





聊聊HANA数据库中的分区表
表分区简介
表分区
SAP HANA数据库的分区特性将列存储表水平拆分为分离的子表或分区。通过这种方式,可以将大表分解为更小、更易于管理的部分。分区通常用于多主机系统,但它在单主机系统中也可能是有益的。
分区既可以在SAP HANA座舱中完成(请参考使用SAP HANA座舱的SAP HANA管理),也可以在SQL命令行中完成。对于SQL查询和数据操作语言(DML)语句,分区是透明的。分区本身还有额外的数据定义语句(DDL):
创建表分区
Re-partition表
将分区合并到一个表中
添加/删除分区
将分区移动到其他主机
在某些分区上执行增量合并操作
特权
通常,要修改给定表的分区,需要该表的特定ALTER对象特权。但是,PARTITION ADMIN系统特权是可用的,并且具有该特权的用户可以使用ALTER TABLE语句执行一些分区操作;例如:对表进行分区,移动或合并分区。SAP HANA平台的SAP HANA SQL参考指南的Alter TABLE部分对应的“非异构Alter Partition子句”和“异构Alter Partition子句”给出了可以用于此特权的分区子句的完整列表。
关于分区
当对表进行分区时,将以这样一种方式进行分割,即每个分区包含表的不同行集。有几种可用于指定如何将行分配给表的分区的替代方法,例如,散列分区或按范围分区。
以下是分区的典型优点:
分布式系统中的负载均衡
单个分区可以分布在多个主机上。这意味着表上的查询不是由单个服务器处理,而是由承载分区的所有服务器处理。克服列存储表的大小限制
非分区表不能存储超过20亿行。可以通过将行分布到多个分区来克服这个限制。每个分区不能包含超过20亿行。并行化
分区允许通过对每个表使用多个执行线程来并行化操作。分区修剪
分析查询以确定它们是否匹配表的给定分区规范(静态分区修剪),还是匹配老化表中特定列的内容(动态分区修剪)。如果找到了匹配项,就可以确定保存正在查询的数据的特定分区,并避免访问和加载不需要的内存分区。有关详细信息,请参见静态和动态分区修剪。改进了增量合并操作的性能
增量合并操作的性能取决于主索引的大小。如果只在某些分区上修改数据,则需要增量合并的分区将更少,因此性能将更好。显式分区处理
应用程序可以主动控制分区,例如,通过添加分区来存储下一个月的数据。
下图说明了如何将一个表分布在三个主机上,每个主机在不同的月份使用专用分区。
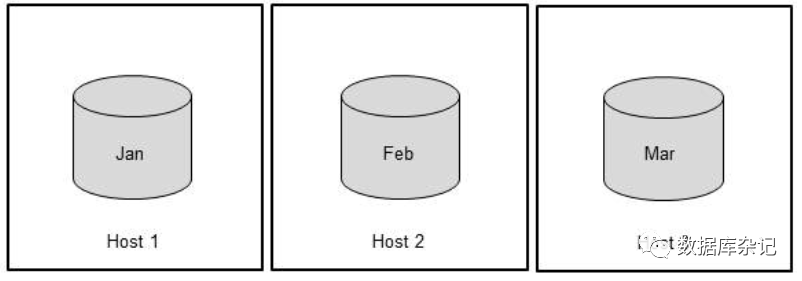
请注意
添加或移除主机后,建议执行重新分配操作。根据其配置,重新分配操作将建议表和分区在系统中的新位置。如果您确认了重新分配计划,那么重新分配操作将相应地重新分发表和分区。
单重分区
当对表进行分区时,它的行根据称为分区规范的不同标准分发到分区。
SAP HANA数据库支持的单级分区规格如下:
轮循
哈希
范围
对于高级用例,可以使用多级分区嵌套这些规范。
Hash(散列)分区
散列分区用于将行均匀地分发到分区,以实现负载平衡,并克服20亿行的限制。通过对指定列的值应用散列函数来计算分配的分区的数目。哈希分区不需要深入了解表的实际内容。
对于每个散列分区规范,必须将列指定为分区列。在确定哈希值时使用这些列的实际值。如果表有一个主键,那么这些分区列必须是该键的一部分(但是请注意,只创建1个分区的哈希分区不会对分区键列施加任何主键限制)。这种限制的优点是可以在本地服务器上执行密钥的唯一性检查。您可以根据需要使用尽可能多的分区列,以实现相等分布的各种值。
有关分区SQL语法的更多信息,请参见SAP HANA SQL和系统视图参考。
实例:
在列a和b上创建了四个分区。目标分区是根据列a和b中的实际值确定的。必须至少指定一个列。如果一个表有一个主键,那么所有分区列都必须是这个主键的一部分。
CREATE COLUMN TABLE MY_TABLE (a INT, b INT, c INT, PRIMARY KEY (a,b))
PARTITION BY HASH (a, b) PARTITIONS 4
分区的数量由数据库在运行时根据其配置决定。建议在脚本中使用该函数,等等。
CREATE COLUMN TABLE MY_TABLE (a INT, b INT, c INT, PRIMARY KEY (a,b))
PARTITION BY HASH (a, b) PARTITIONS GET_NUM_SERVERS()
在本例中,只创建一个一级HASH分区。尽管表中的数据因此是未分区的,但是分区是存在的,并且可以通过其逻辑分区ID来引用。这个ID可以与其他SQL语句一起使用,然后应用到整个表。例如,可以通过引用分区ID来截断表:
TRUNCATE TABLE T_HASH_1 PARTITION(1);
分区ID也被使用,例如,在MOVE partition语句中:
ALTER TABLE T_HASH1 MOVE PARTITION 1 TO 'host1:port2';
CREATE COLUMN TABLE T_HASH_1 (A INT, B VARCHAR(64), C INT)
PARTITION BY HASH(A) PARTITIONS 1;
Round-Robin分区
循环分区用于实现将行均匀地分配到分区。但是,与散列分区不同,您不必指定分区列。在循环分区中,新行以轮换为基础分配给分区。表不能有主键。
哈希分区通常比循环分区更有利,原因如下:
分区列不能在修剪步骤中求值。因此,在搜索和其他数据库操作中要考虑所有分区。
根据不同的场景,语义相关表中的数据可能驻留在同一台服务器上。一些内部操作可能在本地操作,而不是从不同的服务器检索数据。
对于Round-Robin和Round-Robin- range分区模式,需要验证以下DML语句以确保数据保持一致:INSERT、UPDATE、DELETE和UPSERT。对于这些语句,将检查传递的分区id,以确保值与原始的轮循分区规范一致。
实例:
1、创建了四个分区。注意:表不能有主键。
CREATE COLUMN TABLE MY_TABLE (a INT, b INT, c INT)
PARTITION BY ROUNDROBIN PARTITIONS 4
2、分区的数量由数据库在运行时根据其配置决定。建议在可能在各种环境中运行的脚本或客户端中使用此功能。
CREATE COLUMN TABLE MY_TABLE (a INT, b INT, c INT)
PARTITION BY ROUNDROBIN PARTITIONS GET_NUM_SERVERS()
3、在本例中,只创建了一个一级ROUNDROBIN分区。尽管表中的数据因此是未分区的,但是分区是存在的,并且可以通过其逻辑分区ID来引用。这个ID可以与其他SQL语句一起使用,然后应用到整个表。例如,可以通过引用分区ID来截断表:
TRUNCATE TABLE T_ROUNDROBIN_1 PARTITION(1);
分区ID也被使用,例如,在MOVE partition语句中: ALTER TABLE T_ROUNDROBIN_1 MOVE PARTITION 1 TO 'host1:port2';
CREATE COLUMN TABLE T_ROUNDROBIN_1 (A INT, B VARCHAR(64), C INT)
PARTITION BY ROUNDROBIN PARTITIONS 1;
范围分区
范围分区为表中的某些值或值范围创建专用分区。例如,可以选择一个范围分区方案,为每个日历月创建一个分区。分区需要深入了解所选分区列所使用或有效的值。
可以根据需要创建或删除分区,应用程序可以选择使用范围分区来更详细地管理数据,例如,应用程序可以为即将到来的月份创建分区,以便将新数据插入到新分区中。
请注意
范围分区不太适合负载分配。多级分区规范解决了这个问题。
范围分区规范通常使用值范围来确定一个分区(例如整数1到10),但是也可以为单个值定义一个分区。通过这种方式,可以模拟其他数据库系统中已知的列表分区,并将其与范围分区相结合。
当插入或修改行时,目标分区由定义的范围确定。如果值不适合这些范围之一,则会引发错误。为了防止这种情况,您还可以为不匹配任何已定义范围的任何值定义一个“others”分区。可以根据需要动态创建或删除“其他”分区。
范围分区类似于散列分区,如果表上有主键,分区列必须是键的一部分。范围分区支持许多数据类型,请参见下面的列表。
实例
下面的示例为整数创建三列,并将第一列划分为四个分区。范围使用以下语义定义:<= VALUES <,单个值的范围使用=。
一个分区用于大于或等于1且小于5的值
1个分区用于大于或等于5且小于20的值
1分区值为44
为所有其他不匹配指定范围的值创建分区
CREATE COLUMN TABLE MY_TABLE (a INT, b INT, c INT, PRIMARY KEY (a,b))
PARTITION BY RANGE (a)
(PARTITION 1 <= VALUES < 5,
PARTITION 5 <= VALUES < 20,
PARTITION VALUE = 44, PARTITION OTHERS)
分区列(在本例中为a)必须是主键的一部分。
数据类型
分区列允许的数据类型如下:
| Datetime Types | DATE, SECONDDATE, TIMESTAMP |
|---|---|
| Numeric Types | TINYINT, SMALLINT, INTEGER, BIGINT, DECIMAL(p,s) |
| Boolean Type | BOOLEAN |
| Character String Types | VARCHAR, NVARCHAR |
| Binary Types | VARBINARY |
| Large Object Types | BLOB, CLOB, NCLOB using the ST_MEMORY_LOB option |
| Text Types | SHORTTEXT |
对于异构范围分区,数字数据类型支持负数和正数,因此下面示例中显示的用例(其中列TESTRESULT被定义为整数)是可能的:
PARTITION BY RANGE("TESTRESULT") (
(PARTITION VALUES = -11),
(PARTITION -10 <= VALUES < 10),
(PARTITION OTHERS)
);
该选项支持以下多级范围分区类型:range - range、range - hash和HASH-RANGE。它不支持多存储(动态分层)表。
对于VARBINARY类型,SQL代码中输入的分区定义必须使用二进制值的HEX表示来指定条件的边界。下面的示例创建了一个两列的表,第一列用于整数,第二列用于16字节的可变二进制数据。在这种情况下,varbinary数据的分区边界必须用32个十六进制数字指定(每个二进制字节需要2个十六进制字符):

当使用平衡分区模式并在TIMESTAMP列上为分区表定义范围时,可以以小时为单位指定TIMESTAMP值的精度(不适用于异构分区)。小时值可以添加到以空格分隔的日期后,也可以包含在单个数字字符串中,示例如下:
PARTITION '2010-01-01 00' <= VALUES < '2010-02-01 00', PARTITION OTHERS
PARTITION 2016031400 <= VALUES < 2016031500, PARTITION OTHERS
多重分区
多级分区可以用来克服单级哈希分区和范围分区的限制,也就是说,如果表有主键,则必须使用该列作为分区列。多级分区使得按不属于主键的列进行分区成为可能。
下面的代码示例和插图展示了如何在第一级使用散列分区和在第二级使用范围分区来应用多级分区。第二级分区中的数据根据所选列'b'的值分组:值低于5的行和值大于或小于9的行。
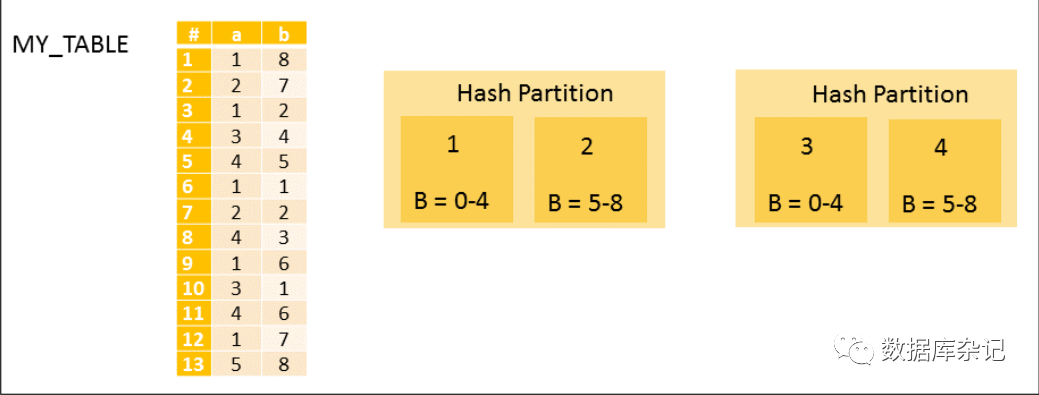
创建这些分区的SQL代码语法如下:
CREATE COLUMN TABLE MY_TABLE (a INT, b INT, PRIMARY KEY (a,b))
PARTITION BY
HASH (a,b) PARTITIONS 2,
RANGE (b) (PARTITION 0 <= VALUES < 5, PARTITION 5 <= VALUES < 9)
主键列限制仅适用于第一个分区级别。当插入或更新一行时,必须检查键的唯一约束。如果必须在整个区域的所有分区上检查主键,这将涉及昂贵的远程调用。但是,二级分区组允许在只需要对本地分区进行主键检查的情况下进行插入。
相关的二级分区形成一个分区组;上图显示了两个组(分区1和2是一个组,分区3和4是一个组)。当向分区1插入一行时,只需要检查分区1和2上的唯一性。一个分区组的所有分区必须位于同一主机上。SQL命令可用于移动分区,但不能移动组中的单个分区,只能移动整个分区组。
使用日期函数进行分区
您可以使用多级分区来实现基于时间的分区,以利用日期列并根据月份或年份构建分区。例如,这可以用于最小化增量合并操作的运行时间。增量合并操作的性能取决于表的主索引的大小。如果随着时间的推移将数据插入到表中,并且在其结构中还包含日期,那么对日期进行多级分区可能非常有效。包含旧数据的分区通常不经常被修改,因此不需要在这些分区上进行增量合并;只有在插入新数据的分区上才需要合并。
如果需要按月或按年对表进行分区,并且该表只包含日期列或时间戳列,则可以使用下面所示的日期函数按年或按年加月限制查询结果。
实例:
下面的例子使用year()函数进行哈希分区:
CREATE COLUMN TABLE MY_TABLE (a DATE, b INT, PRIMARY KEY (a,b)) PARTITION BY HASH (year(a)) PARTITIONS 4
如果值的格式为“2018-12-08”,则只对“2018”应用哈希函数。此功能也可用于修剪。
下面的例子使用year()函数按范围进行分区:
CREATE COLUMN TABLE MY_TABLE (a DATE, b INT, PRIMARY KEY (a,b)) PARTITION BY RANGE (year(a)) (PARTITION '2010' <= values < '2013', PARTITION '2013' <= values < '2016')
下面的示例使用month()函数使用年和月的值按范围进行分区:
CREATE COLUMN TABLE MY_TABLE (a DATE, b INT, PRIMARY KEY (a,b)) PARTITION BY RANGE (month(a)) (PARTITION '2005-01' <= values < '2005-07', PARTITION '2005-07' <= values < '2006-01')
哈希-范围分区
哈希范围分区是最常见的多级分区类型。哈希分区在第一级实现,用于负载平衡;范围分区在第二级实现,用于基于时间的分区。
下图显示了一个典型的使用场景。负载使用散列分区分布到三台主机上。在第二级使用范围分区,根据月份将数据分发到各个分区。
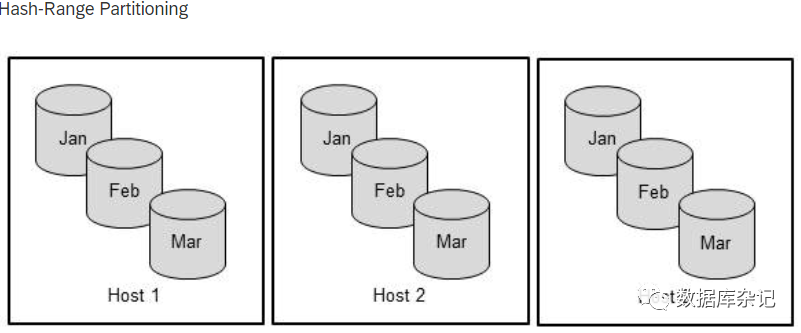
哈希范围多重分区实例
CREATE COLUMN TABLE MY_TABLE (a INT, b INT, c INT, PRIMARY KEY (a,b))
PARTITION BY
HASH (a, b) PARTITIONS 4,
RANGE (c)
(PARTITION 1 <= VALUES < 5,
PARTITION 5 <= VALUES < 20)
RoundRobin-Range分区
RoundRobin范围内的多级分区与哈希范围内的多级分区相同,但在第一级采用了RoundRobin分区。
对于RoundRobin和RoundRobin- range分区模式,需要验证以下DML语句以确保数据保持一致:INSERT、UPDATE、DELETE和UPSERT。对于这些语句,将检查传递的分区id,以确保值与原始的roundbin分区规范一致。
RoundRobin-Range分区实例
CREATE COLUMN TABLE MY_TABLE (a INT, b INT, c INT)
PARTITION BY
ROUNDROBIN PARTITIONS 4,
RANGE (c)
(PARTITION 1 <= VALUES < 5,
PARTITION 5 <= VALUES < 20)
Hash-Hash分区
哈希-哈希多级分区是通过两个级别的哈希分区实现的。这样做的好处是可以在非键列上定义第二级的哈希分区。
实例:
CREATE COLUMN TABLE MY_TABLE (a INT, b INT, c INT, PRIMARY KEY (a,b))
PARTITION BY
HASH (a, b) PARTITIONS 4,
HASH (c) PARTITIONS 7
范围-范围分区
范围-范围多级分区是通过两个级别的范围分区实现的。这样做的好处是可以在非键列上定义第二级的范围分区。
实例:
CREATE COLUMN TABLE MY_TABLE (a INT, b INT, c INT, PRIMARY KEY (a,b))
PARTITION BY
RANGE (a)
(PARTITION 1 <= VALUES < 5,
PARTITION 5 <= VALUES < 20),
RANGE (c)
(PARTITION 1 <= VALUES < 5,
PARTITION 5 <= VALUES < 20)
异构分区的划分
异构分区为范围-范围和范围-散列两级分区模式提供了更大的灵活性。
普通的(平衡的)第二级范围分区模式对所有第一级分区应用相同的第二级规范。但是对于某些场景,可能需要灵活的异构第二级范围分区模式,为每个第一级分区使用不同的第二级范围规范。这对于列存储表和动态分层多存储表都是可能的,使用CREATE TABLE和ALTER TABLE PARTITION BY语句的特殊异构分区子句。
对于异构分区,第一级分区类型必须是range(单级异构分区也是可能的)。对于range-range和range-hash分区,第二级的所有分区必须基于相同的列。
异构分区支持以下特性:
分区的属性(元数据);它们被简单地定义为具有布尔状态的值(参见分区属性一节)。
放置一级和二级分区,以便可以将分区直接放置(或移动)在支持HANA横向扩展或动态分层解决方案的指定主机上(正常均衡分区也支持放置)。
主键
根据您的需求,您可以应用异构分区的条件来在主键列上强制分区。当您创建带有分区的表或使用ALTER table对表进行重分区时…在分区BY语法中,有一个
与create table语句一起提供的另一个选项是PRIMARY KEY UPDATE属性,它决定是否允许在主键列上使用UPDATE语句。还可以使用SQL语句删除异构子分区、重新定义异构第一级分区以及将异构第一级分区(及其子分区)移动到新的位置。SAP HANA SQL和系统视图参考中提供了这些选项的详细信息。
例子
下面的一组range-range示例说明了这个特性。
例1:异构的2级范围-范围分区。SUBPARTITION BY关键字用于指定二级异构分区。本例中的语法将分区1和分区2用括号括在一起;如果相同的子分区定义应用于两个第一级分区,这是可能的。
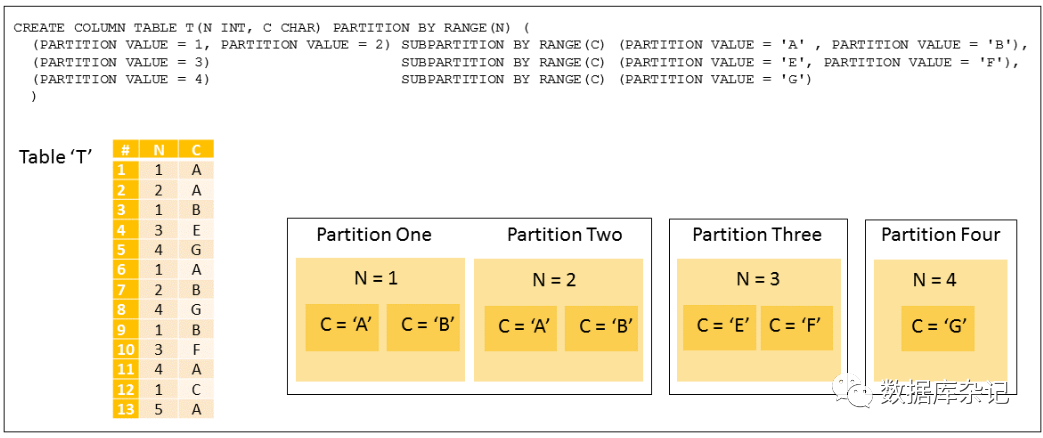
示例2:AT LOCATION可以在第一级或第二级使用,以指定应该在哪里创建分区,这可以是在indexserver或用于动态分层的扩展存储服务器上。INSERT开关可用于创建只读分区,并可用于防止在分区上执行插入语句。
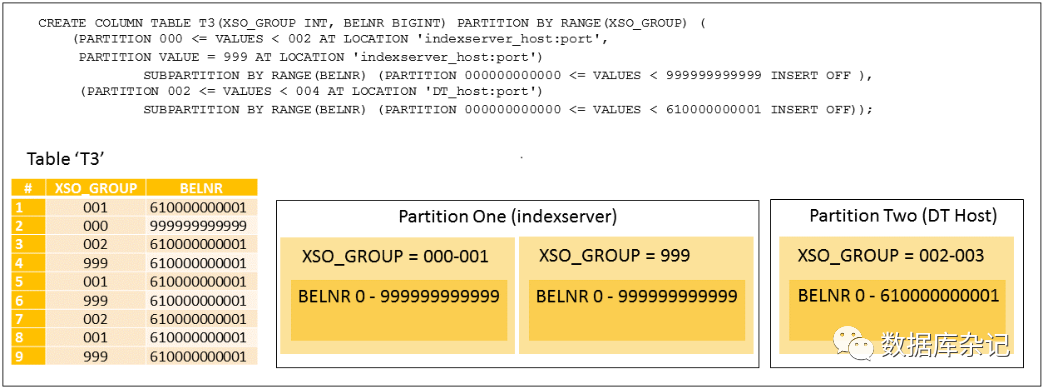
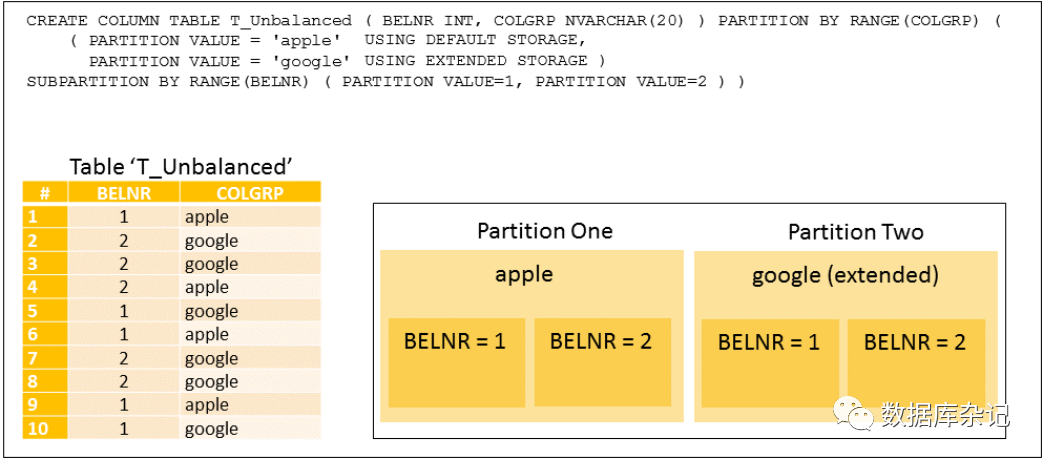
例3:这个例子显示了可用的存储类型选项:要么使用默认存储,要么使用扩展存储进行动态分层。
分区属性
分区有一组可配置的属性,可以使用ALTER PARTITION命令应用这些属性。
分区支持以下属性,这些属性的值保存在TABLE_PARTITIONS系统视图中:
| Property | Value | Scope |
|---|---|---|
| Load Unit | DEFAULT, COLUMN, PAGE | Heterogeneous partitioning only |
| Persistent memory (NVM) | TRUE FALSE | Balanced and heterogeneous partitioning |
| NUMA Node | List of preferred NUMA Nodes | Balanced partitioning only |
| Insert | TRUE FALSE | Heterogeneous partitioning only |
| Storage type | DEFAULT EXTENDED (for multi-store tables) | Heterogeneous partitioning only |
| GROUP_NAME | Group properties from table placement | Heterogeneous partitioning only |
| GROUP_TYPE | Heterogeneous partitioning only | |
| SUBTYPE | Heterogeneous partitioning only |
可以使用ALTER partition关键字或使用partition BY修改分区的这些属性。使用PARTITION BY语法可以同时应用多个属性,参见下面的第三个示例。
请注意
如果使用ALTER table…Partition BY…对表进行重分区,并且分区规格从Balanced切换到Heterogeneous(反之亦然),则分区属性将丢失。即使使用相同的分区布局也是如此。在这种情况下,必须使用ALTER TABLE语句重新定义分区属性。
ALTER TABLE T1 ALTER PARTITION 1 INSERT ON;
ALTER TABLE T1 ALTER PARTITION 2 INSERT OFF;
ALTER TABLE T1 PARTITION BY RANGE(x) (PARTITION VALUE =1 INSERT ON, PARTITION VALUE =2 INSERT OFF);
在多级分区场景中应用属性的示例如下:
ALTER TABLE T1 PARTITION BY RANGE(c1) (
(PARTITION 0 <= VALUES < 5 GROUP NAME 'test5')
SUBPARTITION BY RANGE(c2) (PARTITION VALUE = 'a' GROUP NAME 'test6', PARTITION VALUE = 'b', PARTITION VALUE = 'c' ),
(PARTITION 5 <= VALUES < 10 NUMA NODE ('5'))
SUBPARTITION BY RANGE(c2) (PARTITION VALUE = 'a' NUMA NODE ('6'), PARTITION VALUE = 'b', PARTITION VALUE = 'c'),
(PARTITION 10 <= VALUES < 15 INSERT OFF)
SUBPARTITION BY RANGE(c2) (PARTITION VALUE = 'a' INSERT ON, PARTITION VALUE = 'b', PARTITION VALUE = 'c'));
存储类型属性仅适用于第一级位置,并且只能通过MOVE PARTITION命令进行修改:
MOVE PARTITION <partition_number> TO <move_location>
可以使用带有alter_persistent_memory_spec子句的CREATE和ALTER表命令在分区级别启用或禁用持久内存。有关持久化内存的详细信息,请参阅SAP HANA SQL参考指南中的异构和非异构alter分区子句的详细信息。
只有当分区属性设置为TRUE时,才会消耗持久内存。在监控视图M_TABLE_PARTITIONS中,消耗显示为PERSISTENT_MEMORY_SIZE_IN_TOTAL,该视图显示每个列存储表当前的纯持久内存消耗(以字节为单位)。列MEMORY_SIZE_IN_MAIN和MEMORY_SIZE_IN_TOTAL仅捕获分页内存消耗,而不捕获持久内存消耗。参见本机存储扩展部分中的“页面可加载数据的持久大小”。
设置加载单元
有许多选项可用于支持PAGE LOADABLE加载单元,以与SAP HANA本机存储扩展兼容;PAGE LOADABLE属性仅支持平衡HASH-RANGE和异构分区。
转换多存储表的分区
您可以将为动态分层创建并通过HASH-RANGE进行分区的多存储扩展存储表的分区转换为列存储分区,以便与本机存储扩展一起使用。ALTER PARTITION语句支持一个值来指定分区加载单位:
CREATE COLUMN TABLE TAB (X INT NOT NULL, Y INT NOT NULL)
PARTITION BY HASH(X) PARTITIONS 3, RANGE(Y) (
USING DEFAULT STORAGE (PARTITION 0 <= VALUES < 10)
USING EXTENDED STORAGE (PARTITION 10 <= VALUES < 20,
PARTITION 20 <= VALUES < 30, PARTITION 30 <= VALUES < 50));
其中两个然后移动到列存储与'PAGE LOADABLE' LOAD UNIT选项:
ALTER TABLE TAB ALTER PARTITION (Y) USING DEFAULT STORAGE
( 10 <= values < 20, 30 <= VALUES < 50) PAGE LOADABLE
注意,这只能用于HASH-RANGE多存储表。
重分区表时设置Load Unit
当一个表使用异构分区模式(ALTER table…)进行重分区时,也可以指定加载单元。分区)。所有目标RANGE分区的load unit属性可以单独设置为COLUMN LOADABLE或PAGE LOADABLE (NSE需要):
ALTER TABLE T1 PARTITION BY RANGE (C1)
((PARTITION 1 <= VALUES < 30 PAGE LOADABLE, PARTITION 30 <= VALUES < 70 COLUMN LOADABLE, PARTITION 70 <= VALUES < 90 COLUMN LOADABLE,
PARTITION 90 <= VALUES < 160 PAGE LOADABLE, PARTITION 160 <= VALUES < 190 COLUMN LOADABLE, PARTITION OTHERS PAGE LOADABLE))
如果没有为分区指定负载单位值,则默认应用DEFAULT LOADABLE值。使用ALTER TABLE语句中分配的任何负载单位值创建新分区。但是请注意,重分区表中不兼容的加载单元值可能导致错误。如下例所示,源分区[50,100]没有给定负载单元:
CREATE TABLE T1 (C1 INT) PARTITION BY RANGE (C1)
((PARTITION 1 <= VALUES < 50 COLUMN LOADABLE, PARTITION 50 <= VALUES < 100, PARTITION 100 <= VALUES < 150 PAGE LOADABLE,
PARTITION 150 <= VALUES < 200 COLUMN LOADABLE, PARTITION OTHERS COLUMN LOADABLE)) PAGE LOADABLE
在下面这个表的重分区语句中,load unit属性并没有明确地提供给新分区[30,70],但是由于源分区的COLUMN LOADABLE和PAGE LOADABLE之间没有冲突,所以新分区可以成功创建:
ALTER TABLE T1 PARTITION BY RANGE (C1)
((PARTITION 1 <= VALUES < 30 PAGE LOADABLE, PARTITION 30 <= VALUES < 70, PARTITION 70 <= VALUES < 90 COLUMN LOADABLE,
PARTITION 90 <= VALUES < 160 PAGE LOADABLE, PARTITION 160 <= VALUES < 190 COLUMN LOADABLE, PARTITION OTHERS PAGE LOADABLE))
如果两个源分区[1,50)和[50,100]显式地定义了不同的加载单元值(COLUMN LOADABLE和PAGE LOADABLE),那么重分区语句将失败并报错。
类似地,下面的例子显示了具有不同属性值的源分区:
CREATE TABLE T1 (C1 INT) PARTITION BY RANGE (C1)
((PARTITION 1 <= VALUES < 50 COLUMN LOADABLE, PARTITION 50 <= VALUES < 100 PAGE LOADABLE, PARTITION OTHERS COLUMN LOADABLE))
下面的语句尝试重新划分表,并从具有不同负载单元值组合的源创建一个新分区。这个冲突会产生一个错误:
ALTER TABLE T1 PARTITION BY RANGE (C1)
((PARTITION 1 <= VALUES < 100, PARTITION OTHERS COLUMN LOADABLE))
请注意
也可以使用ALTER table更改表、分区或列的加载单元。一个'cascade'选项是可用的,它将加载单元应用于对象层次结构中所有较低的对象。
删除分区
可以使用SQL TRUNCATE语句删除表的特定分区的内容。
SQL语句TRUNCATE可用于截断整个表或表的特定分区。例如,如果需要刷新单个分区中的数据(例如一年的数据),但保留其他分区,则可能需要这样做。
分区只能在列存储表中被截断(不能在行存储表中);不能截断远程表(来自不同租户的表)和复制表(具有OSTR/ATR副本)中的分区。
要截断一个分区,可以通过其逻辑分区id标识该分区,这可以在TABLE_PARTITIONS视图的PART_ID列中找到。下面的例子说明了这一点:
例子
创建包含分区和子分区的表T1:
CREATE COLUMN TABLE T1 (A INT,B INT)
PARTITION BY RANGE (A) ((PARTITION 1 <= VALUES < 5, PARTITION 5 <= VALUES < 20, PARTITION OTHERS)
SUBPARTITION BY RANGE (B) (PARTITION 1 <= VALUES < 100, PARTITION 100 <= VALUES < 200));
查询逻辑分区id:
select * from TABLE_PARTITIONS where table_name='T1';
查找逻辑分区id:你可以截断一个选定的分区:
TRUNCATE TABLE T1 PARTITION (4);
在本例中,分区4对应范围(A)[5..20]范围(B)[100..200]。
范围分区:更多选项
范围分区有一些特殊的特性:添加额外的范围、删除范围和使用动态的“其他”分区。
范围分区的显式分区处理
对于所有涉及范围的分区规范,可以根据需要添加和删除额外的范围。这意味着将根据使用的范围的需要创建和删除分区。在多级分区的情况下,所需的操作应用于所有相关节点。
请注意
如果创建了一个分区,并且存在其他分区,则将其他分区中与新添加的范围匹配的行移动到新分区。如果其他分区较大,此操作可能耗时较长。如果其他分区不存在,则此操作速度很快,因为只会向编目中添加一个新分区。
无论是否存在其他分区,范围分区至少需要指定一个范围。删除分区时,即使存在其他分区,也不能删除最后创建的分区。
对于range-range分区,您必须通过指定分区列来指定是在第一级还是第二级添加或删除分区。
注意
DROP PARTITION命令用来删除数据。它不会将数据移动到其他分区。
-- Changing a Table to Add/Drop Partitions
ALTER TABLE MY_TABLE ADD PARTITION 100 <= VALUES < 200
ALTER TABLE MY_TABLE DROP PARTITION 100 <= VALUES < 200
-- Changing a Table to Add/Drop an Others Partition
ALTER TABLE MY_TABLE ADD PARTITION OTHERS
ALTER TABLE MY_TABLE DROP PARTITION OTHERS
您可以向第一级和第二级分别添加一个范围,如下所示;
CREATE COLUMN TABLE MY_TABLE (a INT, b INT)
PARTITION BY
RANGE (a) (PARTITION 1 <= VALUES < 5),
RANGE (b) (PARTITION 100 <= VALUES < 500)
ALTER TABLE MY_TABLE ADD PARTITION (a) 5 <= VALUES < 10
ALTER TABLE MY_TABLE ADD PARTITION (b) 500 <= VALUES < 1000
ALTER TABLE MY_TABLE DROP PARTITION (a) 5 <= VALUES < 10
ALTER TABLE MY_TABLE DROP PARTITION (b) 500 <= VALUES < 1000
动态范围分区
动态范围分区可用于支持“其他”分区的自动维护。
当您创建OTHERS分区时,随着时间的推移,它可能会溢出并需要进一步维护。使用动态范围特性,others分区由后台作业监视,当它达到预定义的大小阈值时,将自动分割为额外的范围分区。后台作业还检查空分区,如果发现范围分区为空,则自动删除该分区(其他分区永远不会自动删除)。
设置动态范围分区的行数阈值有三种可能的方法:
使用CREATE和ALTER SQL语句的PARTITION OTHERS语法;在本例中,值保存在表元数据中。下面给出了一些示例语句,详细信息请参阅SAP HANA SQL参考指南。
使用TABLE_PLACEMENT表的DYNAMIC_RANGE_THRESHOLD字段,该字段也会触发动态分区(参见表放置规则)。
第三种选择是将阈值定义为系统配置参数(请参阅下面的配置)。
通过在创建分区时在命令中包含dynamic关键字,可以使用动态others分区创建分区,可以使用THRESHOLD值创建数值分区,也可以使用INTERVAL值创建基于时间的分区(请参阅下面的示例和场景)。分区既可以是单级RANGE分区,也可以是二级RANGE分区,动态范围既可以用于均衡分区,也可以用于异构分区。
使用INTERVAL选项有两种测量时间的方法:要么作为时间值(使用DATE、TIMESTAMP、SECONDDATE等数据类型——参见下面第二个示例),要么因为时间间隔并不总是等距离的(例如,一个月可能有28到31天),所以支持使用数字计数器的选项(使用INT、BIGINT、NVARCHAR等数据类型——参见下面第三和第四个示例)。
SQL示例
这里给出了一些基本示例,有关分区子句的详细信息,请参阅SAP HANA平台的SAP HANA SQL参考指南。下面的例子创建了一个表T,并将其与一个动态的others分区进行分区:
例子
1)本例使用可选关键字DYNAMIC和
CREATE COLUMN TABLE T (A NVARCHAR(5) NOT NULL, NUM INTEGER NOT NULL)
PARTITION BY RANGE (A AS INT) (PARTITION OTHERS DYNAMIC THRESHOLD 3000000)
2)在下面的示例表T中,有一列用于记录时间值。它使用可选关键字DYNAMIC和
CREATE COLUMN TABLE T (A SECONDDATE NOT NULL)
PARTITION BY RANGE(MONTH(A)) (PARTITION VALUE = '2020-01', PARTITION OTHERS DYNAMIC INTERVAL 3 MONTH);
3)下面的示例对表T进行分区,并对OTHERS分区应用数值动态间隔。在这种情况下,您使用INTERVAL关键字而不带类型值,然后将间隔值(100)解释为数值时间单位:
CREATE COLUMN TABLE T (A INT NOT NULL, B INT)
PARTITION BY RANGE(A) (PARTITION 0 <= VALUES < 1000, PARTITION OTHERS DYNAMIC INTERVAL 100);
4)使用ALTER PARTITION为分区2设置数值时间间隔,示例如下:
ALTER TABLE T ALTER PARTITION 2 DYNAMIC INTERVAL 100;
下面给出了使用ALTER TABLE的更多示例:
例子
第一个例子重新定义了others分区(均衡分区)的阈值:
ALTER TABLE T PARTITION OTHERS DYNAMIC THRESHOLD 1000000;
在异构分区场景中,使用ALTER PARTITION语法来指定分区ID:
ALTER TABLE T ALTER PARTITION OTHERS DYNAMIC THRESHOLD 1000000;
ALTER TABLE T ALTER PARTITION OTHERS DYNAMIC INTERVAL 2 YEAR;
这个命令关闭动态范围分区:
ALTER TABLE T PARTITION OTHERS NO DYNAMIC;
在异构分区场景下关闭动态范围分区需要ALTER PARTITION命令:
ALTER TABLE T ALTER PARTITION OTHERS NO DYNAMIC;
数据类型和验证
并不是所有的数据类型都适合动态分区,范围分区列必须是一个不可空的列,并且必须是一个持续递增的数字序列,比如时间戳或整数。支持以下类型:
| Datetime Types | DATE, SECONDDATE, TIMESTAMP |
|---|---|
| Numeric Types | TINYINT, SMALLINT, INTEGER, BIGINT |
| Character String Types | VARCHAR, NVARCHAR |
| Text Types | SHORTTEXT |
如果是interval属性, 会支持下述列类型:
| Datetime Types | DATE, SECONDDATE, TIMESTAMPFor these types the interval unit (MONTH, YEAR) must be specified as shown in the examples above. |
|---|---|
| Numeric Types | TINYINT, SMALLINT, INTEGER, BIGINT |
| Character String Types | NVARCHAR Here, only the digits 0-9 should be used. In this case string data representing up to 19 digits is interpreted as BIGINT. |
负数
对于一般的范围分区和动态范围分区,数字数据类型支持正数和负数。在这种情况下适用的限制是,当创建新的动态分区时,只能添加大于OTHERS分区下界的值(也就是说,只能为大于正方向的值创建新分区)。下面的示例分区规范和注释显示了这一点:
| Partition Specification | Handling of OTHERS partition |
|---|---|
| partition -200 <= values < -100 | 该规范定义了一个有界分区,它接受-200到-100之间的值。数字-99不在分区范围内,但可以成功添加到OTHERS分区。可以为大于正方向的数字创建一个新的动态分区。数字-201也在分区范围之外。它可以成功地添加到OTHERS分区中,但是,不能为负方向上较低的数字创建新的动态分区。在这种情况下,ALTER TABLE命令ADD PARTITION FROM OTHERS将产生一个错误:' OTHERS分区中的最小值小于新范围的最小可能下界' |
| partition values >= -100, partition values < -500 | 该规范为负数定义了两个未绑定分区,但不受支持:第一个分区用于大于-100的所有值。第二个分区用于所有小于-500的值。在这种情况下,一个OTHERS分区是不可能的,并且带有partition OTHERS Dynamic的partition BY语句会产生一个错误:'Feature not supported: Dynamic Range OTHERS partition应该包含正无穷大'。 |
阈值和处理
具有动态others分区的表由一个可配置的后台作业监视,该作业将检查分区的当前大小与定义的限制进行比较,并根据需要进行调整。如果OTHERS分区超过了定义的限制,那么作业运行时OTHERS分区中的所有记录都被添加到新分区中,对应的SQL语句是ADD partition FROM OTHERS。
在此过程中,使用THRESHOLD属性也会删除空分区。使用INTERVAL属性必须使用DROP empty partitions语句手动删除空分区。有关所采取的操作的详细信息,请参阅下面的场景,并参考SAP HANA Database SQL参考指南中的Alter Partition Clauses章节了解更多详细信息。
后台作业以预定义的间隔运行,并在上面给出的选项序列中搜索一个阈值,从表元数据开始。类似地,如果SQL命令中没有指定阈值,则动态分区的ALTER TABLE指令将应用首先找到的阈值。
配置
在indexserver.ini文件的[partitioning]部分,可以使用以下配置参数进行动态分区:
Dynamic_range_default_threshold—输入您需要的值,默认值是10,000,000行。如果没有指定其他值,则使用此参数值。
Dynamic_range_check_time_interval_sec—后台作业以预定义的时间间隔运行。默认值是900,但如果需要,可以在这里更改。您可以将值设置为0以停用后台作业(值设置为- 1具有相同的效果)。
使用Interval进行动态范围分区的场景
在下面的场景中,表T根据年份进行分区,第一个分区定义为2020年。定义一个动态OTHERS分区,时间间隔为2年:
CREATE COLUMN TABLE T (A SECONDDATE NOT NULL) PARTITION BY RANGE(YEAR(A)) (
PARTITION VALUE = '2020',
PARTITION OTHERS DYNAMIC INTERVAL 2 YEAR);
使用2023年1月的数据记录更新表,这些记录最初被添加到表的OTHERS分区中。在正常使用中,表由后台作业检查,但这也可以根据需要手动完成:
ALTER TABLE T ADD PARTITION FROM OTHERS
在进行动态重分区时,根据定义的间隔在需要的地方创建新分区以容纳数据。分区可能是空的,但是创建分区是为了完成这个序列。在本例中,将创建一个空分区'2021 <=2023',并将2023的新数据添加到'2023 <=2025'分区中。将OTHERS分区中的任何现有数据移动到适当的分区,并创建新的OTHERS分区。
动态重分区还可以在删除分区时调整数据的分区。但是,在使用INTERVAL值进行动态分区的情况下,后台作业不会这样做,必须使用以下语句手动完成:
ALTER TABLE T DROP EMPTY PARTITIONS;
在这个场景中(假设这些分区仍然没有数据),范围'2020'和'2021 <=2023'的分区1和2与范围'2023 <=2025'合并。然后删除空分区,然后将剩余分区重命名为'2020 <=2025'。
分区操作
如何对表进行分区可以在创建时确定,也可以在稍后的时间点确定。您可以通过几种方式更改表的分区方式。
您可以通过以下方式更改分区:
对未分区的表进行分区
通过合并分区表的所有分区,将分区表更改为非分区表
重新分区一个已经分区的表,例如:
更改分区规范,例如,从散列改为轮循
更改分区列
增加或减少分区的数量
请注意
当更改表的分区时,受影响表的表创建时间将更新为执行该操作的时间。
请注意
当您使用ALTER table命令修改分区表的属性时,您可以指定一个分区ID值列表,然后用一条语句修改所有这些值。例如,下面的命令为分区17和分区18设置page loadable属性:
ALTER TABLE T1 ALTER PARTITION (17 18) PAGE LOADABLE;
此选项可用于INSERT ON/OFF、COLUMN/PAGE LOADABLE和NUMA NODE属性。只有在语句没有错误地完成时才应用修改。如果发生错误,则不修改分区。完整的语法细节请参见《SAP HANA SQL参考指南》中的异构Alter Partition子句。
优化
在表上执行分区操作可能代价高昂,原因如下:
这需要很长时间来运行,大表需要几个小时。
它具有相对较高的内存消耗。
它将所有内容写入日志(备份和恢复所必需的)。
重新分区操作是一个非阻塞过程。除了准备分区过程开始时的一小段时间外,它不需要对数据库设置排他锁。这意味着您可以在重新分区运行时执行SQL DML命令,但是,DDL操作(例如创建或删除表操作)仍然被阻塞。在分区过程结束时,再次需要一个排他锁来对增量内容应用重分区。
建议
在插入大量数据之前或在数据还很小的时候(重新)分区表。如果一个表没有分区,并且它的大小达到了可配置的绝对阈值,或者如果一个表每天增长一定的百分比,系统就会发出警报。
虽然手动(重新)划分表和合并分区是可能的,但是在某些情况下,使用Table Redistribution操作来优化表分区可能更有效(例如,如果不需要更改分区规范)。再分配操作使用复杂的算法来评估当前的分布,并根据情况确定更好的分布。
在特定位置创建分区
在对表进行分区时,可以使用at location子句指定应该在哪个位置(索引服务器)创建分区,如下面的示例所示。注意,这可以用于所有分区类型:哈希、轮询和范围。
在第一个示例中,要创建的分区的具体数量为(3),并在三个主机的location子句中给出相应的列表(名称和端口号),以便在每个主机上创建一个分区:
CREATE COLUMN TABLE MY_TABLE (a INT, b INT, c INT) PARTITION BY HASH (a, b)
PARTITIONS 3 AT LOCATION 'myHost01:30001', 'myHost02:30003', 'myHost03:30003';
如果分区数量与主机数量不匹配,则自动应用最佳匹配:如果命名的位置太多,则忽略额外的位置;如果分区多于位置,则以轮询方式重用位置。如果没有指定位置,那么分区将自动随机分配给主机。
在第二个例子中,分区的数量是从GET_NUM_SERVERS()函数返回的:
CREATE COLUMN TABLE MY_TABLE (a INT, b INT, c INT) PARTITION BY HASH (a, b)
PARTITIONS GET_NUM_SERVERS() AT LOCATION 'myHost01:30001';
类似地,在这种情况下,如果分区数量与主机数量不匹配,则会自动应用最佳匹配。注意,GET_NUM_SERVERS()返回的服务器数量基于表放置规则,忽略AT LOCATION子句指定的服务器数量。
重新分区时指定位置
在使用ALTER table和带AT LOCATION子句的PARTITION BY对表进行重分区时,可以指定位置。如果分区位置是在表最初分区时定义的,则可以保留这些位置或覆盖它们(请参阅以下小节中的示例)。该选项支持范围分区,但不能用于大对象(BLOB、NCLOB)或地理空间信息(ST_POINT、ST_GEOMETRY)。ONLINE重分区不支持该特性。
本节给出了可用选项的示例和注释。
示例:一个表初始分区位于host1上:
CREATE TABLE T(A INTEGER) PARTITION BY RANGE(A) ((PARTITION 1 <= VALUES < 200 AT LOCATION 'host1:30003'));
在处理完表之后,它被重新分区为两个特定主机上的分区:
ALTER TABLE T PARTITION BY RANGEA(A)
((PARTITION 1 <= VALUES < 100 AT LOCATION 'host2:30003', PARTITION 100 <= VALUES < 200 AT LOCATION 'host1:30003'));
当重新分区时,源分区的位置将尽可能保留,但如果这是不可能的,或者如果位置有任何歧义,则应用以下规则(参见以下示例):
使用第一个源分区的位置(按逻辑分区id排序)
对于新分区(其中没有源分区),将使用表的可能表位置的第一个条目
在下面的示例中,在指定的主机上创建了两个分区:
CREATE TABLE T (A INTEGER) PARTITION BY RANGEA(A)
((PARTITION 1 <= VALUES < 100 AT LOCATION 'host2:30003', PARTITION 100 <= VALUES < 200 AT LOCATION 'host1:30003'));
然后将两个分区组合在一起,而不指定位置。因此,分区被放置在第一个可用的位置:host2。
ALTER TABLE PARTITION BY RANGE(A) ((PARTITION 1 <= VALUES < 200));
指定新位置
在以下场景中,创建了一个包含单个分区的表,但没有指定位置:
CREATE TABLE T1 (C1 INT, C2 INT) PARTITION BY RANGE (C1) (
(PARTITION 1 <= VALUES < 100));
如果对这个表进行重分区,可以使用AT location对每个分区定义指定单个子分区的位置,如下所示:
ALTER TABLE T1 PARTITION BY RANGE (C1) (
(PARTITION 1 <= VALUES < 50,
PARTITION 50 <= VALUES < 100 AT LOCATION 'host1:30001'));
在本例中,在指定位置host 1上创建第二个子分区。
你也可以通过在父级定义位置来为所有子分区指定相同的位置:
ALTER TABLE T1 PARTITION BY RANGE (C1) (
(PARTITION 1 <= VALUES < 50 AT LOCATION 'host3:30003')
SUBPARTITION BY RANGE(C2) (PARTITION 10 <= VALUES < 50,
PARTITION 50 <= VALUES < 100,
PARTITION 300 <= VALUES < 350));
在本例中,所有三个子分区都是在指定位置(host 3)上创建的。
保留或覆盖现有位置
如果表在特定位置已经有分区,那么可以保留这些分区,将分区移动到新位置,或者在新位置创建新分区。下面的示例显示了这一点。
创建了一个表,在host1上有一个子分区,在host2上有一个一级分区。
CREATE TABLE T1 (C1 INT, C2 INT) PARTITION BY RANGE (C1) (
(PARTITION 1 <= VALUES < 50)
SUBPARTITION BY RANGE(C2) (PARTITION 10 <= VALUES < 90 AT LOCATION 'host1:30001'),
(partition value = 50 AT LOCATION 'host2:30002'));
下面的命令重新分区表,在父级和子分区级指定新的位置:
ALTER TABLE T1 PARTITION BY PARTITION BY RANGE (C1) (
(PARTITION 1 <= VALUES < 50 AT LOCATION 'host3:30003’)
SUBPARTITION BY RANGE(C2) (PARTITION 10 <= VALUES < 50 AT LOCATION 'host4:30004’,
PARTITION 50 <= VALUES < 100,
PARTITION 300 <= VALUES < 350),
(partition value = 50));
这样做的影响是:
子分区1是在位置host 4上创建的,这是专门为这个分区定义的。
按照原始表定义中的指定,在位置host 1上创建子分区2。这是因为没有为这个分区定义特定的新位置,但是它的数据与现有的范围定义相交。在这种情况下,保留现有位置。
在位置host 3上创建子分区3。这个分区的数据范围与现有的分区模式没有交集,因此可以应用父级给出的定义。
主机2上的1级分区不受影响。
跟踪分区操作
它维护了分区操作的历史记录,您可以查看它。
所有分区操作的详细信息都存储在数据库中,可以从监视视图SYS.M_TABLE_PARTITION_OPERATIONS中查询。您可以使用它来查看哪些表已被分区,操作何时发生以及由谁执行。例如,您可以使用它来检查数据建模策略的有效性,或者检查由系统自动执行的操作。
跟踪数据最初存储在内存中的环形缓冲区中。缓冲区的大小是固定的,一旦缓冲区满了,就从最老的记录开始覆盖数据。但是,缓冲区会定期将数据刷新到磁盘,并将数据永久保存在跟踪文件中。Trace文件保存在执行分区操作的indexserver上,文件名格式如下(其中ID号为文件计数器值):indexserver_
当您查询系统视图时,该工具默认使用内存模式,也就是说,只搜索内存缓冲区,这提供了最佳性能。如果需要查询旧的数据,可以设置一个配置参数(参见use_in_memory_tracing)来查询跟踪文件。
具有SYSTEM权限的用户可以查询视图中的所有记录,但是其他用户只能检索他们自己的操作记录的详细信息,也就是说,他们自己调用操作的位置,或者他们是目标表的所有者的位置。
还可以使用SQL语句完全清除系统中的所有跟踪信息。删除所有分区操作跟踪文件,清空内存缓冲区。
ALTER SYSTEM CLEAR TRACES ('TABLE PARTITION OPERATIONS');
配置选项
管理分区操作跟踪的配置参数在indexserver.ini文件的table_partition_operation_trace部分中可用:
| Parameter | Description | Default value |
|---|---|---|
| enable | 可以使用该参数启用或禁用该特性。默认为启用状态。 | TRUE |
| use_in_memory_tracing | 如果为TRUE,则在查询系统视图时只搜索内存缓冲区。将该参数设置为FALSE表示搜索跟踪文件。 | TRUE |
| maxfiles | The number of files saved. | 5 |
| maxfilesize | The maximum file size in MB. | 10 |
| trace_flush_interval | 间隔是基于写入缓冲区的操作项的数量。默认设置为10,这样每当将第10项写入缓冲区时,缓冲区就会刷新,并将所有10项写入磁盘。 | 10 |
查询视图M_TABLE_PARTITION_OPERATIONS
视图M_TABLE_PARTITION_OPERATIONS中可用的列如下表所示。
SELECT * FROM SYS.M_TABLE_PARTITION_OPERATIONS;
| Column name | Description |
|---|---|
| START_TIME | Statement start time |
| DURATION | Statement duration in microseconds |
| SCHEMA_NAME | Schema name |
| TABLE_NAME | Table name |
| USER_NAME | User name |
| STATEMENT_HASH | Unique identifier for a statement string |
| STATEMENT_STRING | Statement string. All partition operation statements on column store tables are monitored. |
| PARTITION_DEFINITION | Partition definition after executing the statement |
| OPERATION_TYPE | Operation type, for example: ADD PARTITION DROP PARTITION ALTER TABLE PARTITION BY MOVE PARTITION ENABLE DYNAMIC RANGE DISABLE DYNAMIC RANGE ALTER PARTITION PROPERTY MERGE PARTITIONS |
| IS_ONLINE | TRUE - online operation, FALSE - regular operation. |
| APPLICATION_SOURCE | Application source information |
| APPLICATION_NAME | Name of the application |
| APPLICATION_USER_NAME | Application user name |
| CLIENT_IP | IP of client machine |
在线模式下的分区操作
在移动表和分区以及重新分区时使用ONLINE模式,以减少表被锁定的时间。
在线移动分区
MOVE PARTITION子句可与SQL ALTER TABLE命令一起使用,并支持“在线”操作模式。在移动分区时,不可避免地会有一段时间表被锁定,用户无法向表写入新数据。如果在在线模式下执行move操作(支持通过RANGE或HASH分区的表),那么表及其分区被锁定的时间就会最小化。这是通过使用异步表复制来复制数据来实现的,这种复制只需要在进程开始和结束的很短时间内对表使用排他锁。在表被锁定和数据复制期间,所有提交的DML语句(插入、删除、更新等)都会被记录下来。当复制操作完成时,新的副本将成为新的目标,旧的表或分区将被删除,并重放日志以更新表。
通过轮循分区的表也可以被移动,但是在这种情况下,表在移动操作期间需要一个排他锁,并且在任何一条语句中只能移动一个表或分区。
ALTER TABLE T_ROUNDROBIN_1 MOVE PARTITION 1 TO 'host1:port2';
范围
在线操作模式可用于将一个或多个分区并行移动到一个或多个选定位置。异构(平衡)和非异构分区都支持这一点。
在线移动只能用于没有副本的表。许多复制限制也适用于此特性(例如,不支持某些表类型,如历史表、多存储表等)。完整的限制列表见“表复制限制”主题。
例子
下面的例子说明了在线移动操作的用法。
1)在线移动一张表
创建表T1,并使用online选项将表移动到不同的主机上:
CREATE COLUMN TABLE T1(A INT PRIMARY KEY, B INT) AT 'MyHost16:30003';
ALTER TABLE T1 MOVE TO 'MyHost17:30003' ONLINE;
2)移动分区
创建表T2,并使用HASH分区创建三个分区:
CREATE COLUMN TABLE T2(A INT PRIMARY KEY, B INT) PARTITION BY HASH(A) PARTITIONS 3 AT 'MyHost16:30003';
将一个分区移动到新主机:
ALTER TABLE T2 MOVE PARTITION 2 TO 'MyHost17:30003' ONLINE;
将一个分区移动到新主机:
3)从HASH重新分区到RANGE
具有三个HASH分区的表T2也可以使用在线模式下的ALTER table进行重新分区。下面的例子使用RANGE分区对表进行重分区:
ALTER TABLE T2 PARTITION BY RANGE(A) (PARTITION 0 <= VALUES < 5, PARTITION 5 <= VALUES < 20, PARTITION OTHERS) ONLINE;
4)这个和下面的例子说明了移动多个分区。创建表T3并使用HASH分区创建5个分区:
CREATE COLUMN TABLE T3(A INT) AT 'MyHost190:34203';
ALTER TABLE T3 PARTITION BY HASH(A) PARTITIONS 5;
5)将多个分区移动到一个或多个主机:
ALTER TABLE T3 MOVE PARTITION 1,2,3 TO 'MyHost190:34240’ ONLINE;
ALTER TABLE T3 MOVE PARTITION 1,2 TO 'MyHost190:34240', PARTITION 3,4 TO 'selibm190:34242’ ONLINE;
6)这个例子说明了在多级场景中移动分区:
CREATE COLUMN TABLE T4(A INT, B INT) PARTITION BY HASH(A) PARTITIONS 4, HASH(B) PARTITIONS 2 AT LOCATION 'MyHost41:34403';
ALTER TABLE T4 MOVE PARTITION 2 TO 'MyHost41:34440’, PARTITION 3,4 TO 'seltera41:34443’ ONLINE;
在线异构重分区
应用异构两级分区模式的重分区也可以在“在线”操作模式下完成,以减少表被锁定的时间。这可以用于范围-范围和范围-哈希分区(参见异构重分区了解更多细节)。在此操作期间,为表定义的任何属性设置(包括负载单位值)都会被保留(属性可以在PARTITIONED_TABLES系统视图中看到)。您可以在M_JOB_PROGRESS视图中看到该操作的进度,JOB_NAME的值被设置为'Online Repartitioning'。
在线异构重分区只能用于没有副本的表。许多复制限制也适用于此特性(例如,不支持某些表类型,如历史表、多存储表等)。完整的限制列表见“表复制限制”主题。
例子
下面的示例说明了这一点,首先创建一个表,然后应用一个异构的range-range模式。关键字online用于语句的末尾。
create column table SRC(n int, c char);
alter table SRC partition by range(n) (
(partition value = 1, partition value = 2) subpartition by range(c) (partition value = 'A', partition value = 'B'),
(partition value = 3) subpartition by range(c) (partition value = 'E', partition value = 'F'),
(partition value = 4) subpartition by range(c) (partition value = 'G', partition others)) online;
注意,非异构重分区的“online”选项也是可用的。SAP HANA平台的SAP HANA SQL参考指南中的“非异构Alter Partition子句”一节给出了相关的SQL语法细节。
时间选择分区(老化)
SAP HANA数据库提供了一种特殊的时间选择分区方案,也称为老化。时间选择或老化允许SAP Business Suite应用程序数据水平划分为不同的温度,如冷热。
SAP Business Suite ABAP应用程序可以使用老化(不能用于客户或合作伙伴应用程序),通过使用时间选择分区将热(当前)数据与冷(旧)数据分开,以便:
创建分区和重新分区
添加分区
为分区分配行
设置DML (Data Manipulation Language)和DQL (Data Query Language)语句的作用域。
设置DML和DQL范围是时间选择分区中最重要的方面。它使用一个日期来控制在SELECT、CALL、UPDATE、UPSERT和DELETE期间要考虑多少分区。这个日期可以由应用程序用语法子句提供,它限制了考虑的分区的数量。
例如,可以发出一条SELECT语句,检索日期大于或等于2009年5月1日的所有数据。它还应该包括当前/热分区。另一方面,UPDATE操作也可以以同样的方式受到限制。如果提供了日期,则始终包括当前分区。
请注意
具有时间选择分区的表不能使用ALTER TABLE转换为任何其他类型的表。
冷分区的唯一约束
默认情况下,SAP HANA对所有分区强制执行唯一的约束。但是,对于冷分区,应用程序可能会主动否决这种行为。这要求应用程序自己强制冷分区的唯一性。重复的键被认为是应用程序错误。
原因是SAP Business Suite for SAP HANA中的典型OLTP工作负载是在当前/热分区上执行的,它的性能不会受到与典型OLTP处理无关的冷分区的唯一检查的影响。
如果应用程序推翻唯一性约束:
当前/热分区的一行可能与冷分区的一行冲突,
冷分区的一行可能与另一个冷分区的一行冲突,并且
冷分区中的一行可能与同一冷分区中的另一行发生冲突。
从SQL的角度来看,分区是透明的。如果表具有唯一索引或主键,并且在冷分区中具有重复项,则SELECT可能返回唯一索引或主键的重复项。从数据库的角度来看,这种行为是正确的,但这被认为是应用程序错误。数据库将返回一个未定义的结果集。如果存在重复的主键,返回正确结果集的唯一一种语句是SELECT语句,它只在完整键上使用WHERE子句选择数据(没有连接、聚合、聚合函数等,也没有复杂的WHERE条件)。如果存在重复项,则不能保证结果集具有更多的惟一约束。
分页属性
可以选择将冷分区创建为分页属性。这减少了内存消耗。常驻页的内存包含在系统视图M_CS_TABLES、M_CS_COLUMNS和M_CS_ALL_COLUMNS中。MEMORY_SIZE_IN_MAIN字段和相关统计信息包括表或列的分页内存和非分页内存。
常驻页的全局统计信息可以在M_MEMORY_OBJECT_DISPOSITIONS视图中找到。分页属性使用的页面数量和大小分别在PAGE_LOADABLE_COLUMNS_OBJECT_COUNT和PAGE_LOADABLE_COLUMNS_OBJECT_SIZE中进行跟踪。
将老化表转换为列存储表
在某些特定情况下,可以将时间选择分区表转换为列存储表。
单级老化分区表可以转换为非分区表
二级老化分区表可以转换为合并二级时间选择分区的一级分区表
可以将单级或两级老化多存储表转换为常规的列存储分区表,方法是首先将分区从扩展存储移动到列存储,然后进行转换。有关详细信息,请参阅SAP HANA动态分层文档集中的“将Multistore表转换为分区列存储表”主题。
这里给出了一些例子来说明这一点,首先展示了创建表的命令,然后修改它:
例子
1)转换单级老化表,并将分区合并为未分区的列存储表
CREATE COLUMN TABLE TAB (A INT, B INT PRIMARY KEY, _DATAAGING NVARCHAR(8)) PARTITION BY RANGE (_DATAAGING)
(USING DEFAULT STORAGE (PARTITION value = '00000000' IS CURRENT,
PARTITION '20100101' <= VALUES < '20110101', PARTITION OTHERS))
WITH PARTITIONING ON ANY COLUMNS ON
FOR NON CURRENT PARTITIONS UNIQUE CONSTRAINTS OFF
FOR DEFAULT STORAGE NON CURRENT PARTITIONS PAGE LOADABLE;
ALTER TABLE TAB MERGE PARTITIONS;
2)将两级老化分区表转换为单级列存储分区表(HASH- range to HASH)
CREATE COLUMN TABLE TAB (A INT, B INT PRIMARY KEY, _DATAAGING NVARCHAR(8)) PARTITION BY HASH(B) PARTITIONS 2, RANGE (_DATAAGING)
(USING DEFAULT STORAGE (PARTITION value = '00000000' IS CURRENT,
PARTITION '20100101' <= VALUES < '20110101', PARTITION OTHERS))
WITH PARTITIONING ON ANY COLUMNS ON
FOR NON CURRENT PARTITIONS UNIQUE CONSTRAINTS OFF
FOR DEFAULT STORAGE NON CURRENT PARTITIONS PAGE LOADABLE;
ALTER TABLE TAB PARTITION BY HASH (B) PARTITIONS 2;
注意,在本例中,分区号必须为2。
3)将两级老化分区表转换为单级列存储分区表(RANGE-RANGE to RANGE)
CREATE COLUMN TABLE TAB (A INT PRIMARY KEY, B INT, _DATAAGING NVARCHAR(8))
PARTITION BY RANGE(A) (PARTITION VALUE = 1, PARTITION 10 <= VALUES < 20, PARTITION OTHERS), RANGE (_DATAAGING)
(USING DEFAULT STORAGE (PARTITION value = '00000000' IS CURRENT,
PARTITION '20100101' <= VALUES < '20110101', PARTITION OTHERS))
WITH PARTITIONING ON ANY COLUMNS ON
FOR NON CURRENT PARTITIONS UNIQUE CONSTRAINTS OFF
FOR DEFAULT STORAGE NON CURRENT PARTITIONS PAGE LOADABLE;
ALTER TABLE TAB PARTITION BY RANGE(A) (PARTITION VALUE = 1, PARTITION 10 <= VALUES < 20, PARTITION OTHERS);
注意,在这种情况下,分区规格必须与老化表的第一级规格相同。
有关数据老化的更多信息,请参见以下SAP注释:2416490 - FAQ: SAP S/4HANA中的SAP HANA数据老化。
分区一致性检查
分区一致性检查可以对分区表进行常规和数据一致性检查,例如检查分区规范、元数据和拓扑是否正确。
对于分区表,有两种类型的一致性检查:
一般检查
检查分区规范、元数据和拓扑之间的一致性。
数据检查
执行一般检查,并检查所有行是否位于正确的部分。
要执行总检查,请执行以下语句:
CALL CHECK_TABLE_CONSISTENCY('CHECK_PARTITIONING', '<schema>', '<table>')
执行扩展数据检查,执行:
CALL CHECK_TABLE_CONSISTENCY('CHECK_PARTITIONING_DATA', '<schema>', '<table>')
如果任何测试遇到表的问题,则该语句返回包含有关错误的详细信息的行。如果结果集为空(没有返回任何行),则未检测到任何问题。
如果扩展数据检查检测到行位于不正确的部分,可以通过执行以下命令来修复:
CALL CHECK_TABLE_CONSISTENCY('REPAIR_PARTITIONING_DATA', '<schema>', '<table>')
请注意
根据数据量的不同,数据检查可能需要很长时间才能运行。
设计分区
要优化数据分区策略的设计,需要考虑许多因素,包括它将如何影响选择和插入性能,以及它将如何随着时间的推移调整数据更改。
需要测试不同的分区策略,以确定最适合您的特定场景的分区策略。根据您的测试,您应该选择能够为您的场景显示最佳性能的分区策略。这里列出的设计原则有助于您为您的场景决定正确的分区策略。
请注意
SAP HANA上的SAP Business Warehouse自己处理分区。不要干涉它的分区管理,除非SAP建议这样做。
查询性能
对于复制的维度表,数据库尝试使用事实表分区本地的副本。
分区修剪分析WHERE子句,并寻求减少分区的数量。尝试使用在WHERE子句中经常使用的分区列。这减少了运行时间和负载。
通常,散列分区是第一级的最佳分区方案,特别是在向外扩展的场景中。这是因为客户端可能已经在客户端机器上使用了修剪,并在可能的情况下将查询直接发送到保存数据的主机。这被称为“客户端语句路由”。这对于单个选择语句尤其重要。
在哈希分区中使用尽可能多的列,以实现良好的负载平衡,但尽量只使用那些通常在请求中使用的列。在最坏的情况下,只有单个选择语句可以利用修剪。
如果表彼此连接,那么如果表在相同的列上进行分区,并且具有相同数量的分区,这是有益的。通过这种方式,连接可以在向外扩展的场景中本地执行,并且减少了网络开销。
这保证了匹配的值位于具有相同部件ID的分区中。您必须将具有相同ID的所有部件放在同一台主机上。
当搜索较小的分区时,查询不一定会变得更快。查询通常使用索引,而表或分区的大小并不重要。如果搜索条件不是选择性的,那么分区大小就很重要。
数据操作语言(DML)性能
如果插入性能是您的场景的关键,那么更多的分区可能会显示更好的结果。另一方面,较高的分区数量可能会降低查询性能。
在DML操作期间使用分区剪枝。
对于复制的列存储表,所有DML操作都通过具有主分区的主机(部分ID为1的副本所在的主机)进行路由
如果在非键列上存在唯一约束,则性能将随着其他服务器上的分区数量呈指数级下降。这是因为必须检查所有分区上的惟一性。因此,如果需要分区,请考虑减少分区数量,理想情况下将所有分区放在同一台主机上。这样就减少了远程调用的数量。
数据生命周期
如果基于时间的分区适合被分区的数据集,那么应该始终使用它,因为它有许多优点:
增量合并的运行时依赖于主索引的大小。这个概念利用了这样一个事实,即新数据插入到新分区中,而旧分区中的数据很少更新。随着时间的推移,以前的新分区会变旧,并创建新的分区。不再需要旧分区上的增量合并。这样,增量合并的总运行时不会随着表大小的增加而增加,而是保持在一个恒定的水平。使用基于时间的分区通常涉及在日期列上使用范围的哈希范围分区。这需要了解范围划分的实际值。
通过使用显式分区管理,可以创建新分区(例如,每个日历周创建一个分区),并且可以完全删除旧分区,而不是删除单个行。
如果分割索引,则始终使用源部分的倍数(例如2到4个分区)。这样分割将在并行模式下执行,也不需要首先将部分移动到单个服务器。
除非必要,否则不要拆分/合并表。这些操作会将所有数据写入日志,占用大量磁盘空间。此外,这些操作需要很长时间,并且会独占地锁定表(在分区操作期间只允许进行选择)。ADD PARTITION可用于添加其他分区。如果没有'others'分区,这个调用只创建一个新的分区,这是快速的,并且在获得表的排他锁后实时发生。另一方面,如果表有others分区,则调用ADD partition会将现有的others分区拆分为新的others分区和新请求的范围。这是一项代价高昂的手术。因此,建议如果在某个场景中频繁使用ADD PARTITION,则该表不应有其他分区。
分区大小
由于在评估分区方案时需要考虑的因素很多,因此无法提供分区大小的建议。如果您不知道是否要对表进行分区,或者不知道需要多少分区,那么就从度量开始。以下是一些建议的起点:
如果一个表的行数少于5亿,不要对它进行分区,除非:
连接中对应的表是分区的。如果它们是试着找到互分割列。
表的数量增长是预期的。由于重新分区非常耗时,所以建议在表还很小的时候拆分它。
如果您的表有超过5亿行,那么每个分区选择3亿行。
请记住,一个分区不能超过20亿行。
请注意,分区数量越多可能会导致内存消耗越多,因为每个分区都有自己的独占字典,而这个字典不是共享的。如果每个分区存储析取值,这就不是问题。另一方面,如果每个分区具有相似或相同的值,这意味着字典具有冗余存储的相似数据。在这种情况下,请考虑使用更少的分区.
表设计
如果将数据复制到SAP HANA数据库中,从数据一致性的角度来看,删除主键或扩展键可能是合理的(因为在源数据库中实施了键约束)。通过这种方式,您可以拥有具有相同分区列的多个表,即使原始数据库设计不允许这样做。具有相同的分区列是理想的,因为相关数据可能驻留在同一物理主机上,因此连接操作可以在本地执行,没有或几乎没有通信成本。
在为依赖的主机设计数据库模式时,例如,为具有头节点和叶节点的业务对象设计数据库结构时,不要使用单个GUID列作为主键。在这种情况下,几乎不可能在同一主机上拥有所有相关数据(例如,业务对象实例)。一种选择可能是将GUID作为头表中的主键,并且每个主机(无论其级别如何)都可以将该GUID作为第一个主键列。
除非绝对必要,否则不要在分区表上定义唯一约束。
在第二个分区级别上,可以使用非主键列。但是,必须对各自的第一级分区的所有部分强制执行唯一约束。由于一个第一级分区的所有部分都是作为一个整体移动的,因此这种惟一的检查始终是本地的。
如果数据库表是从另一个数据库复制的,则通常建议使用others分区。如果没有定义适当的范围,则插入语句将失败,数据将无法正确复制。
理想情况下,表的主键中有一个时间条件。然后可以将其用于基于时间的分区。也可以使用数字范围等。数字范围的优点是很容易形成大小相等的分区,但另一方面,它带来了管理负担——需要密切监视加载的数据量,并且需要提前创建新的分区。对于实际日期,您只需要定期创建新分区,例如,在新季度开始之前。
其他的考虑
在脚本中使用GET_NUM_SERVERS()来获取哈希和轮询分区规范。通过这种方式,可以使用Table Placement来计算给定环境中将要使用的分区数量。
如果将来很可能需要重新拆分表并使用范围分区,则定义其他分区。(如果在表创建时没有定义它,可以在表创建后创建,如果需要,可以在拆分操作后删除)。
要检查表是否被分区,不要考虑元数据中是否存在分区规范。相反,检查M_TABLES中的IS_PARTITIONED或是否存在部分,例如M_CS_TABLES。允许定义不立即导致分区表的分区规范。
静态和动态分区修剪
提高性能的一个重要分区策略是尽可能将分区与最常查询的数据匹配起来,这样就可以进行数据修剪。
剪枝在后台自动进行,并试图从选择中消除对查询结果不重要的任何不必要的分区。如果您的分区被设计为支持这一点,那么修剪可以避免访问和加载到不需要的内存分区,从而减少系统上的总体负载。有效修剪的经典用例是使用基于日期的分区。例如,如果一个表是按年划分的,那么只会在包含所选年份数据的分区上执行仅限于单个年份数据的查询。
可能有两种形式的分区修剪:静态和动态。
静态分区修剪基于分区定义。查询优化器分析查询的WHERE子句,以确定过滤器是否与表的给定分区规范匹配。如果找到了匹配项,则可能只针对保存数据的特定分区,从而减少要查询的分区数量。
动态分区剪枝是基于内容的,适用于HANA老化表的历史分区。这种类型的修剪在运行时进行,但是要加载哪些分区的决定是基于所选列中数据的预先计算的列统计信息。基于对分区修剪有效的统计信息的存在(在处理查询时必须是最新的),查询计算可以确定是否有必要读取已分区的数据列并将其加载到内存中。
动态分区修剪的统计信息
动态分区修剪的统计信息是作为SAP HANA数据统计功能的一部分创建和维护的,并且仅在分区所在的indexserver实例中维护和使用。统计信息是通过SQL语句显式创建和刷新的(例如CREATE Statistics),要使用动态剪枝,必须首先对指定的表、分区和列运行CREATE Statistics(请参阅下面的Enabling小节)。可以使用除分区键以外的任何列。动态分区剪枝的统计信息与系统编目中的其他统计值一起持久化(这在后台异步进行),但是,剪枝统计信息值也缓存在内存中,用于剪枝过程。
用于修剪的统计信息具有有限的生命周期:随着新数据添加到列中,这些统计信息的内容变得过时。因此,有必要定期刷新修剪统计信息。这是每次delta merge运行时自动完成的,也可以按需完成(参见下面的DDL语句)。一旦将新数据添加到列中,统计信息就被认为是无效的,并且在刷新修剪统计信息之前,不再对列应用修剪。
对于历史数据分区,当前时间段内可能发生最多的插入和删除操作。旧的时间分区将更加稳定,因此,动态修剪仅应用于历史数据上基于时间的选择,而不是当前时间段。
启用动态分区修剪
静态和动态剪枝被设计为查询优化器和执行过程的组成部分。但是,目前并不是所有的查询引擎都能够充分利用动态剪剪,必须将indexserver.ini文件的query_mediator部分中的use_dynamic_pruning设置设置为True,才能为HANA OLAP引擎计划启用动态剪剪。
必须使用CREATE Statistics命令显式地为特定表创建动态分区剪枝的统计信息,如下面的示例所示(也适用于ALTER Statistics)。这将创建所有分区的统计信息:
CREATE STATISTICS test_dynPruning_tab1_col1
ON tab1 (col1)
TYPE SIMPLE VALID FOR DATA DEPENDENCY;
对于动态分区修剪,需要统计对象类型“SIMPLE”,属性设置为“VALID For DATA DEPENDENCY”,如下所示。它只适用于使用时间选择分区的分区列存储表和多存储表。统计列只支持以下数据类型:VARCHAR(具有数字内容的字符串)、INTEGER、DECIMAL、DATE。
以这种方式执行CREATE STATISTICS语句将初始化用于动态修剪的列,并填充修剪统计信息。通过增量合并重新计算剪枝统计值,或者根据需要使用显式刷新语句重新计算统计值:
REFRESH STATISTICS test_dynPruning_tab1_col1
类似地,可以使用DROP STATISTICS命令,可以以相同的方式删除表的修剪统计信息。
详细信息请参见《SAP HANA SQL和系统视图参考》。
监视视图和跟踪
关于动态分区剪枝的统计信息可以在M_DATA_STATISTICS视图中获得。
诊断信息也可用。您可以通过将part_pruning配置参数的跟踪级别(在indexserver.ini文件的跟踪部分中)设置为调试来查看修剪过程的调试细节。
有关更多信息,请参见配置跟踪。
创建有效的分区方案
这个清单演示了如何为给定的表选择一个好的分区方案。
超过5亿行的表是分区的好选择。这也适用于经常与超过5亿行的表连接的小表。
如果表有唯一索引(除了主键),则可以对表进行分区,但是额外的唯一检查会带来性能损失。
检查主键。
如果不存在,则可以使用任何列进行Hash分区。
如果存在这样的分区,请确定最小的列集,这些列需要具有均衡的分区;需要足够多的不同值。请记住,如果这些列都在查询的WHERE子句中,则可能会利用分区修剪。
对于复制到SAP HANA中的表,删除主键可能是合理的,因为它是在源数据库中检查的。
考虑经常用于与当前表连接的其他表。理想情况下,它们具有相同数量的分区和分区列。
识别基于时间的属性;这可能是一个日期、年份或至少是一个序列。将它们用于基于时间的分区。理想情况下,该列是主键的一部分。
如果定义了范围分区,请决定是否需要其他分区。理想情况下,不需要其他分区。
决定分区的数量。使用表放置规则,如果适用的话。
在横向扩展系统的情况下,将所有相应的分区移动到各自的主机。
使用最重要的查询和/或DML负载运行广泛的性能测试。尝试使用分析性观点。改变分区列、分区方案和分区数量。
分区的例子
这个示例描述了用于存储测试结果的数据库的初始和随后改进的分区模式。
假设对每个测试运行不同的测试。必须为TEST_CASE和MAKE_ID存储如此多的行。
原始表格设计
最初的表设计建议将序列号作为唯一的主键列。有时间列标记测试运行的开始和结束。
表通过序列号上的Hash和开始日期上的范围进行分区。
访问模式
访问数据的主要方式有两种:
选择制作的所有测试结果(“我的制作通过测试了吗?”)
为上个月的所有制造选择单个测试的结果(“我的测试历史如何?”以前发生过错误吗?”)
因此,通常TEST_CASE或MAKE_ID在WHERE子句中,有时在调查测试运行的细节时两者都在。
原始表设计和分区的问题
序列号通常不是WHERE子句的一部分,因此查询中会考虑所有分区。这在横向扩展环境中尤其是个问题,理想情况下,类似oltp的查询只在单个节点上执行。
在日期列上有一个带范围的哈希范围分区。这允许使用基于时间的分区。但是date列不是主键的一部分。因此,必须通过检查第一级分区的各个部分来确保主键上的唯一约束。
建议的表格设计
将TEST_CASE, MAKE_ID和SEQ_NUMBER作为主键。TEST_CASE和MAKE_ID的组合有唯一可识别的行这一实际需求得到了满足。
通过哈希范围划分,哈希范围在TEST_CASE上,范围在MAKE_ID上。MAKE_ID随着时间的推移而增加,因此也是用于基于时间的分区的好列。
原因
没有与其他分区进行主键检查(在主键列上使用range)。
良好的修剪,因为分区列匹配典型的访问模式。
如果查询在WHERE子句中具有MAKE_ID(比较查询类型1),则必须考虑包含分区的所有服务器,但每个服务器只有一个分区。
如果查询在WHERE子句中有TEST_CASE(比较类型2),则只需要考虑一个服务器(比较客户端语句路由),但是该服务器上的所有分区。
如果MAKE_ID和TEST_CASE在WHERE子句中,则只需要考虑一台服务器上的单个分区。
在这个场景中,有一种类型的查询会考虑所有保存分区的服务器。这并不理想,但根据数据和访问模式的性质,也不能总是避免这种情况。
分区的限制
这里解释了适用于分区使用的一般限制。
一般的局限性
一个表的最大分区数是16000。表可以根据需要随时重新分区。16000个分区的限制与分区在分布式(向外扩展)环境中的位置无关。
当使用等距序列和表分区时,为了有效压缩,不应该使用ROUND ROBIN分区。应该使用HASH或RANGE分区,以便具有相同系列键的记录位于相同分区中。
历史表
带有历史表的表也可以被分区。历史表总是使用与主表相同的分区类型进行分区。
20亿行屏障对历史表也是有效的,对于分区的历史表,在每个分区的基础上也是有效的。
如果表使用多级分区,则可以使用不属于主键的分区列。此功能不能与历史表结合使用。
不能复制具有历史记录的表。
分区列
在相应的小节中列出了用于散列和范围分区的分区列所支持的数据类型。
不能更改用作分区列的列的数据类型。
如果一个表有一个主键,那么如果一个列被用作分区列,就不能从主键中删除它。对于多级分区,这适用于第一级。始终可以删除整个主键。
目前,分区不支持生成的列作为分区键。
对于各种散列分区(hash、hash-hash和hash-range),分区列名不能包含逗号(",")、美元符号(" ")或圆括号("("))。</li><li>对于同质(平衡)范围分区,分区列名不能包含空格、逗号(",")、美元符号(" ")或圆括号("(")。
同样,对于同质范围分区,范围分区值不能包含逗号(",")、减号(" - ")、星号(" * ")或空格字符。
用于监控分区的系统视图
许多系统视图允许您监视分区。
| System View | Description |
|---|---|
| TABLE_PARTITIONS | 包含分区表的特定于分区的信息,包括级别1和级别2范围的详细信息。这还包括表放置分组属性GROUP NAME、GROUP TYPE、SUBTYPE。对于异构分区,显示属性NODE_ID和PARENT_NODE_ID,以便可以看到分区之间的层次关系。在这个视图中,只显示用户输入的值(不显示从父节点继承的值)。 |
| M_TABLE_PARTITIONS | 包含每个分区的列表信息。对于异构分区,显示属性NODE_ID和PARENT_NODE_ID,以便可以看到分区之间的层次关系。在此视图中显示了来自父节点的隐式继承值。 |
| PARTITIONED_TABLES | 表中所有分区的一般分区信息 |
| TABLE_COLUMNS | Contains table column information. |
| M_CS_TABLES | 显示每个分区的运行时数据(PART_ID值是分区的序号)。请注意,在分割/合并操作之后,内存大小不会被估计,因此值显示为零。需要进行增量合并来更新这些值。 |
| M_TABLES | 以聚合的方式显示分区表的行数和内存使用情况(IS_PARTITIONED设置为TRUE)。信息基于M_CS_TABLES。 |
| M_CS_PARTITIONS | 显示列存储表中的哪些分区或子分区构成一个分区组。例如,当要将分区或子分区组移动到另一台主机时,需要此信息。 |
| M_TABLE_PARTITION_STATISTICS | 显示每个分区的选择统计信息。特别是,它显示了选择分区的次数,并包括最后一次选择分区的时间戳。如果启用了indexserver.ini文件的分区部分中的配置参数partition_statistics_select_enabled,则填充此视图。 |
| M_TABLE_PRUNING_STATISTICS | 提供有关使用哪些分区以及如何应用剪枝的详细信息。默认情况下不会填充此监视视图,因为收集修剪统计信息可能会在执行语句时影响性能。可以通过将enable_pruning_statistics配置参数设置为True来启用该特性: alter system alter configuration ('global.ini', 'system') set ('partitioning', 'enable_pruning_statistics' ) = 'true' with reconfigure; |
Multistore表
多存储表是一个范围分区的SAP HANA列表,它在SAP HANA中至少有一个分区,并且在与SAP HANA关联的不同物理存储中有其他分区。
多存储功能目前是通过SAP HANA动态分层实现的,它提供扩展存储作为SAP HANA表分区的替代物理存储。与其他列式表一样,多存储表也可以进行管理和监控,但它提供了基于磁盘存储的优势,可以通过扩展存储进行数据老化。
多存储数据管理允许灵活的管理,例如:
在扩展存储或默认存储之间移动数据。
直接在扩展存储或默认存储中创建或删除分区。
如果新的分区不会在默认存储和扩展存储之间移动数据,则重新对表进行分区。
数据修改操作允许您轻松更改数据的存储类型。例如,您可以在将数据导入表时更改分区的存储类型,或者在插入操作期间修改多存储表中的数据。
请注意
多存储功能并不支持SAP HANA的所有特性。有关支持的特性的详细信息,请参见SAP HANA动态分层管理指南中的Multistore Tables。
参考
HANA managing tables至2.0SPS07 Release: https://help.sap.com/docs/SAP_HANA_PLATFORM/6b94445c94ae495c83a19646e7c3fd56/68554490aee94885ba31611489a04992.html?version=2.0.01

