




长话短说
成功测试了TCP_H SF100 和没有内存?没问题。DuckDB 有外部聚合 提到的Query 10。
环境
硬件
• Mate 60 Pro, 12GB 内存,512GB存储
• 电脑通过ssh 访问手机
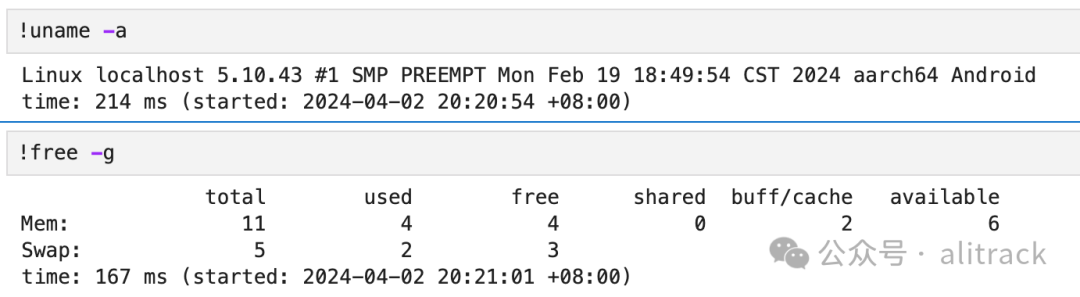
做测试的时候系统信息和内存信息(可以用内存4GB)
软件
• termux 先安装termux,后续的软件都安装在termux上。
• openssh
手机还是打字麻烦,就先装了openssh server,这样既可以ssh登陆手机,也可以sftp往手机上传文件。
# 手机端
yes|pkg upgrade # 更新
pkg install openssh # 安装openssh
pwd # 设置密码
sshd # 启动ssh server
ifconfig # 获得手机IP
#电脑端
ssh root@termux_ip -p 8022 # 手机端登录
• duckdb
pkg install duckdb
• jupyter lab
其实有了duckdb,这个不是必须,毕竟jupyter lab 也占用资源,我还是喜欢notebook的直观,还是装了。
pkg install libzmq
pkg install python python-pip
python -m venv .venv #创建python虚拟环境
source .venv/bin/active
pip install jupyterlab ipython-autotime jupysql duckdb-engine
jupyter-lab --ip=0.0.0.0 --no-brower #为了方便电脑访问
TPC_H SF 100测试
数据准备
使用ducdb的tpch extension 来生成测试数据, sf选择了100。
sf=100
import duckdb
import pathlib
for x in range(0, sf) :
con=duckdb.connect()
con.sql('PRAGMA disable_progress_bar;SET preserve_insertion_order=false')
con.sql(f"CALL dbgen(sf={sf} , children ={sf}, step = {x})")
for tbl in ['nation','region','customer','supplier','lineitem','orders','partsupp','part'] :
pathlib.Path(f'{sf}/{tbl}').mkdir(parents=True, exist_ok=True)
con.sql(f"COPY (SELECT * FROM {tbl}) TO '{sf}/{tbl}/{x:02d}.parquet' ")
con.close()
!du -h -d 1 |grep 100
#返回
38G ./100
生成的文件大小, 38G。
测试
%load_ext sql
%load_ext autotime
%sql duckdb:///tpch_100.db
#%config SqlMagic.autopandas=True
%config SqlMagic.feedback = False
%config SqlMagic.displaycon = False
第一次测试,没有限制内存,执行Query 7的时候导致termux闪退。
%%sql
-- 如果不限制内存,Query 7 会导致termux崩溃
SET memory_limit = '4GB';
创建视图
CREATE VIEW IF NOT EXISTS lineitem AS SELECT * FROM '/data/data/com.termux/files/home/duckdb/100/lineitem/*.parquet';
CREATE VIEW IF NOT EXISTS orders AS SELECT * FROM '/data/data/com.termux/files/home/duckdb/100/orders/*.parquet';
CREATE VIEW IF NOT EXISTS partsupp AS SELECT * FROM '/data/data/com.termux/files/home/duckdb/100/partsupp/*.parquet';
CREATE VIEW IF NOT EXISTS part AS SELECT * FROM '/data/data/com.termux/files/home/duckdb/100/part/*.parquet';
CREATE VIEW IF NOT EXISTS supplier AS SELECT * FROM '/data/data/com.termux/files/home/duckdb/100/supplier/*.parquet';
CREATE VIEW IF NOT EXISTS nation AS SELECT * FROM '/data/data/com.termux/files/home/duckdb/100/nation/*.parquet';
CREATE VIEW IF NOT EXISTS region AS SELECT * FROM '/data/data/com.termux/files/home/duckdb/100/region/*.parquet';
CREATE VIEW IF NOT EXISTS customer AS SELECT * FROM '/data/data/com.termux/files/home/duckdb/100/customer/*.parquet';
测试的SQL就不写了,可以贴完整SQL,也可以使用TPCH extension的命令, 如
PRAGMA tpch(4);
最大的lineitem表有6亿多行
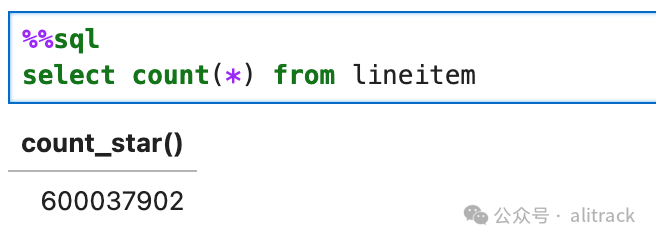
Query 18 用时最慢, 4min 3s
H2O.ai 数据库操作基准测试 Query 10
没有内存?没问题。DuckDB 有外部聚合 提到的Query 10 是最耗时、耗内存的,我就单独测试了它。
数据准备
• 下载19G测试压缩文件
wget -c https://blobs.duckdb.org/data/G1_1e9_2e0_0_0.csv.zst
压缩包18.8GB,未解压为50GB,duckdb支持.csv.zst
,所以就不解压了。
• 记得限制内存,否则termux可能会崩溃。
SET memory_limit = '4GB';
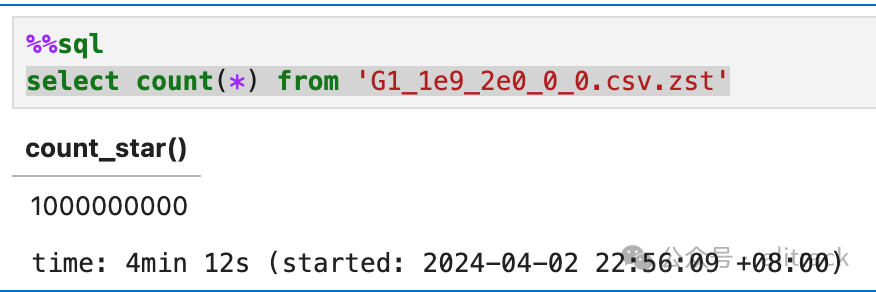
• 看看这个测试文件多少行
select count(*) from 'G1_1e9_2e0_0_0.csv.zst'
• 看看数据长啥样
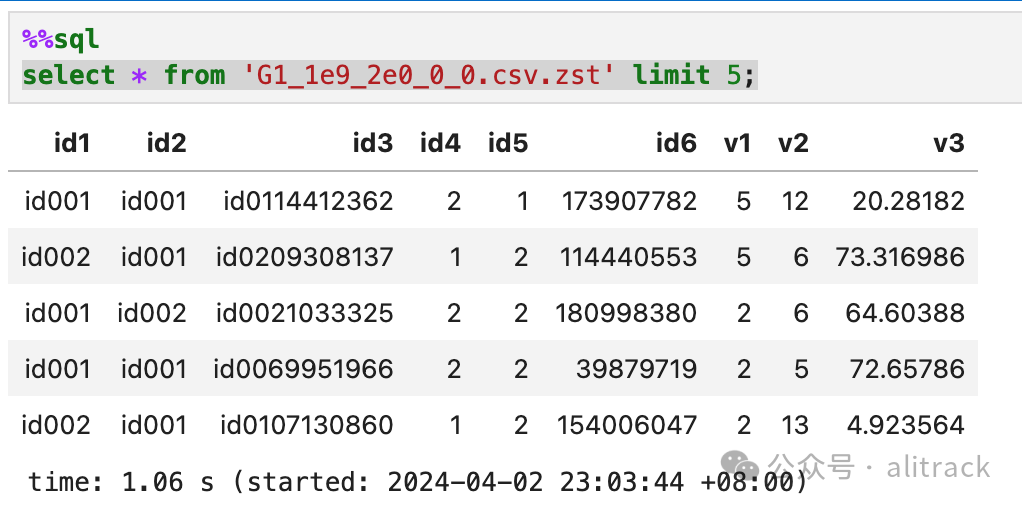
select * from 'G1_1e9_2e0_0_0.csv.zst' limit 5;
• 测试Query 10
CREATE OR REPLACE TABLE ans AS
SELECT id1, id2, id3, id4, id5, id6, sum(v3) AS v3, count(*) AS count
FROM 'G1_1e9_2e0_0_0.csv.zst'
GROUP BY id1, id2, id3, id4, id5, id6;
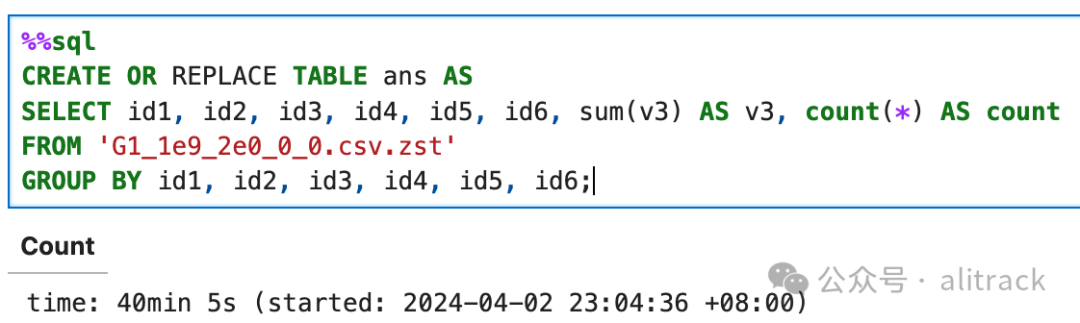
多次我以为它死了,想放弃,没有想到还是跑出来了。
结果
今天早上再想重现的时候,报空间不足,后来发现临时目录下生成了两个几50G以上的文件

这两个都是在notebook下运行duckdb,因为没有正常关闭连接,导致临时文件没有被及时清除。总的来说,DuckDB的确很强大,即使4GB内存,也可以通过测试,就是太慢了。
