





数据库结合现代 CPU 主要优化方向
在我们直观的认识中,处理器就是那个按着编译好的代码指令,不断顺序重复着取指、译码、执行操作的单调而可靠的机器。事实上,现代处理器对待代码指令的处理方式,早已不再是表面上看起来的那么规矩,对不同形式的代码,它将可能呈现不同的运行策略。
01

超标量
可以在每个时钟周期执行多个操作的处理器称为“超标量处理器”。现代处理器主要从两个方面实现超标量处理:
多个并行的功能单元。这些单元能同时执行相同或不同的指令,如 TI 的 C64X+ 架构就配置了8个并行功能单元,分别负责乘加、逻辑、存取等操作。VLIW(Very Long Instruction Word) 超长指令集被设计来给这多个功能单元进行指令分发;Intel IA-64 之后,目前该技术基本已经偃旗息鼓; SSE (Streaming SIMD Extensions, 流SIMD指令扩展 ),SIMD 即 Single-In-struction,Multiple Data (单指令多数据)。通过扩展额外的矢量处理功能单元以及矢量寄存器等,可以实现单个指令控制多路相同的计算,如一次做8个 Byte 的数据存取 ,又或是一次做8个16x16乘法。Intel 目前主要的 SIMD 指令集有 MMX,SSE,AVX, AVX-512,其对处理的数据位宽分别是:
64位 MMX 128位 SSE 256位 AVX 512位 AVX-512
02
高速缓存
Level | cache size | CPU cycles | Share Level |
1 | L1d 256 KiB L1i 256 KiB | 3-4 cycles | 逻辑核心独占 |
2 | 4 MiB | 10-20 cycles | 同物理核上的逻辑核心共享 |
3 | 16 MiB | 40-45 cycles | 所有核心共享 |
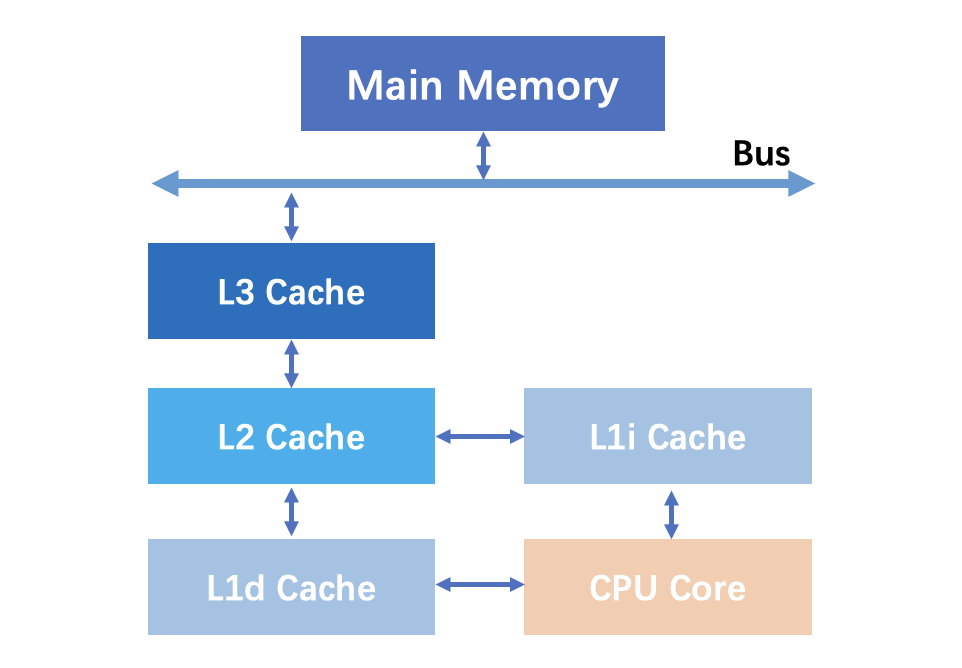
数据从 RAM 加载 L3 缓存,然后是 L2 ,最后是 L1 。当处理器正在寻找执行操作的数据时,它首先尝试在 L1 高速缓存中找到它。如果 CPU 能够找到它,则该条件称为缓存命中。然后它继续在 L2 中找到它,然后在 L3 中找到它。如果找不到数据,它会尝试从主存储器访问它。这称为缓存未命中。
缺失处罚是由于缓存未命中所需要的额外时间开销。对L1高速缓存来说,命中时间的数量级是几个时钟周期;L1缺失需要从L2得到服务的处罚,通常是数10个周期;从L3得到服务的处罚为50个周期;从主存得到服务的处罚为200个周期!
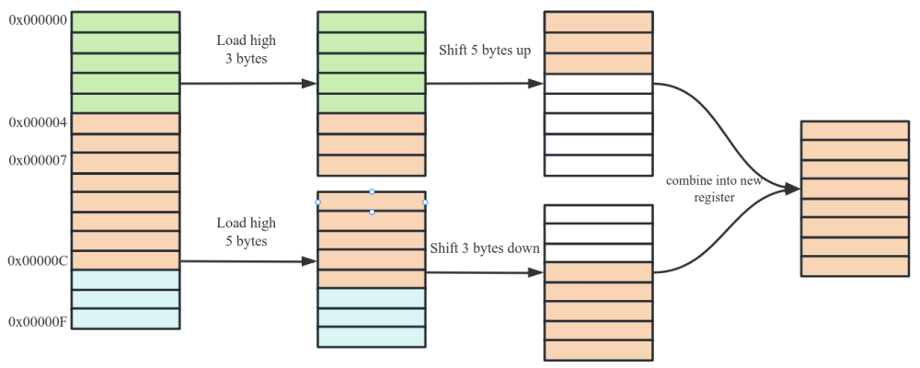
const uintptr_t pval = reinterpret_cast<uintptr_t>(p);const uint8_t* x = reinterpret_cast<const uint8_t*>(((pval + 3) >> 2) << 2);if (x <= e) {// Process bytes until finished or p is 4-byte alignedwhile (p != x) {STEP1;}// Process bytes 16 at a timewhile ((e-p) >= 16) {STEP4; STEP4; STEP4; STEP4;}// Process bytes 4 at a timewhile ((e-p) >= 4) {STEP4;}// Process the last few byteswhile (p != e) {STEP1;}
03
分支预测、投机执行
public static void countUnsortedArr() {int cnt = 0;for (int i=0; i<MAX_LENGTH; i++) {if (arr[i] < THRESHLOD) {cnt++;}}}public static void countSortedArr() {int cnt = 0;for (int i=0; i<MAX_LENGTH; i++) {if (arrSotred[i] < THRESHLOD) {cnt++;}}}
public static void count2() {int cnt = 0;for (int i=0; i<MAX_LENGTH; i++) {cnt += arr[i] < THRESHLOD ? 1 : 0;}}
04
while ((e - p) > kPrefetchHorizon) {prefetch next 64 bytesRequestPrefetch(p + kPrefetchHorizon);Process 64 bytes at a time.STEP16;STEP16;STEP16;STEP16;}
05
循环展开
对于一段常规的 for 循环而言,一次循环会经历3个步骤:
// 优化前for (int i=0; i<n; i++)Stmt(i);// 优化后if (n > 0) {for (int i=0; i+3<n; i+=4) {Stmt(i);Stmt(i+1);Stmt(i+2);Stmt(i+3);}switch(i % 4) {case 3:Stmt(n-3);case 2:Stmt(n-2);case 1:Stmt(n-1);}}
Why? - Compiler pragmas https://arxiv.org/abs/1805.03374 - Optimization heuristics - Loop Autotuning https://github.com/kavon/atJIT
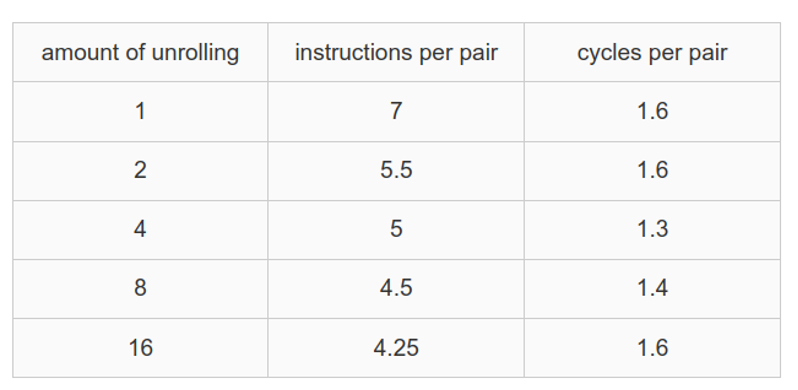
很明显可以得出,假设被次执行循环体需要 N 个 CPU Cycle,执行循环体的有效逻辑是整个 for 循环的 N/(N+2) 。当 N 越小,for 循环效率越低下。所以循环展开是增加每次循环体的执行次数,提高有效代码比例达到提升执行效率的目的。现代的编译器也会自动的做循环展开优化,上图是 LLVM 的循环自动展开优化。值得注意的是循环展开将增加代码体积,特别对于循环体较大的代码,循环展开反而会降低性能。
06
内联优化
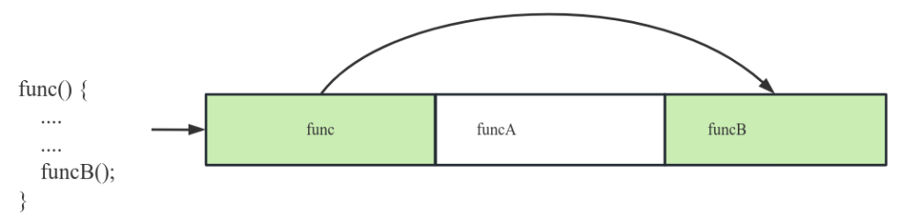
在介绍内联前,我们先要了解代码空洞的概念。如下图一段程序编译后,二进制可执行文件中依次包含 func funcA funcB 函数。在执行 func 函数时调用了 funcB 函数,此时需要 CPU 跳过一段内存空间加载并执行 funcB 函数。在本次执行过程中,我们称跳过的部分为 代码空洞。在执行过程中代码空洞越小,代码指令加载效率越高。
内联是指在编译器将函数内容展开到调用方的函数体中,这是一种解决代码空洞的方法。某个方法是否内联需要充分考虑,比如某个函数在低频的分支中调用,内联反而会加剧高频分支路径的空洞。内联还会造成代码膨胀,不推荐过长的函数内联到其它函数中。
07
列存与向量化
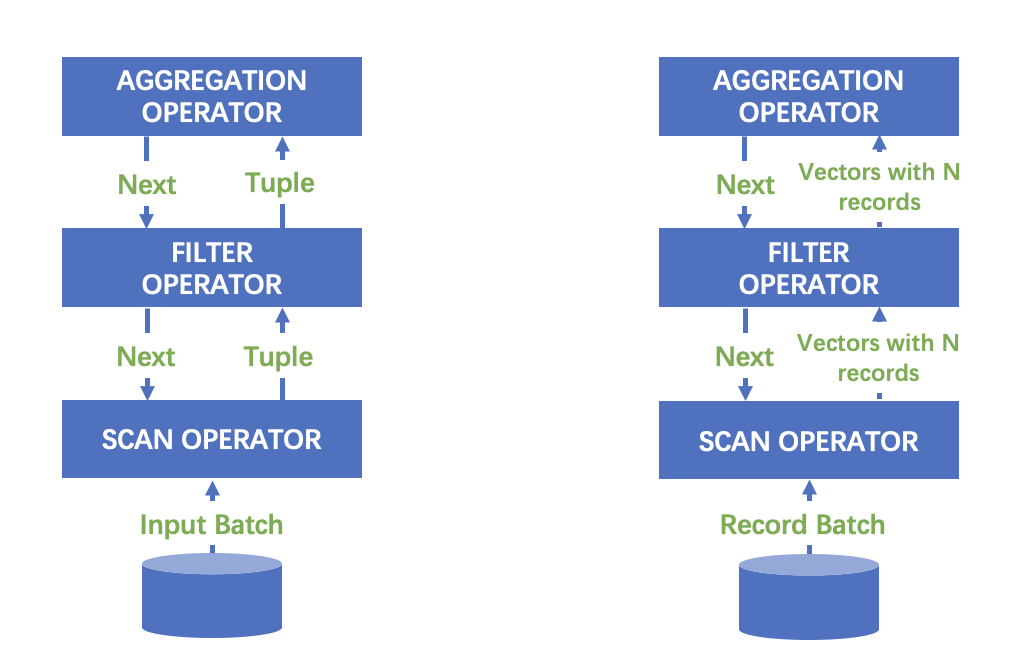
09
快速的顺序扫描; O(1) 的随机访问; SIMD 友好;
[1, null, 2, 4, 8]
* Length: 5, Null count: 1* Validity bitmap buffer:|Byte 0 (validity bitmap) | Bytes 1-63 ||-------------------------|-----------------------|| 00011101 | 0 (padding) |* Value Buffer:|Bytes 0-3 | Bytes 4-7 | Bytes 8-11 | Bytes 12-15 | Bytes 16-19 | Bytes 20-63 ||------------|-------------|-------------|-------------|-------------|-------------|| 1 | unspecified | 2 | 4 | 8 | unspecified |
关于石原子科技
石原子科技成立于 2021 年 10 月, 拥有国内顶级的数据库人才与专家,专注于企业级实时数据仓库和 MySQL 实时 HTAP 数据库的研发与应用,依托云中立的数据技术进行产品设计,致力于为客户提供大规模、高性能、低成本的一站式实时数据分析服务。
石原子科技坚持精细布局、自主创新的产品研发路线,打造了三款标杆产品:

业内首个单机内核开源、行列混存+内存计算架构的一体化 MySQL HTAP 数据库 StoneDB:使用 MySQL 的用户,通过 StoneDB 可以实现 TP+AP 混合负载,分析性能提升 10 倍以上显著提升,不需要进行数据迁移,也无需与其他 AP 集成,弥补 MySQL 分析领域的空白,形成实时在线数据就近分析。

基于全场景的新一代高性能、低成本的离在线一体化实时数仓 StoneData:高度兼容 MySQL 语法,毫秒级更新,亚秒级查询,满足准实时和实时分析需求,一体化架构将实时和离线融合,减少数据冗余和移动,具有简化技术栈架构的能力;实现业务与技术解耦,支持自助式分析和敏捷分析;无论是数据湖中的非结构化或半结构化数据,还是数据库中的结构化数据,都可使用 StoneData 构建企业的数据分析平台,同时完成高吞吐离线处理和高性能在线分析,实现降本增效。
基于容器、IAC 等技术的一站式数据库管理服务 StoneDMP:集数据管理、结构管理、用户授权、安全审计、数据趋势、数据追踪、BI 图表、性能与优化和服务器管理于一体的数据管理服务。
成立至今,公司已积累了上千位用户,种子客户达 300 多家,取得 30+ 项软件著作权,成功申请并获准通过了 10+ 项技术专利,分别获评浙江省级、国家级科技型中小企业。
石原子科技积极参与中国数据库产业建设,目前已经成为中国信通院分布式系统稳定性实验室成员单位、中国通信标准化协会(CCSA)大数据技术标准推进委员会(TC601)全权成员单位、中国信通院科技制造开源社区成员单位、中国信通院数据库应用创新实验室成员单位、国家信创工作委员会技术活动单位、浙江省信创联盟会员单位、上海市软件行业协会团体会员、北京信创工委会会员单位,先后参与起草多项国家级和行业级标准的编写工作。产品已经通过了中国信通院分布式分析型数据库基础能力专项评测、信息安全管理体系认证,并与主流服务器、操作系统、中间件等国产化软硬件生态体系进行全面兼容。

