





本文作者
在向联机分析处理(OLAP)的广阔舞台上,向量化引擎犹如一股强劲的驱动力,其重要性不言而喻。它通过深度挖掘计算潜能、精细优化数据处理流程以及无缝整合硬件资源,为查询速度和数据处理效率带来了质的飞跃,稳坐OLAP系统核心组件的宝座。其核心魅力,在于其独到的批量数据处理机制,颠覆了传统逐行计算的范式,实现了一次性处理大规模数据集的能力,从而显著加速了数据处理与计算进程。
OceanBase数据库在演进至3.2版本时,已前瞻性地引入了向量化执行引擎这一先进技术,但彼时该特性尚处于用户可选的状态。然而,随着技术的不断成熟与应用的深入探索,自OceanBase 4.0版本起,向量化执行引擎被正式设定为默认启用状态,标志着其在性能优化上的重要里程碑。而在最新的OceanBase 4.3版本中,向量化引擎更是迎来了2.0时代的全面升级,通过一系列创新举措——包括数据格式的革新、算子实现的深度优化以及存储层面的向量化策略强化等,实现了执行性能的又一次飞跃式提升。接下来,本文将深入剖析向量化引擎2.0的核心改进亮点,并探索这一强大工具在实际项目部署与应用中的最佳实践策略。
一、向量化引擎2.0带来了哪些变化
(一)数据格式优化
向量化数据格式优化是向量化引擎 2.0 核心改进点, 向量化引擎 1.0 实现中,存储层数据投影后,某列表达式一批数据在内存中的组织格式,是由多个连续数据描述单元及实际数据组成,每个数据描述单元中,均包含 null 描述,数据长度 len 及数据指针 ptr,实际数据值并不在数据单元描述中,而是存在 ptr 指向的地址,对于定长数据,存在以下几个问题:
读写访问不够高效。每次访问(读/写)都需要先获取数据描述单元,然后通过数据描述单元中 ptr 访问数据,不能直接访问数据。 内存使用更多。比如存放 N 行 int32_t 数据,数据描述单元结构占 12 个字节,从而总共需要 N * (12+4)字节,而实际数据只有 N * 4 个字节, 空间会放大 4 倍,导致内存访问、数据物化和数据 shuffle 时开销均更高。 SIMD 计算不够友好。一批数据对应的实际数据不一定连续存放,对 SIMD 的使用不够友好。 序列化/物化开销更多。在进行数据序列化和数据物化时,需要进行指针的 swizzling,即将指针转换为相对偏移。
为优化向量化 1.0 数据格式带来的以上不足,向量化引擎 2.0 中,实现了新的按列的数据格式。将数据描述信息 null, len, ptr 信息,分别按列的方式,分开连续存放,避免数据信息冗余存储,针对不同数据类型和使用场景,实现了 3 种数据格式:定长数据格式、 变长离散格式、变长连续格式:
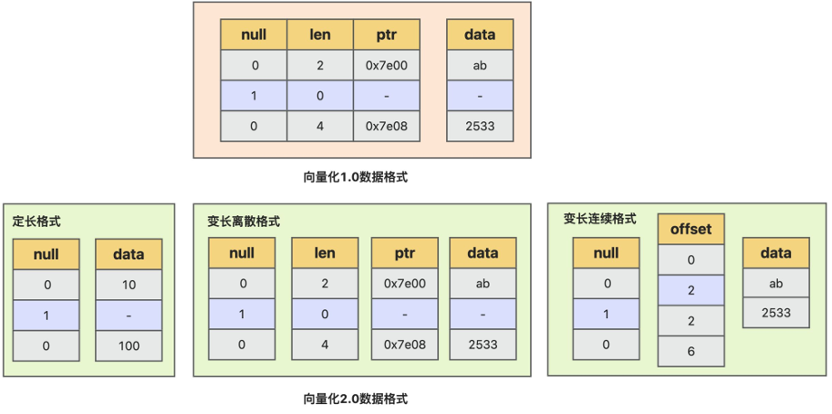
定长数据格式,只需要 null bitmap 和连续的数据信息,length 信息,只需要存放一份 length 值,不需要一批数据中每个数据冗余存放相同值,也不再需要间接访问的指针信息。相比以前向量化 1.0 数据格式,数据信息没有冗余存放,更加节省空间;可以直接访问,并且访问数据局部性更好;数据能确保连续存放,对于 SIMD 使用也更友好;此外在进行物化及序列化时,不需要对数据进行指针的 swizzling 操作,效率更高。
变长离散格式,是指一批数据中,每个数据在内存中存放可能是不连续的,每个数据使用数据地址指针和长度描述,长度信息和指针信息,分别按列的方式连续存放;使用这种格式,存储层如果是编码数据,投影时不需要深拷贝数据,只需要投影 len 和 ptr 信息,并且对于短路计算场景,一批数据可能仅计算其中几行,这时也可以使用该格式描述并且不需要重整数据。
变长连续格式,是指数据是连续存放在内存中的每个数据的长度信息和偏移地址,使用 offset 数组描述,该描述格式相比离散格式,在数据组织时,需要确保数据连续,对数据访问和数据按批 copy 效率更高,不过对于短路计算场景及列存编码数据投影不是很友好,需要对数据进行数据重整及深拷贝,当前该格式主要用于按列物化场景。
(二)算子及表达式性能优化
向量化引擎 2.0,对算子及表达式实现进行了全面优化,主要优化思路是基于新的格式,使用 batch 数据属性信息、算法数据结构优化及特化实现,从而减少 CPU 数据 Cache Miss,降低 CPU 分支预测错误及 CPU 指令开销,提升整体执行性能;向量化 2.0 将 Sort、Hash Join、Hash Group By、数据 Shuffle、聚合计算等算子和表达式按新格式进行了重新设计与实现,整体计算性能全面提升;
利用 batch 数据属性信息
向量化引擎 2.0,维护了执行过程中,batch 数据的特征信息,包括是否不存在 NULL,是否 batch 中行均不需要被过滤等信息,利用这些信息可大大加速表达式计算,比如 NULL 如果不存在,则表达式计算过程中不需要考虑对 NULL 的特殊处理,如果数据行均没有被过滤,则不需要计算时每行去判断是否已经被过滤,并且数据是连续的,没有被过滤,对使用 SIMD 计算也更友好;
算法及数据结构优化
在算法及数据结构优化方面,实现了更加紧凑的中间结果物化结构,支持按行/列物化数据,空间更省,访问也更更加高效;Sort 算子实现了 sort key 与非 sort key 分离物化,结合对 sort key 保序编码(将多列数据编码为 1 列,可直接使用 memcpy 进行比较),Sort 在比较过程中访问数据 Cache Miss 更低,比较计算本身更快,整体排序效率更高;HashGroupBy 对 Hash 表结构均进行了优化,HashBucket 中数据存放更加紧凑,并对低基数 Group Key 使用 ARRAY 优化,分组及聚合结果内存连续存放等优化等;
特化实现优化
特化实现优化,主要是利用模版,针对不同场景进行更加高效的实现,比如 Hash Join 特化实现了将多列定长 join key 编码为一个定长列,并且将 join key 数据放入到 bucket 中,对数据预期也进行了优化,减少了多列数据访问时数据 Cache Miss;支持聚合计算特化实现,不同的聚合计算进行特化分开实现,从而减少每次计算聚合函数指令及分支判断,执行效率大幅提升。
(三)存储向量化优化
存储层全面支持新的向量化格式,对于投影、谓词下压、聚合下压和 groupby 下压更多地使用 SIMD。投影定长和变长数据时,按列类型、列长度,以及是否包含 null 等信息定制化模板,按批浅拷投影。计算下压谓词时,对于简单的谓词计算,直接在列编码上进行;复杂的谓词,投影成新向量化格式在表达式上按批计算。聚合下压充分利用了中间层的预聚合信息,如 count、sum、max、min 等。groupby 下压则利用充分利用编码数据信息,对于字典类型的编码,加速效果非常明显。
二、如何使用向量化引擎2.0
(一)支持向量化1.0和2.0算子混跑
当前支持向量化引擎 2.0 的算子包括:Hash Join、Hash Group By、AGGR、Hash Distinct、Sort、PX 框架相关算子、Exchange、RunTime Filter 相关算子、TempTable 相关算子、Material、SubplanScan、Limit、TableScan。对于其他不支持的算子,会使用向量化引擎 1.0 执行, 同一个计划中,支持向量化 1.0 算子和向量化引擎 2.0 算子混合一起执行,具体不支持向量化引擎 2.0 的算子对应语句类型如下:
所有 DML 语句 CTE Connect By 集合类语句 window function Union 聚合语句(使用 Merge 算法时) JOIN 语句(使用 NLJ 算法时) Distinct 语句(使用 Merge 算法时) 关联子查询(无法改写,只能使用 subplan filter 驱动执行时) Pivot、Unpivot 语句 DBLink 使用 Sequence 对象
(二)如何观测是否使用向量化引擎 2.0
通过查看物理算子名称(GV$SQL_PLAN_MONITOR.PLAN_OPERATION 及 GV$OB_PLAN_CACHE_PLAN_EXPLAIN.OPERATOR),可确定是否使用了向量化引擎 2.0 算子,如果使用了向量化引擎 2.0 算子,则算子名称上有 VEC_ 字样。
三、向量化引擎2.0性能表现
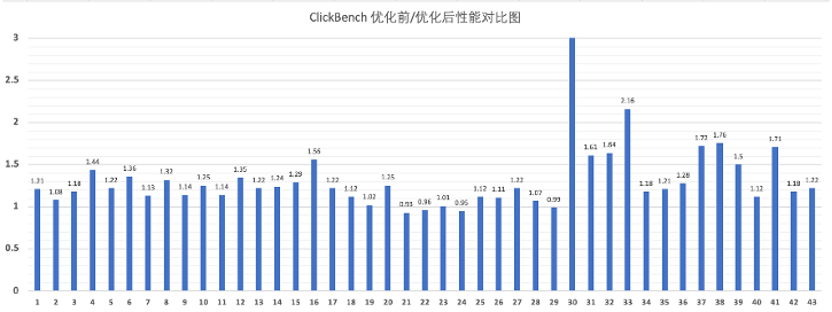
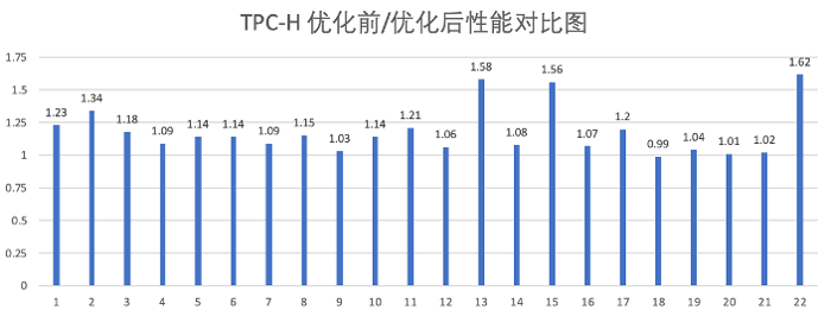
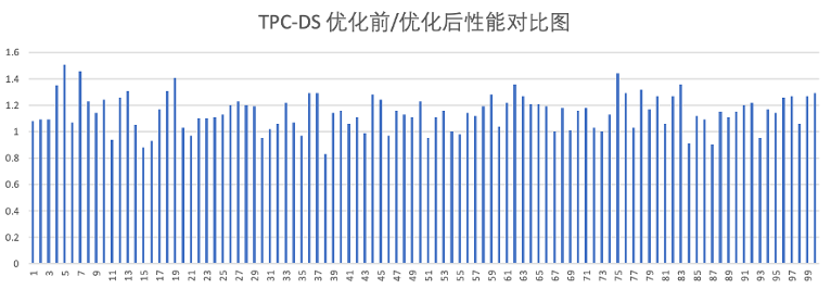
对比向量化引擎 1.0,向量化引擎 2.0 实现性能整体提升情况如下:
ClickBench 整体性能提升 30%; TPC-H 68% query 存在 10%~40% 提升; TPC-DS 56% 的 query 存在 10%~40% 提升;
四、写在最后
OceanBase 向量化引擎 2.0 通过对数据格式、算子、表达式及计算下压存储引擎的优化,进一步挖掘了 SIMD 计算、特化实现及按批访问和处理数据等带来的性能提升,使 OceanBase 能够更快地处理 AP 场景的 SQL 请求。OceanBase 向量化引擎的优化工作仍在继续,后续版本将在性能方面取得更多突破,期待与对向量化引擎优化感兴趣的用户们共同交流。
