






❝阅读本篇前可以先前往技术分享|StoneData 向量化计算(上)了解上下文
❞
二、深入了解SIMD API
SIMD(Single Instruction Multiple Data) 即单指令流多数据流,是一种采用一个控制器来控制多个处理器,同时对一组数据(又称“数据向量”)中的每一个分别执行相同的操作从而实现空间上的并行性的技术。简单来说就是一个指令能够同时处理多个数据。CPU 可能包含 3 类向量化寄存器和相关指令集:
SSE 指令集,128 位 XMM 寄存器 AVX 指令集,256 位 YMM 寄存器 AVX512 指令集,512 位 ZMM 寄存器
SSE/AVX 指令集允许使用汇编指令集去操作 XMM YMM ZMM 寄存器,但直接使用 AVX 汇编指令编写汇编代码并不是十分友好而且效率低下。因此,intrinsic function 应运而生。Intrinsic function 类似于 high level 的汇编,开发者可以无痛地将 instinsic function 同 C/C++ 的高级语言特性(如分支、循环、函数和类)无缝衔接。此外 Rust Java 也有向量化 API 的封装。
此外,主流语言在编译期或 JIT 有自动向量化优化。这允许将模式简单的代码自动转换为向量化执行方式。
2.1 执行原理
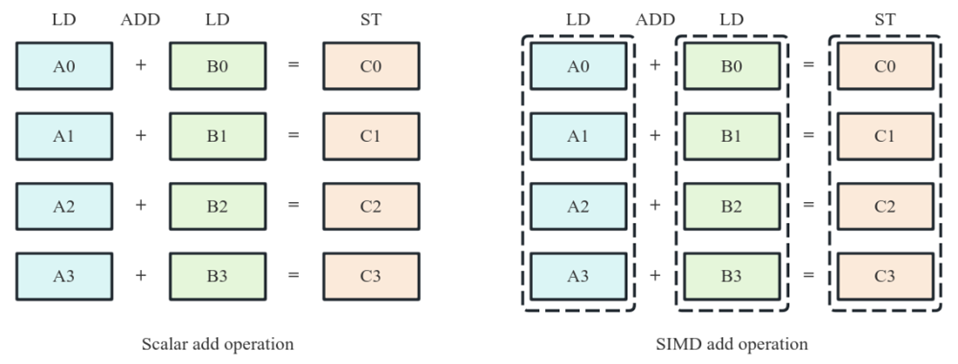
以加法指令为例,在 SISD(单指令流单数据流)架构计算机上,CPU 先执行一条指令,进行 A0 + B0 = C0 计算,再执行下一条指令,进行 A1 + B1 = C1 计算,按此顺序依次完成后续计算。四个加法计算需依次串行执行四次。而对于 SIMD 指令来说,CPU 只需执行一条指令,即可完成四个加法计算操作,四个加法计算操作并行执行。
我们可以利用 SIMD Intrinsic Function 完成较为复杂的数学运算和字符串处理,如下是字符串大小写转换代码:
private:
static void array(const UInt8 * src, const UInt8 * src_end, UInt8 * dst)
{
const auto flip_case_mask = 'A' ^ 'a';
#ifdef __SSE2__
const auto bytes_sse = sizeof(__m128i);
const auto src_end_sse = src_end - (src_end - src) % bytes_sse;
const auto v_not_case_lower_bound = _mm_set1_epi8(not_case_lower_bound - 1);
const auto v_not_case_upper_bound = _mm_set1_epi8(not_case_upper_bound + 1);
const auto v_flip_case_mask = _mm_set1_epi8(flip_case_mask);
for (; src < src_end_sse; src += bytes_sse, dst += bytes_sse)
{
/// load 16 sequential 8-bit characters
const auto chars = _mm_loadu_si128(reinterpret_cast<const __m128i *>(src));
/// find which 8-bit sequences belong to range [case_lower_bound, case_upper_bound]
const auto is_not_case
= _mm_and_si128(_mm_cmpgt_epi8(chars, v_not_case_lower_bound), _mm_cmplt_epi8(chars, v_not_case_upper_bound));
/// keep `flip_case_mask` only where necessary, zero out elsewhere
const auto xor_mask = _mm_and_si128(v_flip_case_mask, is_not_case);
/// flip case by applying calculated mask
const auto cased_chars = _mm_xor_si128(chars, xor_mask);
/// store result back to destination
_mm_storeu_si128(reinterpret_cast<__m128i *>(dst), cased_chars);
}
#endif
}
};
首行中申明了flip_case_mask = 'A' ^ 'a'
,位操作的依赖于大小写的 ASCII 编码特点:
| CHAR | CODE | BIN | CHAR | CODE | BIN |
|---|---|---|---|---|---|
| a | 97 | 0110 0001 | A | 64 | 0100 0001 |
| b | 98 | 0110 0010 | B | 65 | 0100 0010 |
| c | 99 | 0110 0011 | C | 66 | 0100 0011 |
| d | 100 | 0110 0100 | D | 67 | 0100 0100 |
| e | 101 | 0110 0101 | E | 68 | 0100 0101 |
大小写字母低四位都是相同的,只有高第三位不同。所以只要判定 CHAR 的 ASCII 码在 'a' ~ 'z'
or 'A' ~ 'Z'
区间,然后 XOR 上 0b0010_0000 即可完成大小写转换。for 循环的代码逻辑总结如下:
_mm_loadu_si128
从参数传入的初始地址中从内存加载这 128 bits,每个循环就并行处理这 128 bits 的数据_mm_and_si128(_mm_cmpgt_epi8(chars, v_not_case_lower_bound)
,_mm_cmplt_epi8(chars, v_not_case_upper_bound))
;_mm_cmpgt_epi8
和_mm_cmplt_epi8
是对 chars 求出大于等于 'a' 和小于等于 'z' 的掩码,_mm_and_si128
对两个掩码合并。其中v_not_case_lower_bound = _mm_set1_epi8('a' - 1)
;v_not_case_upper_bound = _mm_set1_epi8('z' - 1)将 v_flip_case_mask
与 上一步的掩码合并,得到需要被转换大小写的xor_mask然后将 xor_mask
与chars
数据进行 XOR 计算,得到被转换大小写后的cased_chars最后将 cased_chars
寄存器中的数据拷贝到dst
中
2.2 最佳实践
由于向量化指令的丰富性和编程语言的自由度,实现某个函数可以有很多算法。选择更好的算法和更高效的向量指令可以提高函数的整体性能,这里我们将介绍一些向量化编程中的最佳实践。
2.2.1 垂直计算优于水平计算
垂直计算(vertical operations)是指对于一个给定向量化寄存器,寄存器上每一位数据的计算不依赖与该寄存器上的其它位。例如两个 i32x4(及表示 存储 4 个 i32 数据的 128 bits 宽的寄存器)相加、对 i32x4 取反,这种操作称为垂直计算。例如对 i32x4 上 4 个 i32 求和,这种操作即是水平计算。
在计算中尽可能优先做垂直计算,减少做水平计算。例如下面是对 f32 数组求和的两个例子:
fn fast_sum(x: &[f32]) -> f32 {
assert!(x.len() % 4 == 0);
let mut sum = f32x4::splat(0.); // [0., 0., 0., 0.]
for i in (0..x.len()).step_by(4) {
sum += f32x4::from_slice_unaligned(&x[i..]);
}
sum.sum()
}
fn slow_sum(x: &[f32]) -> f32 {
assert!(x.len() % 4 == 0);
let mut sum: f32 = 0.;
for i in (0..x.len()).step_by(4) {
sum += f32x4::from_slice_unaligned(&x[i..]).sum();
}
sum
}
fast_sum 中构建了 f32x4 的累加器,x 数组中的数据利用 f32x4 的寄存器不断累加到 sum 中,在循环体中每一步都是垂直计算。直到最后一步才对累加器求和(水平计算)。
slow_sum 中则是将 x 数组利用 f32x4 寄存器依次求和(水平计算),然后累加至 f32 中。在业界常见的硬件上做大量测试,使用垂直计算方式的 fast_sum 要比使用水平计算的 slow_sum 快 2.7 倍以上。
2.2.2 强制对齐与填充
在做向量化计算时,内存地址偏移量尽量按照 64 bytes 对齐和填充。上文讲到,内存对齐可以不仅减少读内存单元的次数,而且将对齐的数据单元加载到向量化寄存器也会更高效。在 intel performance guide 中讲到,将 64 bytes 对齐的数据加载到 512 bits 宽的 ZMM 寄存器中使用的 CPU cycle 最少。
另外,在编程时需要向量化计算的数据默认强制对齐可以省去对齐边界检查、处理对齐前缀、对齐后缀数据时的操作。在 Apache Arrow 项目中,为了达到最好的计算性能,基本类型数组均是强制 64 bytes 对齐与填充。
2.2.3 内存池化与复用
对数据库而言,向量化计算往往发生在存储层和计算层。在该场景下有 TB 级甚至 PB 级的数据需要被扫描和处理。对于低级语言,频繁的调用 malloc free 函数会造成内核态和用户态的频繁切换,这会降低程序的运行效率。对于类似 Java 这样有 VM 的语言,频繁的申请和释放数组对垃圾回收会造成很大的压力。
设计一套工业级别内存池需要尝试解决无锁化、热高速缓存复用、高速缓存空间浪费、L1 Cache 污染等等问题,在这里就不再展开。
三、Java自动向量化
在介绍 Java 自动向量化以及最佳实践之前,我们先看看 Java Intrinsics。如果一个 Java 方法被标记位 @HotSpotIntrinsicCandidate,在 JVM 运行期间该方法可能会被替换成基于汇编的硬编码或者基于编译器中间表示(例如 LLVM IR),这可以极大的提高性能。例如下面这个方法:
@IntrinsicCandidate
public static boolean equals(byte[] a, byte[] a2) {
if (a==a2)
return true;
if (a==null || a2==null)
return false;
int length = a.length;
if (a2.length != length)
return false;
return ArraysSupport.mismatch(a, a2, length) < 0;
}
在运行期可能会被 JVM 替换成更高效的汇编代码。在 Java 中有一些被标记 Intrinsics 方法是被高度向量化优化的代码,通常有更好的性能。比如下图是 Array 相关的高效方法:
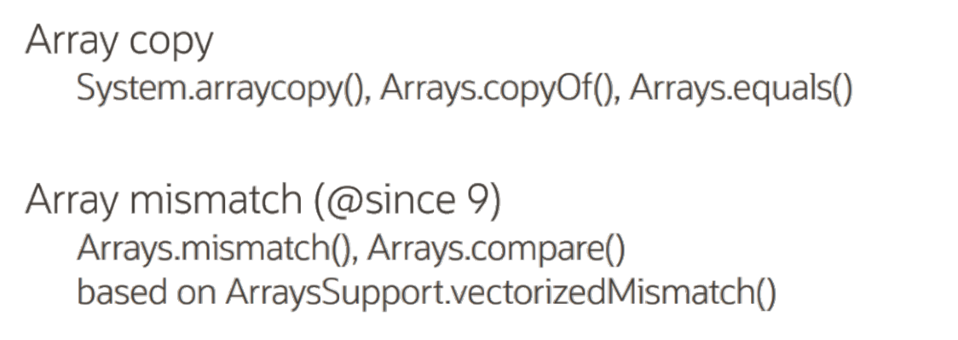
通常建议首先考虑 JDK 中 Intrinsics 的方法,其次再考虑使用自动向量化或 Vector API。
3.1 自动向量化
如下图是一个简单的 for 循环,对 B、C 数组依次求和至 A 数组中。在 JVM 运行期,JIT 开始工作将 Java字节码编译成更高效的、使用向量化指令的汇编代码。
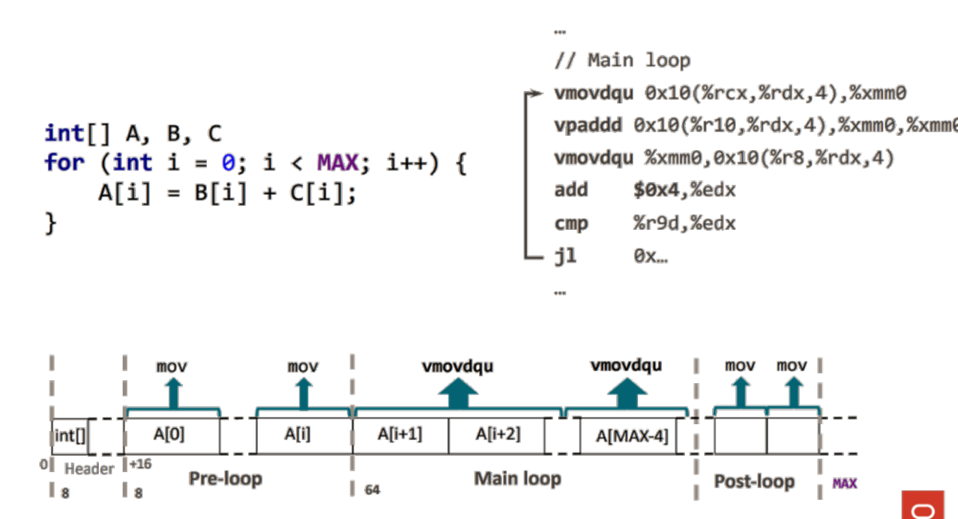
由于自动向量化在编译时,需要考虑 B、C 指针未对齐的情况。算法将数据按照寄存器宽度对齐并拆分成 3 部分,所以编译后的代码也由如下 3 部分构成:
利用 SISD 指令处理前序数据(Pre-loop) 利用 SIMD 指令,循环处理内存对齐后的数据(Main loop) 利用 SISD 指令处理后续数据(Post-loop)
在 OpenJDK 中有一个 Superword 子项目,目前还在持续迭代过程中。该项目旨在提高 JIT 生成汇编代码的性能。

3.2 验证
在 Java 启动参数中增加 -XX:+UnlockDiagnosticVMOptions -XX:CompileCommand=print,*XXClass.xxMethod,并在 $JDK_HOME/lib/ 中放入 hsdis-amd64.so 库。运行代码后,即可打印出 XXClass.xxMethod 的汇编代码
/**
* Run with this command to show native assembly: <br/>
* java -XX:UnlockDiagnosticVMOptions \
* -XX:CompileCommand=print,VectorizationMicroBenchmark.square \
* VectorizationMicroBenchmark
*/
public class VectorizationMicroBenchmark {
private static void square(float[] a) {
for (int i=0; i<a.length; i++) {
a[i] = a[i] * a[i];
}
}
// Repeatedly invoke the square method under test. This will cause
// the JIT compiler to optimize the method
public static void main(String[] args) {
float[] a = new float[1024];
for (int i=0; i<1000 * 1000; i++) {
square(a);
}
}
}
0x...ac54: vmovdqu 0x10(%rbx,%rbp,4),%ymm0 ;*faload {reexecute=0 rethrow=0 return_oop=0};
- VectorizationMicroBenchmark::square@9 (line 11)
0x...ac5a: vmulps %ymm0,%ymm0,%ymm0
0x...ac5e: vmovdqu %ymm0,0x10(%rbx,%rbp,4) ;
*fastore {reexecute=0 rethrow=0 return_oop=0};
- VectorizationMicroBenchmark::square@14 (line 11)
可以看到汇编指令中包含 vmovdqu、vmulps 等 AVX 指令集。我们可以通过观察 JIT 生成的汇编指令来证明某函数是否被向量化优化。
3.3 最佳实践
自动向量化很难命中,非常难。所以开发者需要非常注意编码风格,以协助编译器完成自动向量化。2000年,Samuel Larsen and Saman Amarasinghe 发表了一篇论文《Exploiting Superword Level Parallelism with Multimedia Instruction Sets》,其中提到了可以将复杂的标量运算转为向量化指令。但是运算中不得包含控制指令(if switch等),有兴趣的可以关注 JDK Superword。我们也总结了一些实用的最佳实践:
面向 Page Block 编程,不要面向 Iterator Row 编程。Block 通常表示一列中的一批数据,数据排列是紧凑和连续的,这种内存布局是向量化计算的基础;
for 循环要尽量下推,每个 for 循环做最简单的事情;
如果 for 循环包含控制指令和标量计算指令,可以尝试将 for 循环拆分为两个 for 循环(需要benchmark验证两个版本性能差异),让标量计算实现自动向量化优化;
如果有短的 for while 循环,尝试将消除循环(参考 variant 编码算法)。循环包含的分支判断可能会导致分支预测失败;
如果自动优化不生效,尝试手工循环展开(loop unrolling);
用三目运算符代替简单的 if ,三目运算符可以绕过 jmp 指令;
尽量做垂直计算(Vectical),少做水平计算(Horizontal)。水平运算很难被自动向量化优化,建议做水平运算是手写向量化代码。
❝下面是 2 个水平计算的实现,1 个是简单的 for 循环累加,另一个是利用向量化垂直计算最后再求和:
❞
@Benchmark
public static int sum_vectorized(State state) {
IntVector sum = IntVector.broadcast(IntVector.SPECIES_256, 0);
int loopCount = state.arr.length/8;
for (int i = 0; i < loopCount; i++) {
IntVector vector = IntVector.fromArray(IntVector.SPECIES_256, state.arr, i*8);
sum = sum.add(vector);
}
return sum.reduceLanes(VectorOperators.ADD);
}
@Benchmark
public static int sum(LoopCount.State state) {
int sum = 0;
for (int a : state.arr) {
sum += a;
}
return sum;
}
❝通过 JMH benchmark 我们发现向量化的版本比 for 循环快 10 倍。
❞
Benchmark Mode Cnt Score Error Units
LoopCount2.sum thrpt 5 496405.269 ± 2024.842 ops/s
LoopCount2.sum_vectorized thrpt 5 4122008.390 ± 66444.053 ops/s
有时候自动向量化往往不够聪明,它只是公式化的将代码翻译成向量化版本,难以考虑到有更好的向量化指令可以等价替换。例如在矩阵、多项式、CNN 卷集计算中经常用到的 FMA 公式:c = c+(a*b),可以仅使用一个 fma 的向量化指令完成计算,比使用加法和乘法运算要高效一倍。下图给出了 FMA 的 Java 版代码和自动向量化优化的性能对比。
public static float vectorFMA(float[] a, float[] b) {
var SPECIES = FloatVector.SPECIES_PREFERRED;
var upperBound = SPECIES.loopBound(a.length);
var sum = FloatVector.zero(SPECIES);
var i = 0;
for (; i < upperBound; i += SPECIES.length()) {
var va = FloatVector.fromArray(SPECIES, a, i);
var vb = FloatVector.fromArray(SPECIES, b, i);
sum = va.fma(vb, sum);
}
var c = sum.reduceLanes(VectorOperators.ADD);
for (; i<a.length; i++) { // cleanup tail of the vector loop.
c += a[i] * b[i];
}
return c;
}
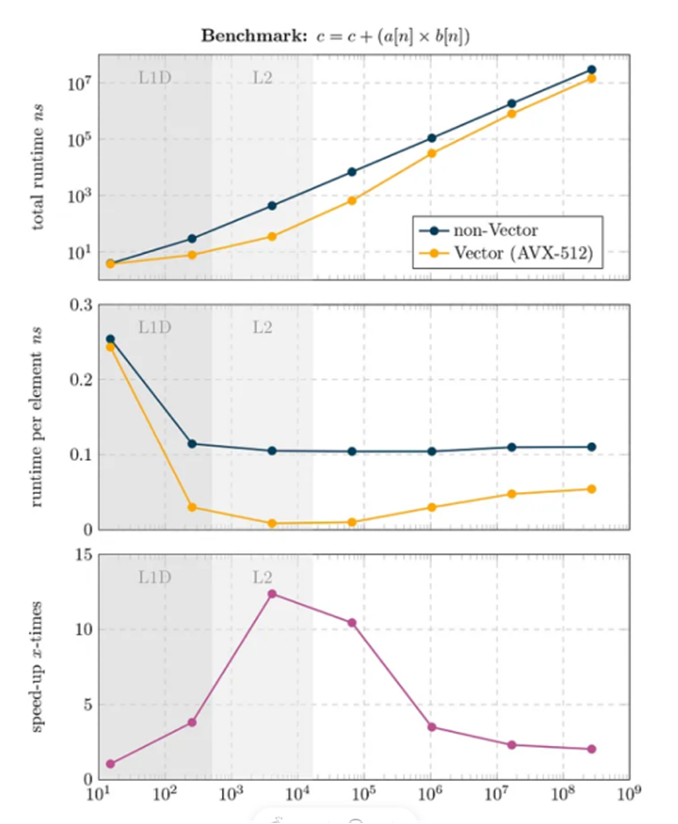
3.4 最坏实践
通过上面的例子我们看到,错误的写法会导致无法命中自动向量化,性能下滑过多是不能被接受的。我们也整理了一些 Bad practice 供大家参考:
迭代数据时前后依赖,比如数组 A 在本次迭代依赖数组A的上次的值
public void readAfterWrite() {
for (int i = 1; i < N; i++) {
a[i] = a[i-1] + b[i];
}
}
没有规律的数组下标、随机访问某个数组
for (int i=0; i<N; i++) {
a[c[i]] = b[d[i]];
}
不支持的循环结构,如循环体中访问复杂类型数组、调用某些非标量函数、非SVML(short vector math library)函数
for (int i=0; i<N; i++) {
a[i] = foo(b[i]);
}
在循环体内执行聚合操作,如下图:

对数组求和的代码只能做循环展开优化,不能实现自动向量化优化。
StoneData 中通过大量运用向量化技术,实现了高性能、低延迟的效果,以上内容是 StoneData 向量化计算的全部分享,希望对大家理解向量化计算有所帮助。
关于石原子科技
石原子科技成立于 2021 年 10 月, 拥有国内顶级的数据库人才与专家,专注于企业级实时数据仓库和 MySQL 实时 HTAP 数据库的研发与应用,依托云中立的数据技术进行产品设计,致力于为客户提供大规模、高性能、低成本的一站式实时数据分析服务。
石原子科技坚持精细布局、自主创新的产品研发路线,打造了三款标杆产品:

业内首个单机内核开源、行列混存+内存计算架构的一体化 MySQL HTAP 数据库 StoneDB:使用 MySQL 的用户,通过 StoneDB 可以实现 TP+AP 混合负载,分析性能提升 10 倍以上显著提升,不需要进行数据迁移,也无需与其他 AP 集成,弥补 MySQL 分析领域的空白,形成实时在线数据就近分析。

基于全场景的新一代高性能、低成本的离在线一体化实时数仓 StoneData:高度兼容 MySQL 语法,毫秒级更新,亚秒级查询,满足准实时和实时分析需求,一体化架构将实时和离线融合,减少数据冗余和移动,具有简化技术栈架构的能力;实现业务与技术解耦,支持自助式分析和敏捷分析;无论是数据湖中的非结构化或半结构化数据,还是数据库中的结构化数据,都可使用 StoneData 构建企业的数据分析平台,同时完成高吞吐离线处理和高性能在线分析,实现降本增效。
基于容器、IAC 等技术的一站式数据库管理服务 StoneDMP:集数据管理、结构管理、用户授权、安全审计、数据趋势、数据追踪、BI 图表、性能与优化和服务器管理于一体的数据管理服务。
成立至今,公司已积累了上千位用户,种子客户达 300 多家,取得 30+ 项软件著作权,成功申请并获准通过了 10+ 项技术专利,分别获评浙江省级、国家级科技型中小企业。
石原子科技积极参与中国数据库产业建设,目前已经成为中国信通院分布式系统稳定性实验室成员单位、中国通信标准化协会(CCSA)大数据技术标准推进委员会(TC601)全权成员单位、中国信通院科技制造开源社区成员单位、中国信通院数据库应用创新实验室成员单位、国家信创工作委员会技术活动单位、浙江省信创联盟会员单位、上海市软件行业协会团体会员、北京信创工委会会员单位,先后参与起草多项国家级和行业级标准的编写工作。产品已经通过了中国信通院分布式分析型数据库基础能力专项评测、信息安全管理体系认证,并与主流服务器、操作系统、中间件等国产化软硬件生态体系进行全面兼容。

