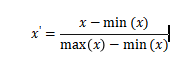点击上方“IT那活儿”公众号--专注于企业全栈运维技术分享,不管IT什么活儿,干就完了!!!
由于不同的特征之间,其量纲往往不同,变化区间也处于不同的数量级,若不进行归一化,可能导致某些指标被忽略,影响到数据分析的结果。为了消除特征之间的量纲影响,需要进行归一化处理,经归一化处理后,各个指标处于同一种数量级。归一化主要有最小-最大归一化,零均值归一化,非线性归一化三种类型。其中最小-最大归一化 是线性归一化,不改变数据分布,只是改变了数据分布范围。零均值归一化是均值为0,方差为1的标准化操作,数据分布发生了变化。1.1 线性归一化
如果max 和 min 不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定。
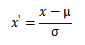
经过处理的数据符合标准正态分布,即均值为0,标准差为1。其中为所有样本数据的均值。为所有样本数据的标准差。经常用在数据分化比较大的场景,有些数值很大,有些很小。通过一些数学函数,将原始值进行映射。该方法包括log、指数,正切等。
一是缓解了内部协变量偏移,让每层的输出能够稳定在一个大致的区间内部。二是可以损失函数曲线变得平滑,更容易收敛,加速模型收敛。不同特征的量纲不同,导致损失函数会被某个特征所主导。每一层的激活函数和参数变化都会改变输入的分布,层数越高,输入分布改变越明显,如果一个神经层的输入分布发生了改变,那么其参数需要重新学习,这就使得高层需要不断去重新适应底层的参数更新。批归一化可以使每一层的输入分布都归一化,变换为均值为b、方差为的分布,也并不是严格的同分布,只是映射到了一个确定的区间范围,不论低层参数如何变化,高层输入保持相对稳定的分布。通过一个batch中的所有样本,计算均值和方差,进行归一化,然后学习两个参数,均值参数和方差参数。所以从整体上来说,BN做的事情就是为了让输出保持稳定。如果使用均值为0,方差为1的分布,会大大削弱了神经网络的表达能力,所以为了再恢复这部分表达能力,又用两个新的均值和方差参数把分布往回转化。这样就在两者之间做了一个平衡。
使用bach内部的均值和方差模拟全部样本中的均值和方差,如果batch size太小,在这个近似不成立,所以效果会很差。BN在NLP中的应用,是在batch内全部样本中的全部单词的第一个维度(或者第N个维度)做归一化。这个并不合理。C这个维度在图像中代表的是图片通道的情况,比如一个位置在RGB三个空间表示不同,而在词向量这块,还是认为在同一个语义空间的。其次在NLP这种场景天然带有一些不等长的情况,那么统计出来的均值和方差其实就不具备普适性,准确度也会降低。