





本文字数:14127;估计阅读时间:36 分钟
Meetup活动
ClickHouse Shanghai User Group第1届 Meetup火热报名中,详见文末海报!


又到了发布新版本的时间!
发布概要
本次ClickHouse 24.6 版本包含了23个新功能🎁、24项性能优化🛷、59个bug修复🐛

我们向 24.6 版本的所有新贡献者表示特别欢迎!ClickHouse 的流行离不开社区的贡献,看到社区不断壮大,总是令人感动。
以下是新贡献者的名字:
Artem Mustafin、Danila Puzov、Francesco Ciocchetti、Grigorii Sokolik、HappenLee、Kris Buytaert、Lee sungju、Mikhail Gorshkov、Philipp Schreiber、Pratima Patel、Sariel、TTPO100AJIEX、Tim MacDonald、Xu Jia、ZhiHong Zhang、allegrinisante、anonymous、chloro、haohang、iceFireser、morning-color、pn、sarielwxm、wudidapaopao、xogoodnow
由 Igor Markelov 贡献
MergeTree 表的物理磁盘顺序是由其 ORDER BY 键决定的。
ORDER BY 键和相应的物理行顺序有三个主要目的:
1. 构建稀疏索引以处理范围请求(也可以指定为 PRIMARY KEY)。
2. 定义合并模式的键,例如 AggregatingMergeTree 或 ReplacingMergeTree 表。
3. 通过在列文件中联合存储数据来提高压缩效果。
为了实现第三个目的,本次发布引入了一个新设置,称为 optimize_row_order。这个设置仅适用于普通的 MergeTree 引擎表。在按 ORDER BY 列排序后,它会根据列的基数对剩余列进行排序,以确保最佳压缩效果。
如果数据具有一定的模式,通用压缩编解码器如 LZ4 和 ZSTD 可以实现最高的压缩率。例如,连续相同值的长序列通常能很好地压缩。通过按列值排序行,可以实现这样的长序列,从最低基数列开始。下图对此进行了说明:
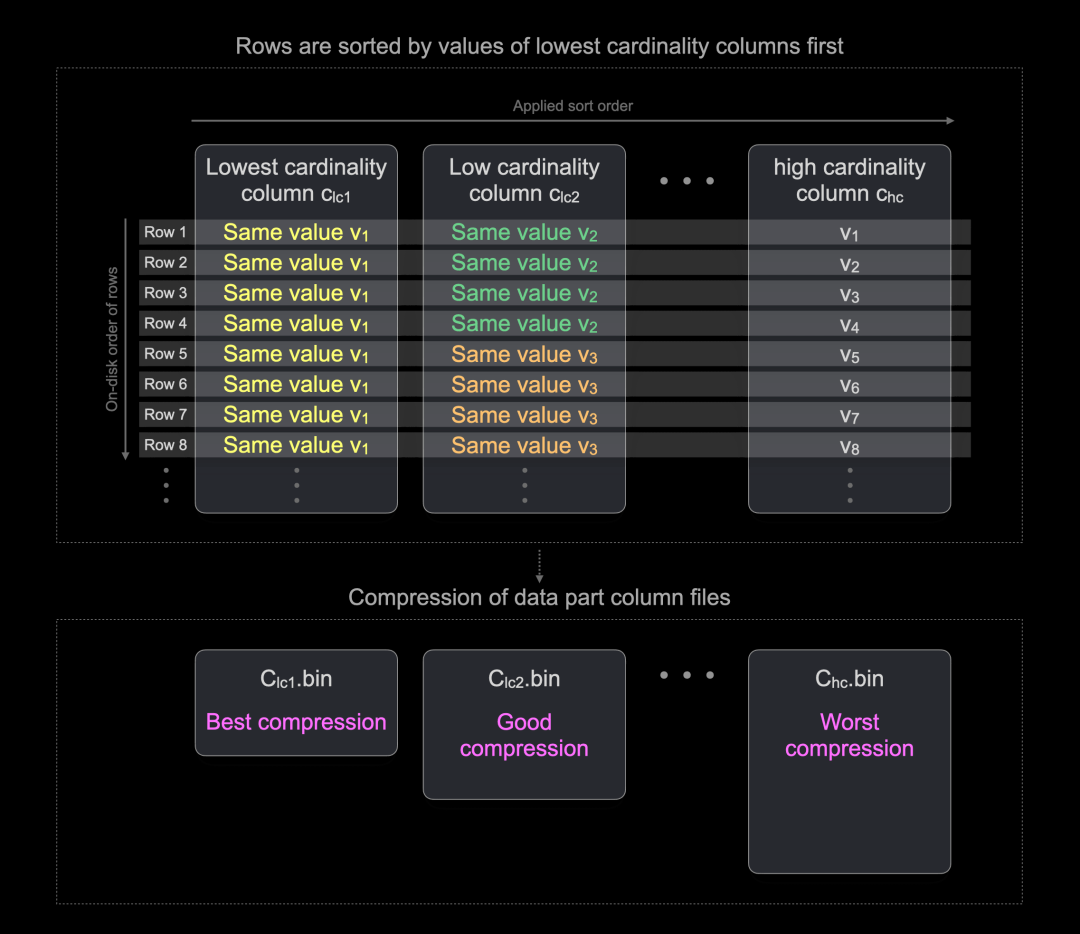
如上图所示,行在磁盘上按列值排序,从最低基数列开始,每列中会有长时间运行相同的值。这样可以提高表部分列文件的压缩比。
作为反例,下图展示了首先按高基数列排序行在磁盘上的效果:
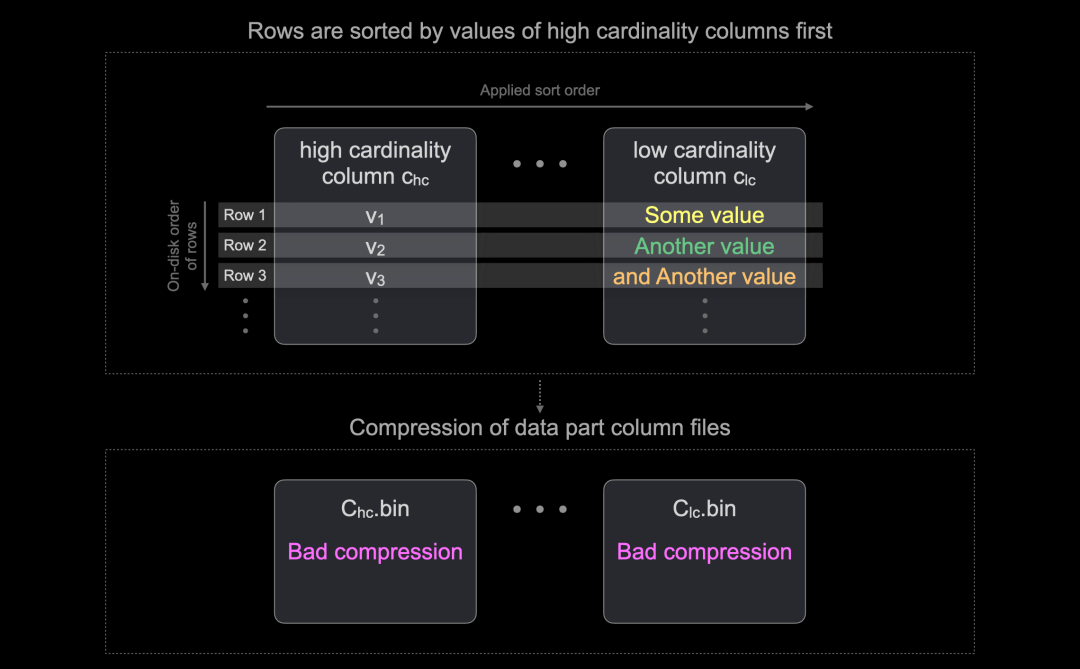
由于行按高基数列值排序,通常无法再根据其他列的值进行排序来形成长序列。因此,列文件的压缩比会不理想。
通过新的 optimize_row_order 设置,ClickHouse 自动实现最佳数据压缩。ClickHouse 仍然按 ORDER BY 列排序在磁盘上存储行。此外,在具有相同 ORDER BY 列值的行范围内,按剩余列的值进行排序,这些列按范围内列基数升序排列:
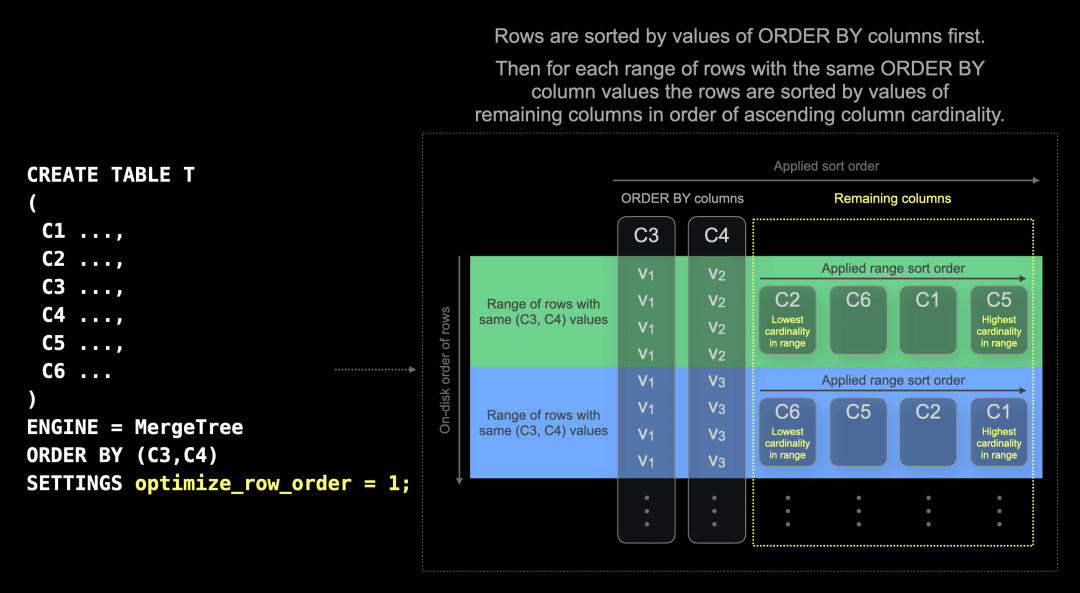
这种优化仅适用于插入时创建的数据部分,不适用于部分合并。由于普通 MergeTree 表的大多数合并仅连接 ORDER BY 键的非重叠范围,因此已优化的行顺序通常会保留。
根据数据特性,预计插入时间将增加 30-50%。
预计 LZ4 或 ZSTD 的压缩率平均会提高 20-40%。
此设置最适用于没有 ORDER BY 键或低基数 ORDER BY 键的表,即仅有少数不同 ORDER BY 键值的表。具有高基数 ORDER BY 键的表,例如 DateTime64 类型的时间戳列,预计不会从此设置中受益。
为了展示这一新优化,我们将 10 亿行公共 PyPI 下载统计数据集加载到一个不使用 optimize_row_order 设置的表和一个使用 optimize_row_order 设置的表中。
我们创建了没有新设置的表:
CREATE OR REPLACE TABLE pypi(`timestamp` DateTime64(6),`date` Date MATERIALIZED timestamp,`country_code` LowCardinality(String),`url` String,`project` String,`file` Tuple(filename String, project String, version String, type Enum8('bdist_wheel' = 0, 'sdist' = 1, 'bdist_egg' = 2, 'bdist_wininst' = 3, 'bdist_dumb' = 4, 'bdist_msi' = 5, 'bdist_rpm' = 6, 'bdist_dmg' = 7)),`installer` Tuple(name LowCardinality(String), version LowCardinality(String)),`python` LowCardinality(String),`implementation` Tuple(name LowCardinality(String), version LowCardinality(String)),`distro` Tuple(name LowCardinality(String), version LowCardinality(String), id LowCardinality(String), libc Tuple(lib Enum8('' = 0, 'glibc' = 1, 'libc' = 2), version LowCardinality(String))),`system` Tuple(name LowCardinality(String), release String),`cpu` LowCardinality(String),`openssl_version` LowCardinality(String),`setuptools_version` LowCardinality(String),`rustc_version` LowCardinality(String),`tls_protocol` Enum8('TLSv1.2' = 0, 'TLSv1.3' = 1),`tls_cipher` Enum8('ECDHE-RSA-AES128-GCM-SHA256' = 0, 'ECDHE-RSA-CHACHA20-POLY1305' = 1, 'ECDHE-RSA-AES128-SHA256' = 2, 'TLS_AES_256_GCM_SHA384' = 3, 'AES128-GCM-SHA256' = 4, 'TLS_AES_128_GCM_SHA256' = 5, 'ECDHE-RSA-AES256-GCM-SHA384' = 6, 'AES128-SHA' = 7, 'ECDHE-RSA-AES128-SHA' = 8, 'AES128-GCM' = 9))Engine = MergeTreeORDER BY (project);
INSERT INTO pypiSELECT*FROM s3('https://storage.googleapis.com/clickhouse_public_datasets/pypi/file_downloads/sample/2023/{0..61}-*.parquet')SETTINGSinput_format_null_as_default = 1,input_format_parquet_import_nested = 1,min_insert_block_size_bytes = 0,min_insert_block_size_rows = 60_000_000;
CREATE TABLE pypi_opt(`timestamp` DateTime64(6),`date` Date MATERIALIZED timestamp,`country_code` LowCardinality(String),`url` String,`project` String,`file` Tuple(filename String, project String, version String, type Enum8('bdist_wheel' = 0, 'sdist' = 1, 'bdist_egg' = 2, 'bdist_wininst' = 3, 'bdist_dumb' = 4, 'bdist_msi' = 5, 'bdist_rpm' = 6, 'bdist_dmg' = 7)),`installer` Tuple(name LowCardinality(String), version LowCardinality(String)),`python` LowCardinality(String),`implementation` Tuple(name LowCardinality(String), version LowCardinality(String)),`distro` Tuple(name LowCardinality(String), version LowCardinality(String), id LowCardinality(String), libc Tuple(lib Enum8('' = 0, 'glibc' = 1, 'libc' = 2), version LowCardinality(String))),`system` Tuple(name LowCardinality(String), release String),`cpu` LowCardinality(String),`openssl_version` LowCardinality(String),`setuptools_version` LowCardinality(String),`rustc_version` LowCardinality(String),`tls_protocol` Enum8('TLSv1.2' = 0, 'TLSv1.3' = 1),`tls_cipher` Enum8('ECDHE-RSA-AES128-GCM-SHA256' = 0, 'ECDHE-RSA-CHACHA20-POLY1305' = 1, 'ECDHE-RSA-AES128-SHA256' = 2, 'TLS_AES_256_GCM_SHA384' = 3, 'AES128-GCM-SHA256' = 4, 'TLS_AES_128_GCM_SHA256' = 5, 'ECDHE-RSA-AES256-GCM-SHA384' = 6, 'AES128-SHA' = 7, 'ECDHE-RSA-AES128-SHA' = 8, 'AES128-GCM' = 9))Engine = MergeTreeORDER BY (project)SETTINGS optimize_row_order = 1;
INSERT INTO pypi_optSELECT*FROM s3('https://storage.googleapis.com/clickhouse_public_datasets/pypi/file_downloads/sample/2023/{0..61}-*.parquet')SETTINGSinput_format_null_as_default = 1,input_format_parquet_import_nested = 1,min_insert_block_size_bytes = 0,min_insert_block_size_rows = 60_000_000;
SELECT`table`,formatReadableQuantity(sum(rows)) AS rows,formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed,formatReadableSize(sum(data_compressed_bytes)) AS compressed,round(sum(data_uncompressed_bytes) sum(data_compressed_bytes), 0) AS ratioFROM system.partsWHERE active AND (database = 'default') AND startsWith(`table`, 'pypi')GROUP BY `table`ORDER BY `table` ASC;┌─table────┬─rows─────────┬─uncompressed─┬─compressed─┬─ratio─┐1. │ pypi │ 1.01 billion │ 227.97 GiB │ 25.36 GiB │ 9 │2. │ pypi_opt │ 1.01 billion │ 227.97 GiB │ 17.52 GiB │ 13 │└──────────┴──────────────┴──────────────┴────────────┴───────┘
由 Auxten Wang 贡献
chDB 是 ClickHouse 的一种进程内版本,支持多种语言,尤其是 Python。它在今年早些时候加入 ClickHouse 家族,并在本周发布了 Python 库的 2.0 版本。
要安装该版本,您需要在安装时指定版本,如下所示:
pip install chdb==2.0.0b1
首先,我们生成一个包含 1 亿行的 CSV 文件:
import pandas as pdimport datetime as dtimport randomrows = 100_000_000now = dt.date.today()df = pd.DataFrame({"score": [random.randint(0, 1_000_000) for _ in range(0, rows)],"result": [random.choice(['win', 'lose', 'draw']) for _ in range(0, rows)],"dateOfBirth": [now - dt.timedelta(days = random.randint(5_000, 30_000)) for _ in range(0, rows)]})df.to_csv("scores.csv", index=False)
import pandas as pdimport chdbimport timedf = pd.read_csv("scores.csv")start = time.time()print(chdb.query("""SELECT sum(score), avg(score), median(score),avgIf(score, dateOfBirth > '1980-01-01') as avgIf,countIf(result = 'win') AS wins,countIf(result = 'draw') AS draws,countIf(result = 'lose') AS losses,count()FROM Python(df)""", "Vertical"))end = time.time()print(f"{end-start} seconds")
Row 1:──────sum(score): 49998155002154avg(score): 499981.55002154median(score): 508259avgIf: 499938.84709508wins: 33340305draws: 33334238losses: 33325457count(): 1000000000.4595322608947754 seconds
import pyarrow.csvtable = pyarrow.csv.read_csv("scores.csv")start = time.time()print(chdb.query("""SELECT sum(score), avg(score), median(score),avgIf(score, dateOfBirth > '1980-01-01') as avgIf,countIf(result = 'win') AS wins,countIf(result = 'draw') AS draws,countIf(result = 'lose') AS losses,count()FROM Python(table)""", "Vertical"))end = time.time()print(f"{end-start} seconds")
Row 1:──────sum(score): 49998155002154avg(score): 499981.55002154median(score): 493265avgIf: 499955.15289763256wins: 33340305draws: 33334238losses: 33325457count(): 1000000003.0047709941864014 seconds
x = {"col1": [random.uniform(0, 1) for _ in range(0, 1_000_000)]}print(chdb.query("""SELECT avg(col1), max(col1)FROM Python(x)""", "DataFrame"))avg(col1) max(col1)0 0.499888 0.999996
试试看,并告诉我们你的使用情况!
由 Artem Mustafin 贡献
有数学背景的用户可能对空间填充曲线的概念比较熟悉。在 24.6 版本中,我们增加了对 Hilbert 曲线的支持,以补充现有的 Morton 编码函数。这些曲线有助于加速某些查询,特别是在时间序列和地理数据中。
空间填充曲线是一种连续曲线,可以经过给定多维空间内的每一个点,通常在一个单位平方或立方体内,从而完全填充空间。这些曲线对很多人来说都非常吸引人,主要是因为它们挑战了我们直觉中一维线条无法覆盖二维区域或更高维体积的想法。最著名的例子包括 Hilbert 曲线和较早期的 Peano 曲线,二者都是通过迭代方式增加在空间内的复杂性和密度。空间填充曲线在数据库中有实际应用,因为它们能够有效地将多维数据映射到一维,同时保持局部性。
考虑一个二维坐标系,一个函数将任何点映射到一维线上,同时保持局部性,确保原空间中接近的点在该线上仍然接近。可以想象一个二维空间被分成四个象限,每个象限进一步分成四个,形成 16 个部分。这个递归过程虽然概念上是无限的,但在有限深度上更容易理解,例如深度 3,生成一个 8x8 的网格,有 64 个象限。该函数生成的曲线经过所有象限,保持原点在最终线上的接近性。
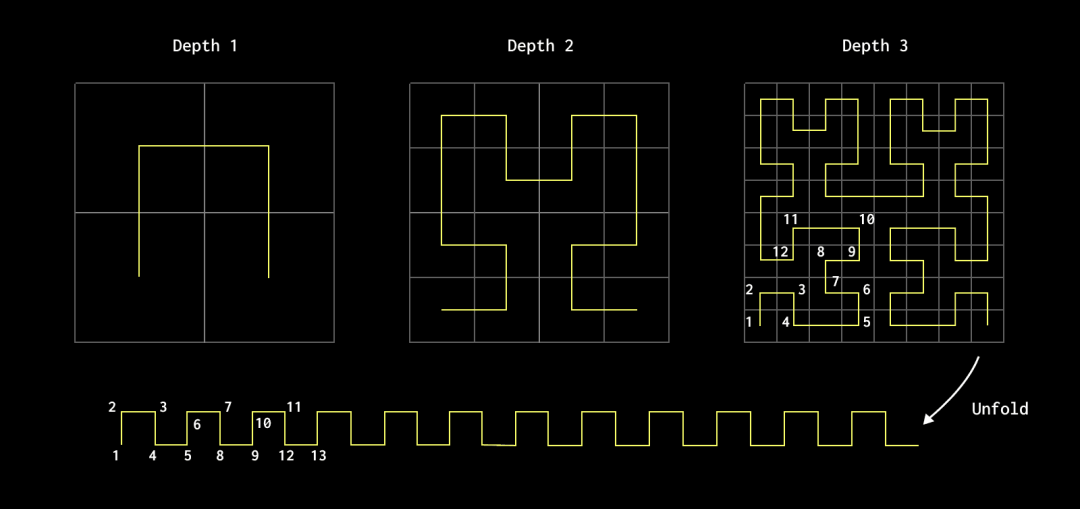
重要的是,递归和分割空间越深入,线上的点在其对应的二维位置上的稳定性越高。最终,这种曲线在无穷深度时可以完全“填满”空间。
用户可能熟悉来自 Delta Lake 等湖泊格式中的 Z-ordering 术语——也称为 Morton 顺序。这是另一种空间填充曲线,类似于上面的 Hilbert 例子,它也保留了空间局部性。ClickHouse 中的 mortonEncode 函数支持的 Morton 顺序,虽然局部性保留不如 Hilbert 曲线,但由于计算和实现更简单,在某些情况下更受欢迎。
对于空间填充曲线及其与无限数学的关系的精彩介绍,我们推荐这段视频。(https://www.youtube.com/watch?v=3s7h2MHQtxc)
那么这对优化数据库查询有什么用呢?
我们可以将多列有效地编码为单个值,通过保持数据的空间局部性,将结果值作为表中的排序顺序。这对于提高范围查询和最近邻搜索的性能非常有用,尤其当编码列在范围和分布上具有相似属性且具有大量不同值时。这些空间填充曲线的特性确保了高维空间中接近的值在相同的范围查询中会有相似的排序值,并属于相同的颗粒。因此,需要读取的颗粒更少,查询速度更快!
这些列不应有相关性——在这种情况下,传统的字典排序(如 ClickHouse 排序键使用的排序)更有效,因为按第一列排序会自然地对第二列排序。
虽然数值物联网数据(如时间戳和传感器值)通常满足这些属性,但更直观的例子是地理纬度和经度坐标。让我们看一个简单的例子,看看 Hilbert 编码如何加速这些类型的查询。
考虑 NOAA 全球历史气候网络数据,包含过去 120 年的 10 亿条天气测量数据。每行是一个时间点和站点的测量数据。我们在一个 2xcore r5.large 实例上进行以下操作。
我们稍微修改了默认架构,添加了 mercator_x 和 mercator_y 列。这些值通过对纬度和经度进行墨卡托投影得到,允许数据在二维表面上可视化。该投影通常用于将点投影到指定高度和宽度的像素空间中,如前几篇博客所示。我们使用它将坐标从 Float32 投影到无符号整数(使用最大 Int32 值 4294967295 作为高度和宽度),这是 hilbertEncode 函数所需的。
墨卡托投影是一种常用于地图的流行投影。它有许多优点,主要是它在局部尺度上保持角度和形状,使其成为导航的绝佳选择。它还具有恒定方位角(行进方向)为直线的优点,使导航变得简单。
CREATE OR REPLACE FUNCTION mercator AS (coord) -> (((coord.1) + 180) * (4294967295 360),(4294967295 2) - ((4294967295 * ln(tan((pi() 4) + ((((coord.2) * pi()) 180) 2)))) (2 * pi())))CREATE TABLE noaa(`station_id` LowCardinality(String),`date` Date32,`tempAvg` Int32 COMMENT 'Average temperature (tenths of a degrees C)',`tempMax` Int32 COMMENT 'Maximum temperature (tenths of degrees C)',`tempMin` Int32 COMMENT 'Minimum temperature (tenths of degrees C)',`precipitation` UInt32 COMMENT 'Precipitation (tenths of mm)',`snowfall` UInt32 COMMENT 'Snowfall (mm)',`snowDepth` UInt32 COMMENT 'Snow depth (mm)',`percentDailySun` UInt8 COMMENT 'Daily percent of possible sunshine (percent)',`averageWindSpeed` UInt32 COMMENT 'Average daily wind speed (tenths of meters per second)',`maxWindSpeed` UInt32 COMMENT 'Peak gust wind speed (tenths of meters per second)',`weatherType` Enum8('Normal' = 0, 'Fog' = 1, 'Heavy Fog' = 2, 'Thunder' = 3, 'Small Hail' = 4, 'Hail' = 5, 'Glaze' = 6, 'Dust/Ash' = 7, 'Smoke/Haze' = 8, 'Blowing/Drifting Snow' = 9, 'Tornado' = 10, 'High Winds' = 11, 'Blowing Spray' = 12, 'Mist' = 13, 'Drizzle' = 14, 'Freezing Drizzle' = 15, 'Rain' = 16, 'Freezing Rain' = 17, 'Snow' = 18, 'Unknown Precipitation' = 19, 'Ground Fog' = 21, 'Freezing Fog' = 22),`location` Point,`elevation` Float32,`name` LowCardinality(String),`mercator_x` UInt32 MATERIALIZED mercator(location).1,`mercator_y` UInt32 MATERIALIZED mercator(location).2)ENGINE = MergeTreeORDER BY (station_id, date)INSERT INTO noaa SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/noaa/noaa_enriched.parquet') WHERE location.1 < 180 AND location.1 > -180 AND location.2 > -90 AND location.2 < 90
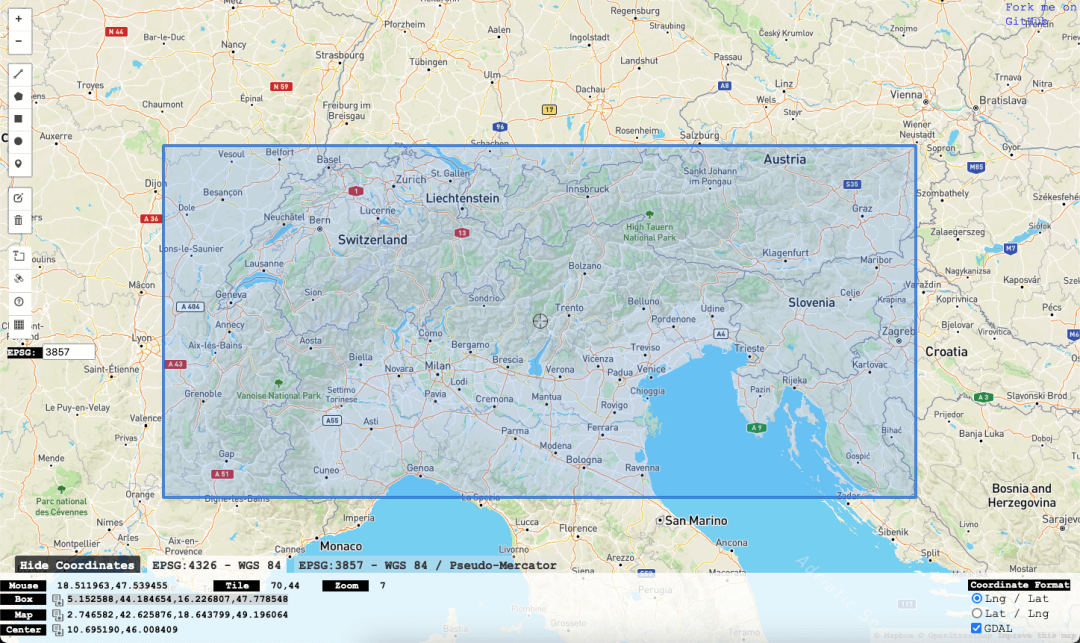
WITHmercator((5.152588, 44.184654)) AS bottom_left,mercator((16.226807, 47.778548)) AS upper_rightSELECTtoWeek(date) AS week,sum(snowfall) 10 AS total_snowfall,avg(snowDepth) AS avg_snowDepthFROM noaaWHERE (mercator_x >= (bottom_left.1)) AND (mercator_x < (upper_right.1)) AND (mercator_y >= (upper_right.2)) AND (mercator_y < (bottom_left.2))GROUP BY weekORDER BY week ASC54 rows in set. Elapsed: 1.449 sec. Processed 1.05 billion rows, 4.61 GB (726.45 million rows/s., 3.18 GB/s.)┌─week─┬─total_snowfall─┬──────avg_snowDepth─┐│ 0 │ 0 │ 150.52388947519907 ││ 1 │ 56.7 │ 164.85788967420854 ││ 2 │ 44 │ 181.53357163761027 ││ 3 │ 13.3 │ 190.36173190191738 ││ 4 │ 25.2 │ 199.41843468092216 ││ 5 │ 30.7 │ 207.35987294422503 ││ 6 │ 18.8 │ 222.9651218746731 ││ 7 │ 7.6 │ 233.50080515297907 ││ 8 │ 2.8 │ 234.66253449285057 ││ 9 │ 19 │ 231.94969343126792 │...│ 48 │ 5.1 │ 89.46301878043126 ││ 49 │ 31.1 │ 103.70976325737577 ││ 50 │ 11.2 │ 119.3421940216704 ││ 51 │ 39 │ 133.65286953585073 ││ 52 │ 20.6 │ 138.1020341499629 ││ 53 │ 2 │ 125.68478260869566 │└─week─┴─total_snowfall──┴──────avg_snowDepth─┘
CREATE TABLE noaa_lat_lon(`station_id` LowCardinality(String),…`mercator_x` UInt32 MATERIALIZED mercator(location).1,`mercator_y` UInt32 MATERIALIZED mercator(location).2)ENGINE = MergeTreeORDER BY (mercator_x, mercator_y)--populate from existingINSERT INTO noaa_lat_lon SELECT * FROM noaaWITHmercator((5.152588, 44.184654)) AS bottom_left,mercator((16.226807, 47.778548)) AS upper_rightSELECTtoWeek(date) AS week,sum(snowfall) / 10 AS total_snowfall,avg(snowDepth) AS avg_snowDepthFROM noaa_lat_lonWHERE (mercator_x >= (bottom_left.1)) AND (mercator_x < (upper_right.1)) AND (mercator_y >= (upper_right.2)) AND (mercator_y < (bottom_left.2))GROUP BY weekORDER BY week ASC--results omitted for brevity54 rows in set. Elapsed: 0.197 sec. Processed 42.37 million rows, 213.44 MB (214.70 million rows/s., 1.08 GB/s.)
顺便提一下,有经验的 ClickHouse 用户可能会尝试使用 pointInPolygon 函数。但不幸的是,这目前不能利用索引,导致性能较差。
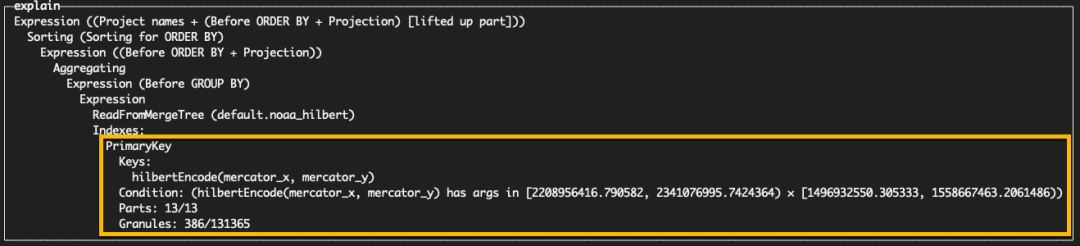
我们可以看到,通过使用 EXPLAIN indexes=1 子句,这个键在过滤颗粒方面相对有效,将读取的颗粒数减少到 5172。
EXPLAIN indexes = 1WITHmercator((5.152588, 44.184654)) AS bottom_left,mercator((16.226807, 47.778548)) AS upper_rightSELECTtoWeek(date) AS week,sum(snowfall) / 10 AS total_snowfall,avg(snowDepth) AS avg_snowDepthFROM noaa_lat_lonWHERE (mercator_x >= (bottom_left.1)) AND (mercator_x < (upper_right.1)) AND (mercator_y >= (upper_right.2)) AND (mercator_y < (bottom_left.2))GROUP BY weekORDER BY week ASC

然而,上述的二级排序无法保证邻近的点位于相同的颗粒中。Hilbert 编码可以提供这种特性,使我们能够更有效地过滤颗粒。为此,我们需要将表的 ORDER BY 修改为 hilbertEncode(mercator_x, mercator_y)。
CREATE TABLE noaa_hilbert(`station_id` LowCardinality(String),...`mercator_x` UInt32 MATERIALIZED mercator(location).1,`mercator_y` UInt32 MATERIALIZED mercator(location).2)ENGINE = MergeTreeORDER BY hilbertEncode(mercator_x, mercator_y)WITHmercator((5.152588, 44.184654)) AS bottom_left,mercator((16.226807, 47.778548)) AS upper_rightSELECTtoWeek(date) AS week,sum(snowfall) / 10 AS total_snowfall,avg(snowDepth) AS avg_snowDepthFROM noaa_hilbertWHERE (mercator_x >= (bottom_left.1)) AND (mercator_x < (upper_right.1)) AND (mercator_y >= (upper_right.2)) AND (mercator_y < (bottom_left.2))GROUP BY weekORDER BY week ASC--results omitted for brevity54 rows in set. Elapsed: 0.090 sec. Processed 3.15 million rows, 41.16 MB (35.16 million rows/s., 458.74 MB/s.)
为什么不直接对所有排序键使用 Hilbert 或 Morton 编码?
首先,mortonEncode 和 hilbertEncode 函数仅适用于无符号整数(因此需要使用前述的墨卡托投影)。其次,如果列之间有相关性,使用空间填充曲线不仅没有好处,还会增加插入和排序的时间开销。此外,如果仅按键的第一列过滤,经典排序更有效;而如果按第二列过滤,Hilbert(或 Morton 排序)编码平均会更快。

提示:我们正在开通国内购买渠道,请大家积极填写认证考试意愿到场问卷,敬请期待

好消息:ClickHouse Shanghai User Group第1届 Meetup 火热报名中,将于2024年7月20日在上海市徐汇区龙耀路8号阿里巴巴徐汇滨江园区X6-304 梅溪书院举行,扫码免费报名

征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


