




“ EM算法只需要有一些训练数据,定义一个最大化函数,剩下的事情就交给计算机了。经过若干次迭代,我们需要的模型就训练好了。这实在是太美妙了,这也许是造物主刻意安排的,所以我把它称作上帝的算法。--《数学之美》吴军 ”

01
—
EM算法聚类原理
1、抽象版
EM算法,期望最大化(expectation maximization),在概率模型中寻找参数最大似然估计或者最大后验估计的迭代计算方法,常应用于处理含有无法观测的隐藏变量的不完全数据(incomplete data)问题。
假设我们想要评估参数 A 和参数 B,在开始状态下二者都是未知的,并且知道了 A 的信息就可以得到 B 的信息,反过来知道了 B 也就得到了 A。可以考虑首先赋予 A 某个初值,以此得到 B 的估值,然后从 B 的估值出发,重新估计 A 的取值,这个过程一直持续到收敛为止。EM 算法经常用于聚类和机器学习领域中。
如果我们把潜在类别当做隐藏变量,样本看做观察值,就可以把聚类问题转化为参数估计问题。这也就是 EM 聚类的原理。
我们希望最终的聚类结果是:相近的点都被聚集到了一类中,这样同一类中各个点到中心的平均距离d较近,而不同类中心之间的平均距离D较远。我们希望的迭代过程是每一次迭代时,d比以前变小,而D变大。
2、看到这是不是好像懂了又好像没懂?我整整三个星期没有更新,是没有想明白,我看了不少关于EM算法的书、课程和网文,都没有让我能通俗去更好理解,总感觉断片,怎么都没办法把所有线索串联在一起。今晚在啃着雪糕的时候灵光一闪,一瞬间全部都清晰了。
为什么要贴上面4个这么抽象内容的点,是希望你们也能把4个点(特别是标黄内容)揉碎了内化吸收。
3、形象版
为了大家有个具象的理解,我又笨拙地亲手画了个图。
我们之前学K-means是通过距离来进行聚类的:算法-7 聚类:K-Means,见左下图。
EM算法聚类工作原理是通过预估未知的(不同类、同类不同点)生成概率比较后取大概率并迭代重估直到概率不变化来达到最终聚类。 过程如右下图所示:
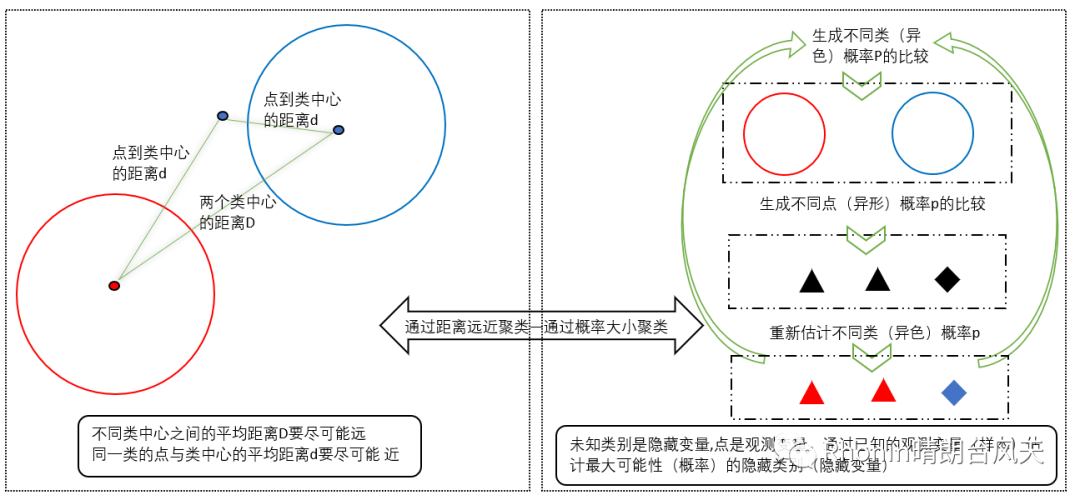
简单例子现状:
蓝圆圈(蓝类)和红圆圈(红类)、三角、菱形均有生成的概率。
生成的概率数值是未知的,怎么办?靠猜呗!
我们猜:
生成红类概率是0.5,那么生成蓝类的概率是1-0.5=0.5
猜红类生成三角概率是0.6,菱形概率是0.4
猜蓝类生成三角概率是0.5,菱形概率是0.5
我们计算:
1、那么三角到底是红类还是蓝类呢?分两步计算:
三角归属到红类的概率是:0.5*0.6=0.3
三角归属到蓝类的概率是:0.5*0.5=0.25
0.3>0.25,所以三角是归属到红类的,现在有两个三角,即红类是2
2、那么菱形到底是红类还是蓝类呢?同样分两步计算:
菱形归属到红类的概率是:0.5*0.4=0.2
菱形归属到蓝类的概率是:0.5*0.5=0.25
0.25>0.2,所以菱形是归属到蓝类的,现在有一个菱形,即蓝类是1
重新按结果生成预估,红类概率为2/3,蓝类概率为1/3
……
一直迭代红类和蓝类的概率不再发生变化。那么这个时候红类和蓝类的概率就是最大可能性,也就是我们想要得到的结果
4、总结:
EM 算法是一种求解最大似然估计的方法,通过观测样本,来找出样本的模型参数。(最大似然=最大可能性,最大似然估计=已知样本预估参数,样本=点,模型参数=不同类、同类不同点的生成概率)
EM迭代是存在收敛必然性,但是EM算法给出的是局部最佳解而非全局最佳解,除非目标函数是凸函数。
EM 算法是一个可以采用不同的模型的框架,常用有 GMM 高斯混合模型和 HMM 隐马尔科夫模型。
02
—
K-Means与EM

03
—
Python sklearn简介
EM 算法是一个聚类框架,所以你需要明确你要用的具体算法,比如是采用 GMM 高斯混合模型,还是 HMM 隐马尔科夫模型
1、引用:
from sklearn.mixture import GaussianMixture
2、创建:
gmm = GaussianMixture(n_components=1, covariance_type=‘full’, max_iter=100)
n_components:即高斯混合模型的个数,也就是我们要聚类的个数,默认值为 1。如果你不指定 n_components,最终的聚类结果都会为同一个值
covariance_type:代表协方差类型。一个高斯混合模型的分布是由均值向量和协方差矩阵决定的,所以协方差的类型也代表了不同的高斯混合模型的特征。协方差类型有 4 种取值:
a、covariance_type=full,代表完全协方差,也就是元素都不为 0;
b、covariance_type=tied,代表相同的完全协方差;
c、covariance_type=diag,代表对角协方差,也就是对角不为 0,其余为 0;
d、covariance_type=spherical,代表球面协方差,非对角为 0,对角完全相同,呈现球面的特性。
max_iter:代表最大迭代次数,EM 算法是由 E 步和 M 步迭代求得最终的模型参数,这里可以指定最大迭代次数,默认值为 100。
3、使用 fit 函数,传入样本特征矩阵,模型会自动生成聚类器,然后使用 prediction=gmm.predict(data) 来对数据进行聚类,传入你想进行聚类的数据,可以得到聚类结果 prediction。
4、采用 Calinski-Harabaz 指标评估
from sklearn.metrics import calinski_harabaz_scoreprint(calinski_harabaz_score(data, prediction))
——文章有参考数据分析实战-陈旸/数学之美-吴军

Python 系列-算法篇(起):算法-1 “高大上”的数据挖掘
Python 系列-基础篇(起):时隔一年重学Python
统计与概率系列(起):统计-1 统计与概率是门虐待学吗?
数据库与SQL(起):数据库与SQL-1 数据库系统
