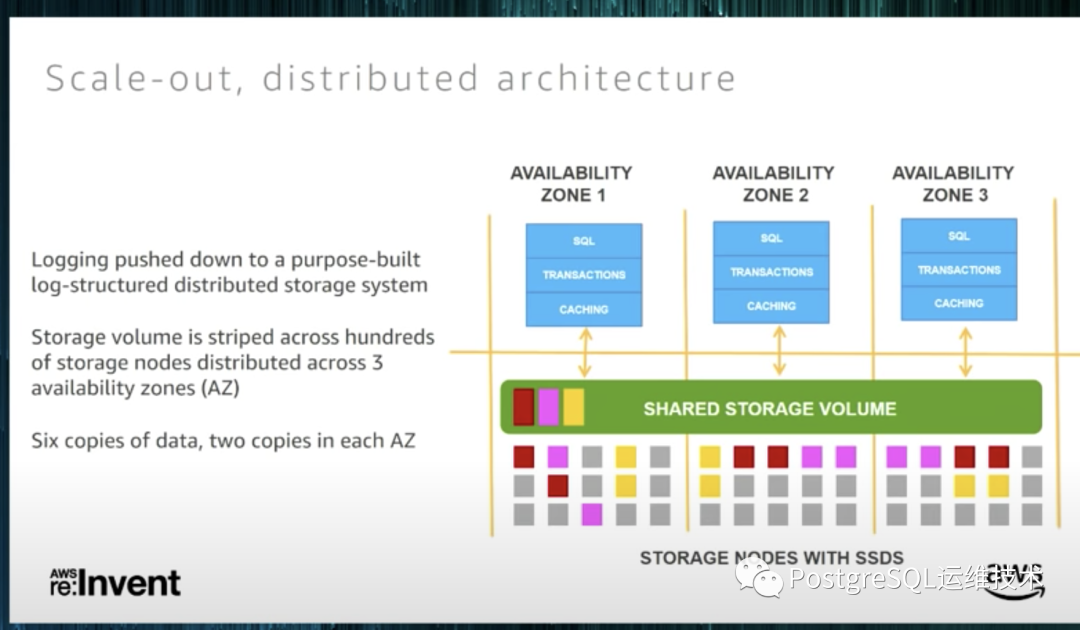
存储与计算分离:aurora采用存储与计算分离的架构,将redo log的逻辑下推到分布式存储服务中,达到存储节点与数据库实例(计算节点)松耦合。 Quorum协议:底层分布式存储的复制基于Quorum协议,假设复制拓扑中有v个节点,每个节点都有一个投票权,读和写需要分别拿到Vr和Vw个投票才能返回。aurora使用跨3个az的6副本模型,每个az两个副本,Vw是4,Vr是3。Aurora可以容忍任何一个AZ出现故障,不会影响写服务;任何一个AZ出现故障,以及另外一个AZ中的一个节点出现故障,不会影响读服务且不会丢失数据。aurora跨三个az的6副本模型可以保证实例有Az+1的故障容错能力。
 图片来源:aws re:invent 2017: Deep Dive on the Amazon Aurora MySQL-compatible Edition
图片来源:aws re:invent 2017: Deep Dive on the Amazon Aurora MySQL-compatible Edition
分段管理:为了降低故障的修复时间,减少故障同时发生的概率,进一步提升服务可用性,aurora将存储数据进行分段管理。每个分段10G, 6个10G副本构成一个PG(protection group)。分段后,每个分段作为一个故障单元。在10gps网络下,一个10G的分段,可以10s内恢复。进一步降低了同时出现2个分段故障的概率。
 图片来源:aws re:invent 2017: Deep Dive on the Amazon Aurora MySQL-compatible Edition
图片来源:aws re:invent 2017: Deep Dive on the Amazon Aurora MySQL-compatible Edition
只写redo log:通过只写redo log到存储,不会从数据库层写入任何页面到存储层,大大减少网络IO。传统数据库的刷脏页、checkpointing、backup都是redo log的回放,全部下推到存储层,在后台不间歇地异步执行,不影响前台用户任务。
本篇主要介绍Aurora如何在不利用2pc协议的情况下,保证数据一致性(主要对应论文中第四章内容)。
一致性
首先介绍下Aurora中存储服务层redo日志相关几个关键的概念。
LSN: 每个日志记录都有一个相关的日志序列号(LSN), 该序列号是由数据库生成的单调递增的值。
VCL: Volumn Complete LSN,表示存储服务拥有VCL之前的所有完整的日志,也就是存储节点保证小于等于这个VCL的数据都已经确认提交了。在故障恢复时,所有LSN大于VCL的日志都要被截断。
CPLs: Consistency Point LSNs,对于MySQL(InnoDB)而言,每个事务在物理上由多个mini-transaction组成,每个mini-transaction是最小原子操作单位,重做日志时,也需要以mini-transaction为单位。CPL表示一组日志中最后的一条日志的LSN,一个事务由多个CPL组成,所以称之为CPLs。
VDL: Volumn Durable LSN,表示已持久化的最大LSN,是所有CPLs中最大的LSN,VDL<=VCL,为了保证不破坏mini-transaction原子性,所有大于VDL的日志,都需要被截断。比如,VCL是1007,900,1000,1100是CPLs,那么我们需要截断1000以前的日志。
VDL表示了数据库处于一致状态的最新位点,在故障恢复时,数据库实例以PG为单位确认VDL,截断所有大于VDL的日志。
使用LSN可以避免使用2PC来保证一致性,并且过程是异步的。
Writes
在Aurora中,数据库收到write quorum的ack后会推进VDL, 数据库中可能同时存在很多活跃的事务,但是数据库在分配LSN时,不会超过VDL+LAL(LSN Allocation limit,表示新分配LSN与VDL差值的最大阈值,10m),保证数据库服务的LSN不会超前存储服务的LSN太多,当存储服务或者网络故障时,前台请求不会继续涌进来。
存储将数据进行分段管理,每个段管理一部分页面,当一个事务的修改跨多个分段时,事务对应的日志被打散,每个segment只能看到volume上一部分log。每个log有前一个log的链接,每个segment有一个最大的LSN称为SCL(segment complete LSN)。SCL用来追踪segment的完整性,每个存储节点通过gossip协议来查找和交换缺失的日志。
Aurora的写入并没有走2PC,它是基于Quorum的, 不会保证每一个storage node 都有完整的redo log stream. 但是node之间通过gossip协议不断去把node里面空缺的redo log补上。
paper原文
In Aurora, the database continuously interacts with the storage service and maintains state to establish quorum, advance volume durability, and register transactions as committed. For instance, in the normal/forward path, as the database receives acknowledgements to establish the write quorum for each batch of log records, it advances the current VDL. At any given moment, there can be a large number of concurrent transactions active in the database, each generating their own redo log records. The database allocates a unique ordered LSN for each log record subject to a constraint that no LSN is allocated with a value that is greater than the sum of the current VDL and a constant called the LSN Allocation Limit (LAL) (currently set to 10 million). This limit ensures that the database does not get too far ahead of the storage system and introduces back-pressure that can throttle the incoming writes if the storage or network cannot keep up.
Commits
在aurora中,事务提交是异步完成的。当客户端提交事务时,处理提交请求的线程将commit lsn放进等待提交的事务列表中,然后继续执行其他工作。当VDL大于commit lsn时,表示这个事务已经提交完成,就可以向客户端发送提交确认。这种异步的方式,大大提高了系统的吞吐。
paper原文:
In Aurora, transaction commits are completed asynchronously. When a client commits a transaction, the thread handling the commit request sets the transaction aside by recording its “commit LSN” as part of a separate list of transactions waiting on commit and moves on to perform other work. The equivalent to the WAL protocol is based on completing a commit, if and only if, the latest VDL is greater than or equal to the transaction’s commit LSN. As the VDL advances, the database identifies qualifying transactions that are waiting to be committed and uses a dedicated thread to send commit acknowledgements to waiting clients. Worker threads do not pause for commits, they simply pull other pending requests and continue processing.
reads
在传统型数据库中,只有访问的page不在cache才会产生磁盘IO,同时如果cache满了,会有刷脏页的过程。
aurora中不会有刷脏页面的过程,因为它直接丢弃脏页。这就要求aurora cache中的数据页一定有最新的数据,被淘汰的数据页的page-lsn(页面中最新更改对应的LSN)小于或等于VDL。
在正常情况下,进行读操作时并不需要走Quorum。当数据库实例需要读磁盘IO时,将当前最新的VDL作为一致性位点read-point,并选择一个大于VDL位点的节点作为请求节点,这样只需要访问这一个节点即可得到数据页的最新版本。
 图片来源:aws re:invent 2017: Deep Dive on the Amazon Aurora MySQL-compatible Edition
图片来源:aws re:invent 2017: Deep Dive on the Amazon Aurora MySQL-compatible Edition
replicas
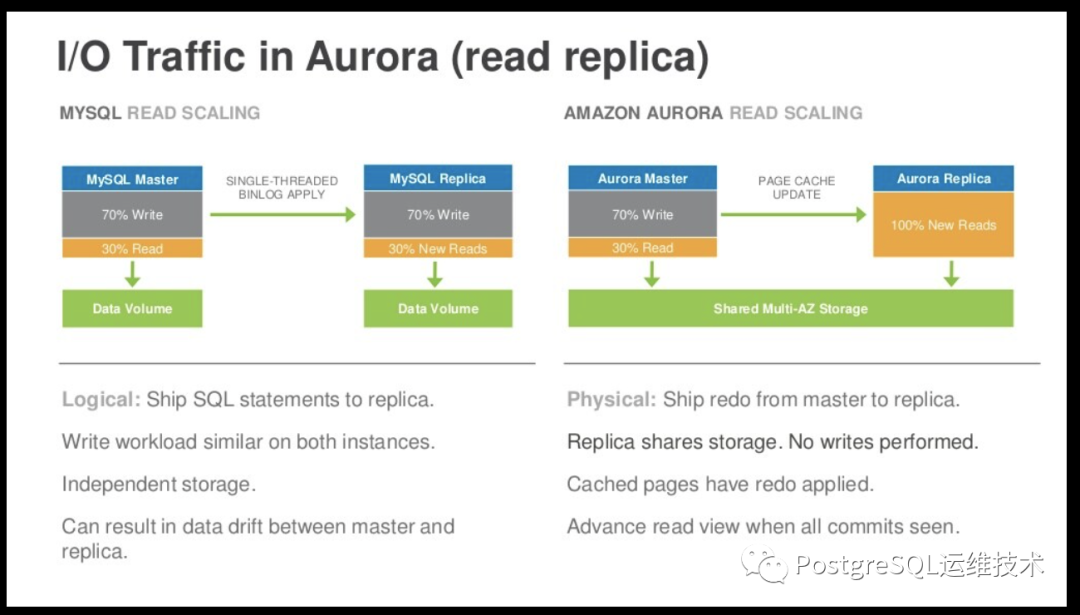
在aurora中,写副本实例和至多15个读副本共享一套分布式存储服务。增加读副本实例并不会消耗更多的磁盘空间。
为了最小化延迟,由写入器生成并发送到存储节点的日志流也会发送给所有读副本。在读取器中,如果日志记录指向读取器缓冲区缓存中的一个页,则它使用日志应用程序来将指定的redo log应用于缓存中的页。否则,它将直接丢弃该记录。
写入器向读副本发送日志是异步的,写副本执行提交操作不受读副本的影响。
图片来源:https://www.slideshare.net/AmazonWebServices/getting-started-with-amazon-aurora-64624162?qid=dcad42d4-af69-4ca8-8fd5-3a530a1caa86&v=&b=&from_search=8
recovery
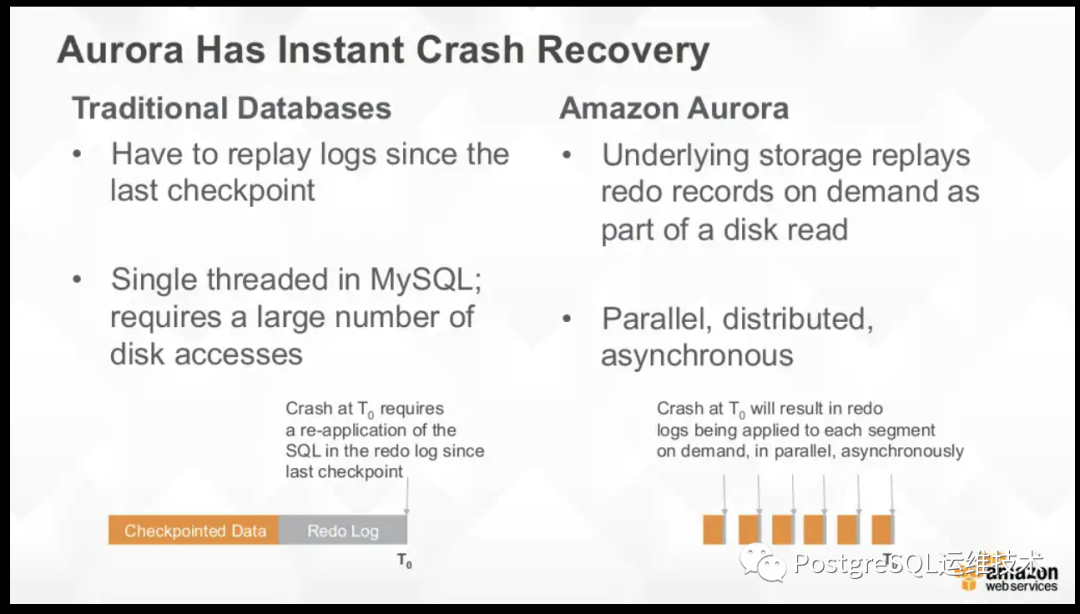
大多数数据库基于经典的ARIES协议处理故障恢复,通过WAL机制确保故障时已经提交的事务持久化,并回滚未提交的事务。这类系统通常会周期性对数据库进行checkpoint, 通过将脏页刷新到磁盘并将检查点记录写到日志,以这种粗粒度的方式建立一个持久化位点。故障时,数据页中可能包含已提交和未提交的数据。因此,在故障恢复时,系统需要从上一个检查点开始回放日志,将数据页恢复到故障发生时的状态,然后根据undo log回滚未提交事务。
崩溃恢复十分“昂贵”,减少checkpoint间隔会有所帮助,但代价是对前台事务的干扰。而aurora不需要做这种权衡。
因为aurora将回放日志的逻辑下推了存储层,并且在数据库后台根据负载按需不间歇地异步执行。数据库实例宕机重启后,需要进行故障恢复来获得运行时的一致状态,实例与Read quorum个存储节点通信,这样确保能读到最新的数据,并重新计算新的VDL,超过VDL部分的日志都可以被截断丢弃。
 图片来源:https://www.slideshare.net/AmazonWebServices/amazon-aurora?qid=dcad42d4-af69-4ca8-8fd5-3a530a1caa86&v=&b=&from_search=1
图片来源:https://www.slideshare.net/AmazonWebServices/amazon-aurora?qid=dcad42d4-af69-4ca8-8fd5-3a530a1caa86&v=&b=&from_search=1
参考文档:
https://www.cnblogs.com/cchust/p/7476876.html
https://www.slideshare.net/AmazonWebServices/deep-dive-on-the-amazon-aurora-mysqlcompatible-edition-dat301-reinvent-2017
