





解析PostgreSQL中的Hash索引
前言
PostgreSQL包括持久磁盘Hash索引的实现,这是完全崩溃可恢复的。任何数据类型都可以通过Hash索引建立索引,包括没有良好定义的线性排序的数据类型。哈希索引只存储被索引的数据的哈希值,因此对被索引的数据列的大小没有限制。
哈希索引只支持单列索引,不允许唯一性检查。
哈希索引只支持=操作符,因此指定范围操作的WHERE子句将无法利用哈希索引。
每个哈希索引元组只存储4字节的哈希值,而不是实际的列值。因此,当索引较长的数据项(如uuid、url等)时,哈希索引可能比b树小得多。没有列值也会使所有哈希索引扫描有损。哈希索引可能参与位图索引扫描和反向扫描。
哈希索引最适合SELECT和update繁重的工作负载,这些工作负载在较大的表上使用等值扫描。在b树索引中,搜索必须在树中向下遍历,直到找到叶页。在具有数百万行的表中,这种下降会增加对数据的访问时间。在哈希索引中与叶子页等价的页面称为桶页。相反,散列索引允许直接访问桶页,从而可能减少大型表中的索引访问时间。这种“逻辑I/O”的减少在大于shared_buffers/RAM的索引/数据上变得更加明显。
哈希索引的设计是为了处理哈希值的不均匀分布。如果散列值是均匀分布的,那么直接访问桶页的效果很好。当插入意味着桶页已满时,额外的溢出页将链接到该特定桶页,从而在本地扩展与该散列值匹配的索引元组的存储。在查询期间扫描散列桶时,我们需要扫描所有溢出页。因此,对于某些数据而言,就所需的块访问数量而言,不平衡哈希索引实际上可能比b树更糟糕。
由于存在溢出情况,我们可以说哈希索引最适合唯一的、几乎唯一的数据或每个哈希桶的行数很少的数据。避免问题的一种可能方法是使用部分索引条件从索引中排除高度非惟一的值,但这在许多情况下可能不适合。
与b树一样,散列索引执行简单的索引元组删除。这是一种延迟维护操作,用于删除已知可以安全删除的索引元组(那些项标识符的LP_DEAD位已经设置的索引元组)。如果插入发现页面上没有可用的空间,我们尝试通过删除无效索引元组来避免创建新的溢出页。如果此时页面已固定,则无法进行删除。在VACUUM期间也会删除失效索引指针。
如果可以,VACUUM还会尝试将索引元组压缩到尽可能少的溢出页上,从而最小化溢出链。如果溢出页变为空,则可以回收溢出页以便在其他bucket中重用,尽管我们永远不会将它们返回给操作系统。目前没有收缩哈希索引的规定,除了用REINDEX重建它。也没有减少存储桶数量的规定。
随着索引的行数增加,哈希索引可能会扩展桶页的数量。选择哈希键到桶号的映射,以便可以增量地扩展索引。当一个新桶被添加到索引中时,只需要“拆分”一个现有桶,根据更新的键到桶号映射,将其中的一些元组转移到新桶中。
扩展发生在前台,这可能会增加用户插入的执行时间。因此,散列索引可能不适合行数快速增加的表。
实现原理
哈希索引中有四种页面:元页面meta page(第0页),包含静态分配的控制信息;主桶页;溢出页;位图页, 用于跟踪已被释放并可被重用的溢出页。出于寻址的目的,位图页被视为溢出页的一个子集。
扫描索引和插入元组都需要定位给定元组应该插入的位置。为此,我们需要元页面中的桶计数、高位掩码和低位掩码;但是,出于性能考虑,每次这样的操作都必须锁定和固定元页面是不可取的。相反,我们在每个后端的relcache条目中保留元页面的缓存副本。这将产生正确的桶映射,只要目标桶在上次缓存刷新后没有被分割。
主桶页和溢出页是独立分配的,因为任何给定的索引相对于桶的数量可能需要更多或更少的溢出页。哈希代码使用一组有趣的寻址规则来支持可变数量的溢出页,而不必在创建主bucket页后移动它们。
被索引的表中的每一行都由散列索引中的单个索引元组表示。哈希索引元组存储在桶页中,如果存在,则溢出页。我们通过保存任何一个索引页中的索引条目按哈希码排序来加快搜索速度,从而允许在索引页中使用二进制搜索。但是请注意,这里“没有”假设一个桶的不同索引页之间的哈希码的相对顺序。
扩展哈希索引的桶分割算法太复杂,不值得在这里提及,尽管在src/backend/access/hash/README中有更详细的描述。分割算法是崩溃安全的(crash safe),如果没有成功完成,也可以重新启动进行恢复。
索引页的布局
hash索引存储到磁盘上,同样以页的形式存储。各类操作基本上会访问到下边几种类型的页面:
metapage元页面:第0页, 提供一个索引的内容表
bucket页:索引的主页面,每个桶有一个页
溢出页:当主桶容纳不下所有元素时,就会产生溢出页
位图页:里边都是一些二进制数数组,用于跟踪已经释放掉并可以重用的溢出页
我们用pageinspect扩展来看看一个具体的hash索引页当中的内容:
create extension pageinspect;
create table test(id int, col2 varchar(128));
analyze test;
create index on test using hash(col2);
analyze操作保证索引的空间尽可能的小。否则桶的数量会基于表有10页的情况来创建。我们看看前4个页面的情况:
SELECT page, hash_page_type(get_raw_page('test_col2_idx', page))
FROM generate_series(0,3) page;
page | hash_page_type
------+----------------
0 | metapage
1 | bucket
2 | bucket
3 | bitmap
(4 rows)
大概就是下图的样子:

接着往下挖,看看元页面下边有啥?
SELECT * FROM hash_metapage_info(get_raw_page('test_col2_idx', 0)) \gx
-[ RECORD 1 ]
magic | 105121344
version | 4
ntuples | 0
ffactor | 307
bsize | 8152
bmsize | 4096
bmshift | 15
maxbucket | 1
highmask | 3
lowmask | 1
ovflpoint | 1
firstfree | 0
nmaps | 1
procid | 400
spares | {0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0}
mapp | {3,0,0,0,0,0,0,0,0 .............
注意下边几列:
ntuples: 0, ffactor:307, maxbucket:1。ffactor这一列的值只是每个桶容纳的元组个数的估计值。这个值是基于块大小以及存储参数fillfactor的值进行计算的。通过绝对均匀的数据分布和没有哈希冲突,你可以使用更高的Fillfactor值,但在实际数据库中,它会增加页面溢出的风险。ntuples值为0,意味着索引是空的。我们可以通过不断地插入相同值的行,引起桶所在页进行溢出:
insert into test select n, 'test123' from generate_series(1, 500) as n;
SELECT page, hash_page_type(get_raw_page('test_col2_idx', page))
FROM generate_series(0,4) page;
page | hash_page_type
------+----------------
0 | metapage
1 | bucket
2 | bucket
3 | bitmap
4 | overflow
(5 rows)
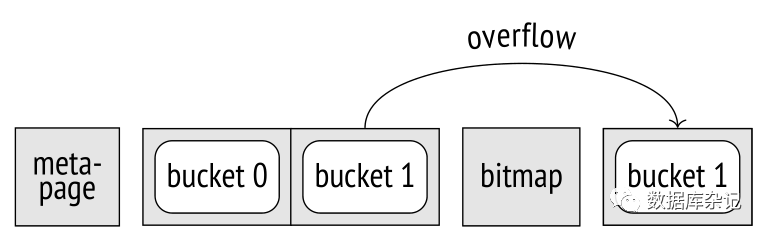
所有页面上的综合统计数据显示bucket为空,而所有的值被放置到bucket中:其中一些位于主页面; 那些不匹配的值可以在溢出页中找到。
SELECT page, live_items, free_size, hasho_bucket
FROM (VALUES (1), (2), (4)) p(page),
hash_page_stats(get_raw_page('test_col2_idx', page));
page | live_items | free_size | hasho_bucket
------+------------+-----------+--------------
1 | 0 | 8148 | 0
2 | 407 | 8 | 1
4 | 93 | 6288 | 1
(3 rows)
很明显,如果一个桶和同一桶的元素分布在几个桶上页面,性能会受到影响。如果数据分布是统一的,散列索引则会表现出最佳结果。
现在让我们来看看如何分割桶。当索引中的行数超过可用桶的估计ffactor值时,就会发生这种情况。这里我们有两个桶,ffactor因子是307,所以它将在第615行插入索引时发生:
SELECT ntuples, ffactor, maxbucket, ovflpoint
FROM hash_metapage_info(get_raw_page('test_col2_idx', 0));
ntuples | ffactor | maxbucket | ovflpoint
---------+---------+-----------+-----------
500 | 307 | 1 | 1
(1 row)
insert into test select n, 'test'|| n from generate_series(501, 615) as n;
NSERT 0 115
SELECT ntuples, ffactor, maxbucket, ovflpoint
FROM hash_metapage_info(get_raw_page('test_col2_idx', 0));
ntuples | ffactor | maxbucket | ovflpoint
---------+---------+-----------+-----------
615 | 307 | 2 | 2
(1 row)
maxbucket的值已经增加到2: 现在我们有3个桶,编号从0到2。但是,尽管我们只添加了一个桶,页面的数量却翻了一番:
SELECT page, hash_page_type(get_raw_page('test_col2_idx', page))
FROM generate_series(0,6) page;
page | hash_page_type
------+----------------
0 | metapage
1 | bucket
2 | bucket
3 | bitmap
4 | overflow
5 | bucket
6 | unused
(7 rows)

其中一个新页被第2号桶使用,而另一个新页则是空闲的,很快也会被桶3使用。从下边的结果也可以看出:
SELECT page, live_items, free_size, hasho_bucket
FROM (VALUES (1), (2), (4), (5)) p(page),
hash_page_stats(get_raw_page('test_col2_idx', page));
page | live_items | free_size | hasho_bucket
------+------------+-----------+--------------
1 | 38 | 7388 | 0
2 | 407 | 8 | 1
4 | 144 | 5268 | 1
5 | 26 | 7628 | 2
(4 rows)
因此,从操作系统的角度来看,哈希索引是快速增长的,尽管从逻辑的角度来看哈希表是逐渐增长的。为了在一定程度上平衡这种增长并避免一次分配过多的页面,从第10次增加开始,将页面分配为四个相等的批次,而不是一次分配所有的页面。
metapage中有两个位掩码字段提供具体的桶地址细节:
SELECT maxbucket, highmask::bit(4), lowmask::bit(4)
FROM hash_metapage_info(get_raw_page('test_col2_idx', 0));
maxbucket | highmask | lowmask
-----------+----------+---------
2 | 0011 | 0001
(1 row)
桶号由与高掩码对应的哈希码位定义。但是如果接收到的桶号不存在(超过maxbucket),则采用低掩码位在这个特殊的例子中,我们取两个最低的位,这就给出了从0到3的值; 但如果我们得到3,我们只取最低位,也就是说,用bucket 1代替bucket 3。
每次大小增加一倍时,新的桶页被分配为单个连续块,而溢出页和位图页则根据需要插入这些碎片之间。元页面保留了插入到空闲数组中每个块中的页面数量,这使我们有机会使用简单的算术根据桶号计算其主页的数量。
在这个特殊的例子中,第一次增加之后插入了两个页面(一个位图页面和一个溢出页面),但是在第二次增加之后没有发生新的页面:
SELECT spares[2], spares[3]
FROM hash_metapage_info(get_raw_page('test_col2_idx', 0));
spares | spares
--------+--------
2 | 2
(1 row)
metapage同样也保存了一个指向位图页面的指针数组:
SELECT mapp[1]
FROM hash_metapage_info(get_raw_page('test_col2_idx', 0));
mapp
------
3
(1 row)
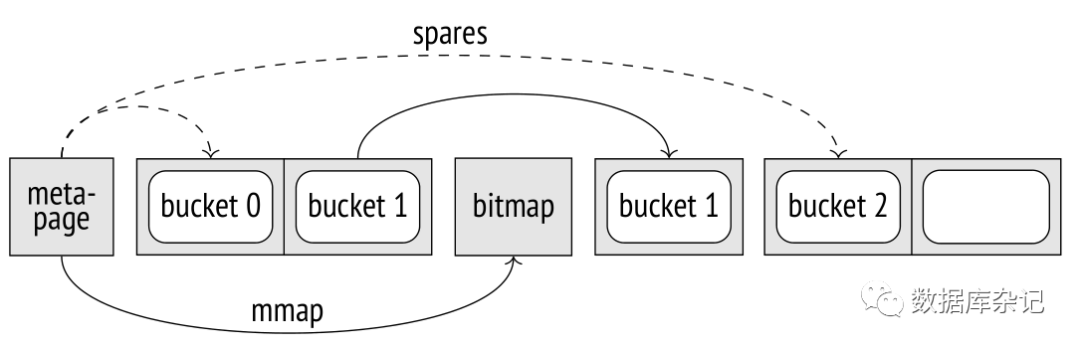
当指向死元组的指针被删除时,索引页中的空间将被释放。它发生在页面修剪期间 (在尝试将元素插入完全填充的页面时触发)或执行常规Vacuum(真空回收)时。
然而,哈希索引不能自动收缩: 一旦分配,索引页将不会返回给操作系统。主页被永久地分配到它们的bucket中,即使它们根本不包含任何元素;清除的溢出页在位图中被跟踪,并且可以被重用(可能由另一个桶)。减少索引物理大小的唯一方法是使用REINDEX或VACUUM FULL命令重新构建索引。
查询计划里也没有明显的索引类型提示:
insert into test select n, md5(random()::varchar) from generate_series(700, 100000) as n;
INSERT 0 99301
EXPLAIN (costs off)
SELECT *
FROM test
WHERE col2 = 'c67e830da546020d61593f1bd58ac38c';
QUERY PLAN
-------------------------------------------------------------------------
Index Scan using test_col2_idx on test
Index Cond: ((col2)::text = 'c67e830da546020d61593f1bd58ac38c'::text)
(2 rows)
看看索引 大小的变化 :
select pg_indexes_size('test');
pg_indexes_size
-----------------
4767744
(1 row)
delete from test where id < 20000;
DELETE 19915
select pg_indexes_size('test');
pg_indexes_size
-----------------
4767744
(1 row)
reindex table test;
REINDEX
select pg_indexes_size('test');
pg_indexes_size
-----------------
4210688(1 row)
参考:
(https://www.postgresql.org/docs/14/pageinspect.html#id-1.11.7.34.10) [F.25. pageinspect PostgreSQL Document]
https://www.postgresql.org/docs/14/hash-index.html [Chapter 69. Hash Indexes]
[PostgreSQL 14 Internals] by Egor Rogov [Chapter 24 Hash Index]
后续:
本文只是把文档中的内容以及Internals中的部分内容整理了一下,试图加深对Hash Index内部结构的理解。等那本书中文版出来以后,就可以完整的阅读了。

