




随着腾讯云 ES 8.8.1 及其后续版本 8.11.3、8.13.3 的推出,腾讯云 ES 在人工智能、向量搜索和自然语言处理(NLP)等领域功能得到了显著的增强。这些新功能为开发者提供了更多的可能性,尤其是在处理复杂的 NLP 任务时。
本文将探讨如何利用腾讯云 ES 的机器学习功能,实现一站式的 NLP 语义聚合,并通过 demo 来实践来这一过程。
语义聚合的挑战
利用 ES 机器学习功能的最佳实践
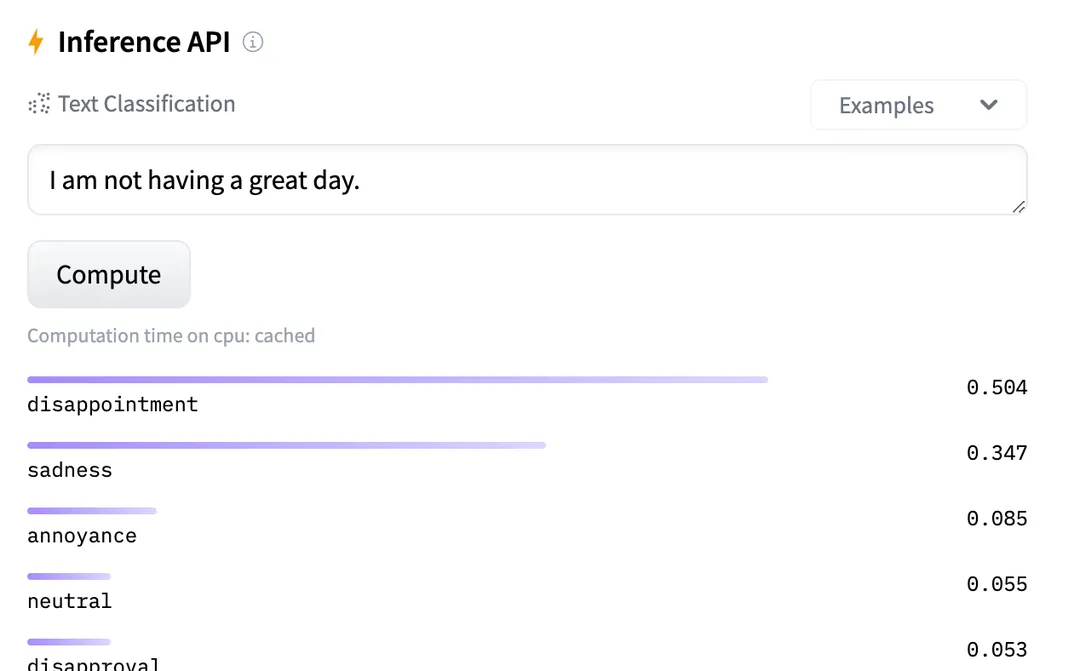

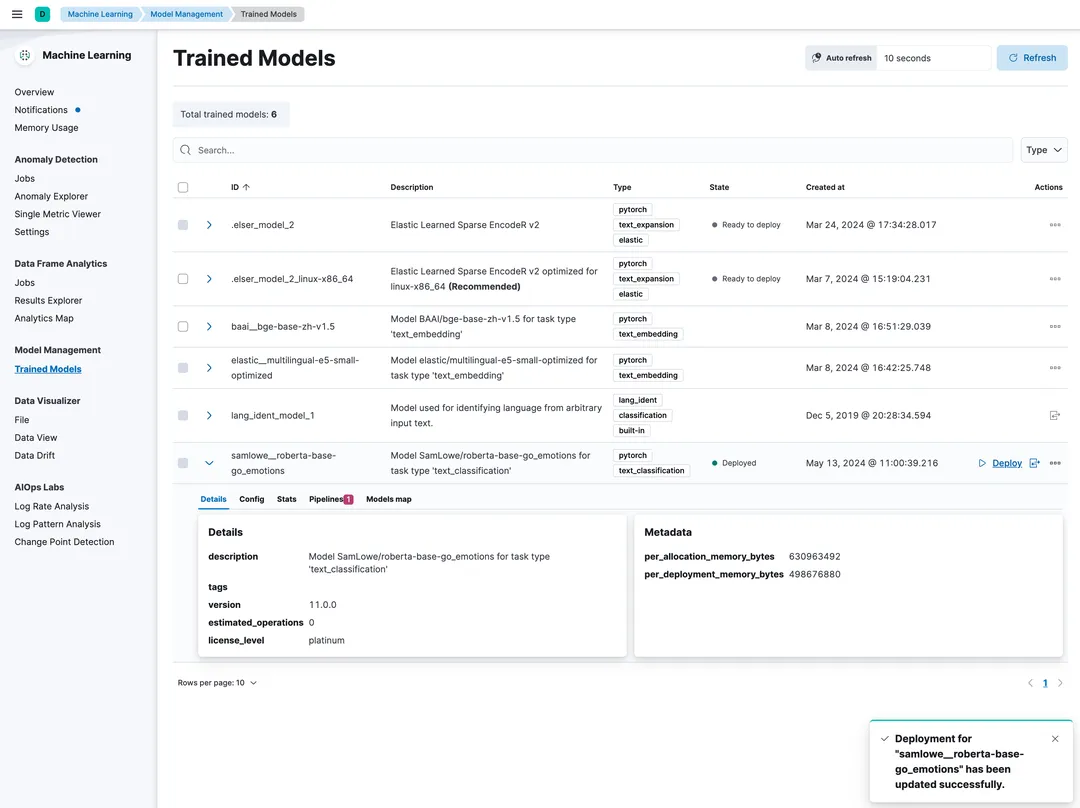
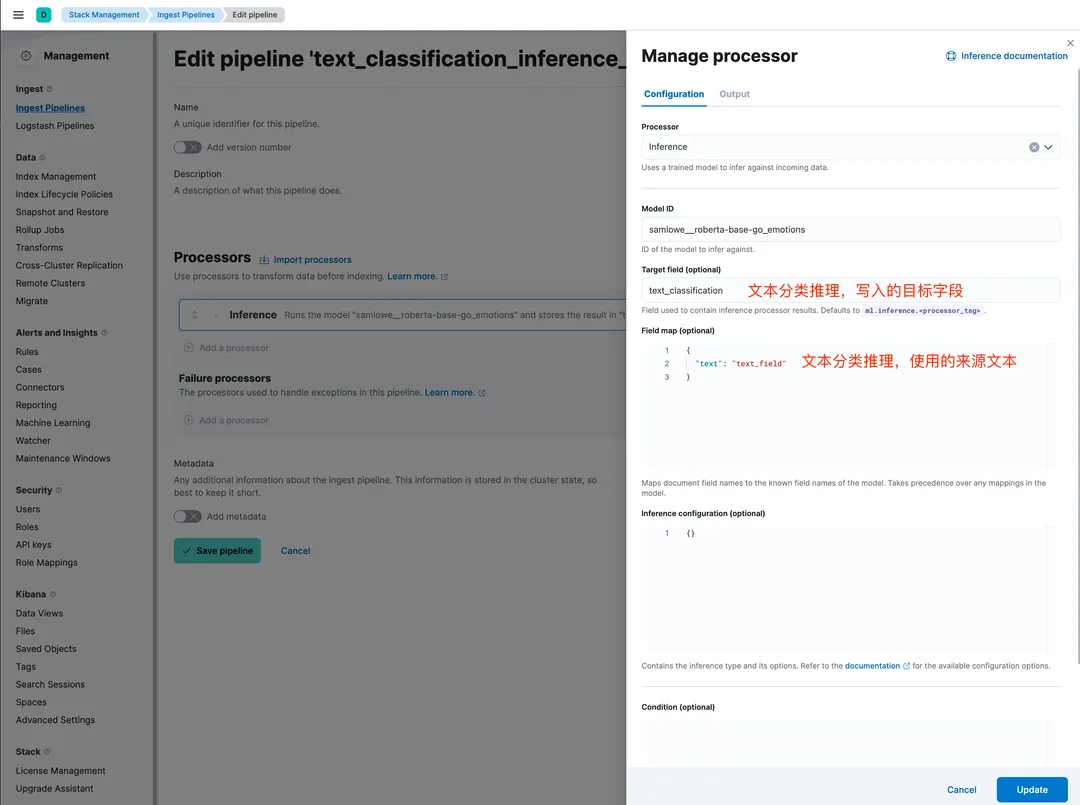
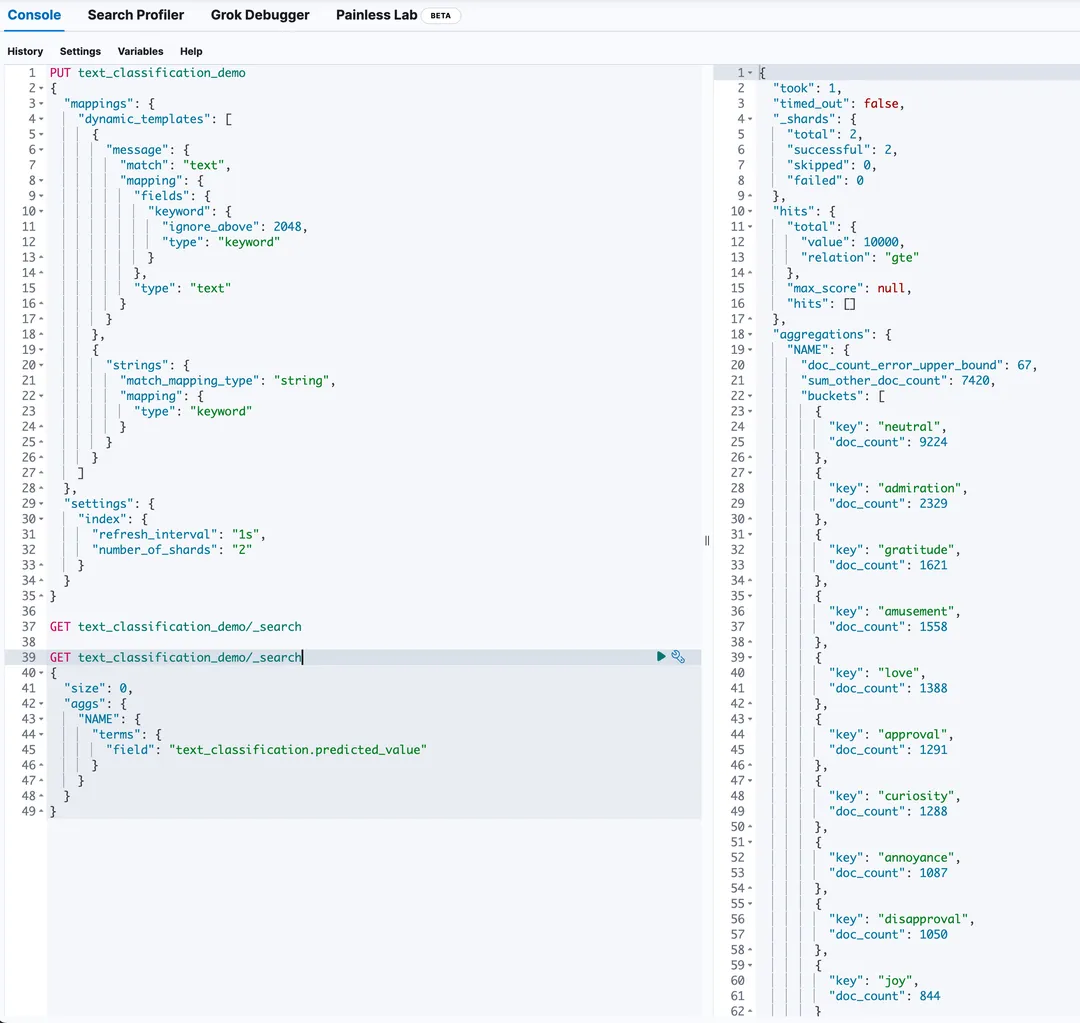
PUT text_classification_demo{"mappings": {"dynamic_templates": [{"message": {"match": "text","mapping": {"fields": {"keyword": {"ignore_above": 2048,"type": "keyword"}},"type": "text"}}},{"strings": {"match_mapping_type": "string","mapping": {"type": "keyword"}}}]},"settings": {"index": {"refresh_interval": "1s","number_of_shards": "2"}}}
import jsonfrom elasticsearch import Elasticsearchfrom elasticsearch.helpers import bulkfrom elasticsearch.helpers import BulkIndexErrorfrom datasets import load_datasetdataset = load_dataset("go_emotions", "simplified", split='train')es_username = 'elastic'es_password = 'elastic_123' # 修改ES密码es_host = '9.99.64.21' # 修改ES HOSTes_port = 9200es = Elasticsearch(hosts=[{'host': es_host, 'port': es_port, 'scheme': 'http'}],basic_auth=(es_username, es_password),)def prepare_data(dataset):for doc in dataset.select(range(40000)):yield {'_index': 'text_classification_demo','_id': doc['id'],'_source': json.dumps(doc)}def bulk_insert(data, chunk_size=100):try:success, _ = bulk(es, data, chunk_size=chunk_size, stats_only=True,pipeline="text_classification_inference_pipeline",request_timeout=600)print(f"Successfully indexed {success} documents.")except BulkIndexError as e:print(f"{len(e.errors)} document(s) failed to index.")for error in e.errors:print("Error details:", error)bulk_insert(prepare_data(dataset))

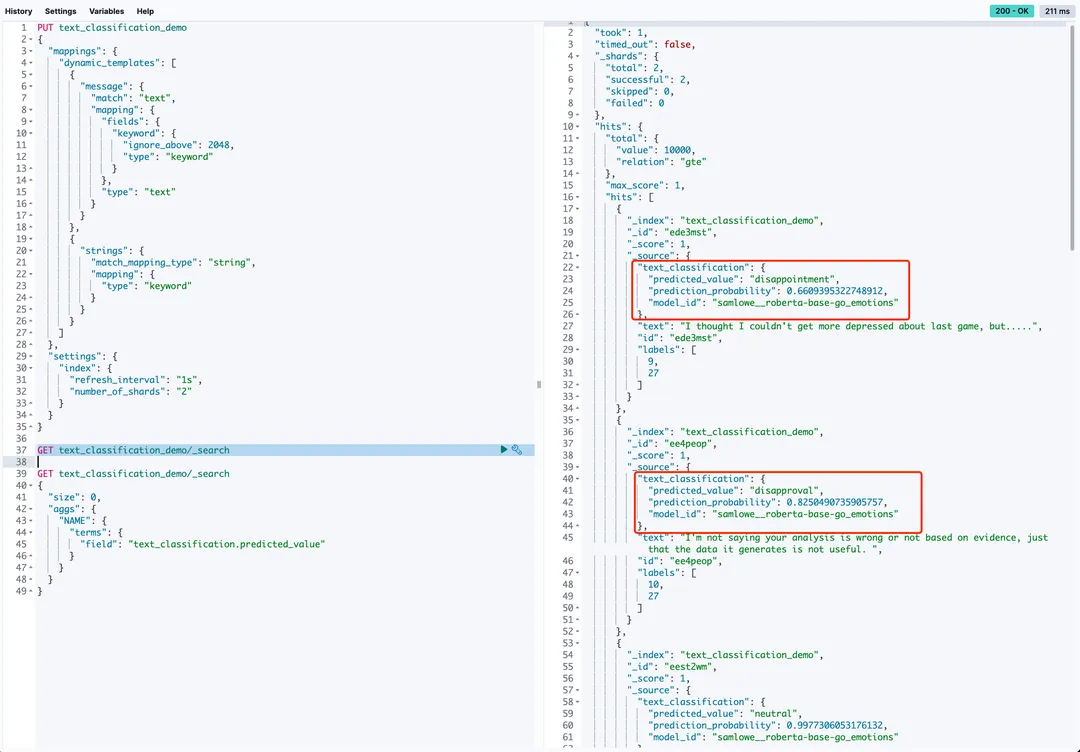
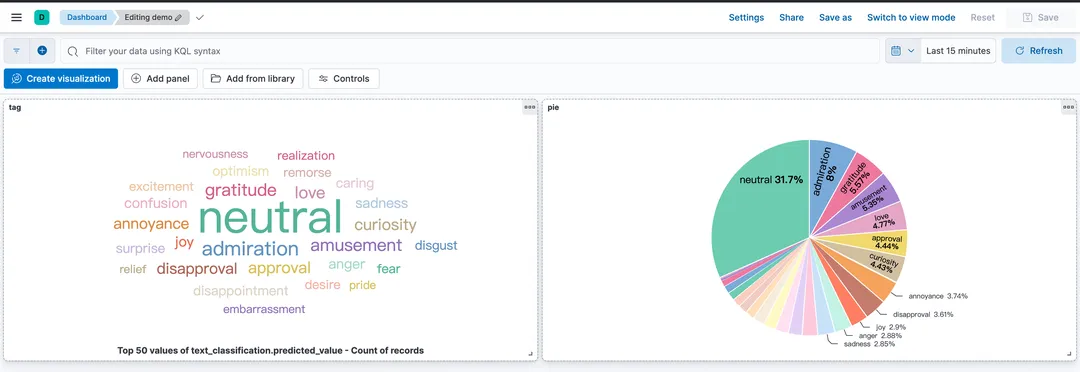
引申
如果场景简单,如本次 demo,使用开源的文本分类模型就可以实现。针对具体业务的场景,需要贴合业务的文本分类模型,可能需要根据具体业务场景定制化文本分类模型。这可能涉及到模型的训练或微调,以确保语义标签的准确性和覆盖范围。
ES 支持以下类型的NLP模型:
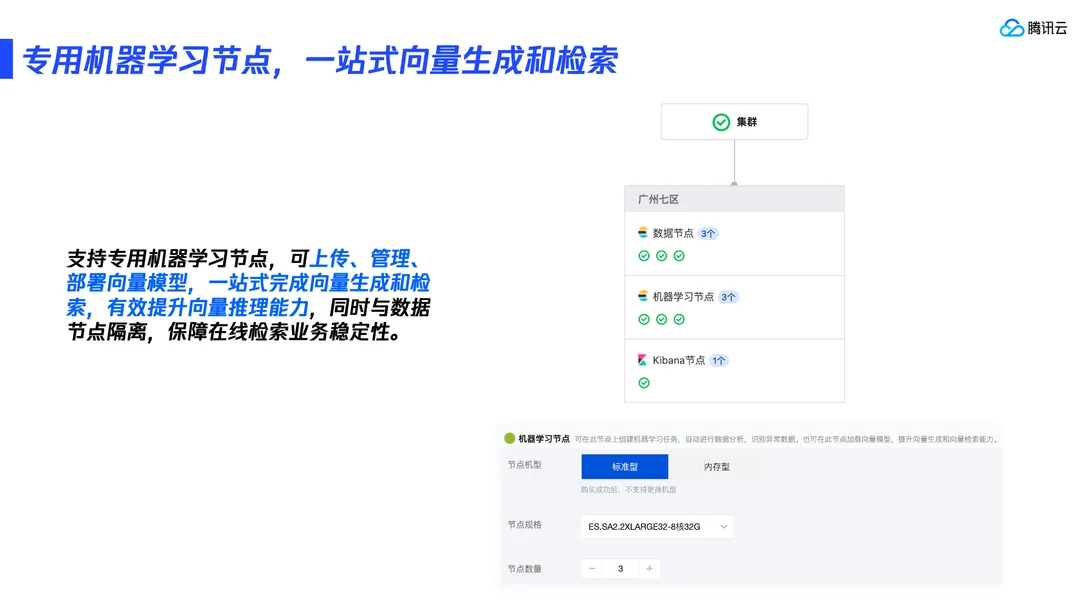
总结
关注腾讯云大数据公众号
邀您探索数据的无限可能

点击阅读原文,了解更多相关产品详情
↓↓↓
文章转载自腾讯云大数据,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
